归并排序
Posted wangshaowei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了归并排序相关的知识,希望对你有一定的参考价值。
1 void merge(int arr[], int l, int m,int r) 2 3 int i = 0, j = 0, k =l; 4 int n1 = m - l + 1; //左边步长 5 int n2 = r - m; //右边步长 6 std::vector<int> vec_l(&arr[l], &arr[m+1]); 7 std::vector<int> vec_r(&arr[m+1], &arr[r+1]); 8 while (i < n1&&j < n2) 9 10 if (vec_l[i] <= vec_r[j]) 11 12 arr[k] = vec_l[i]; 13 i++; 14 15 else 16 17 arr[k] = vec_r[j]; 18 j++; 19 20 k++; 21 22 while (i<n1) 23 24 arr[k]= vec_l[i]; 25 i++; 26 k++; 27 28 29 while (j<n2) 30 31 arr[k] = vec_r[j]; 32 j++; 33 k++; 34 35 36 37 38 39 void mergeSort(int arr[], int l, int r) 40 41 if (l < r) 42 43 int m = l + (r - l) / 2; 44 45 mergeSort(arr, l, m); 46 mergeSort(arr, m + 1, r); 47 48 merge(arr, l, m, r); 49 50
再贴张排序的时间与空间复杂度的图
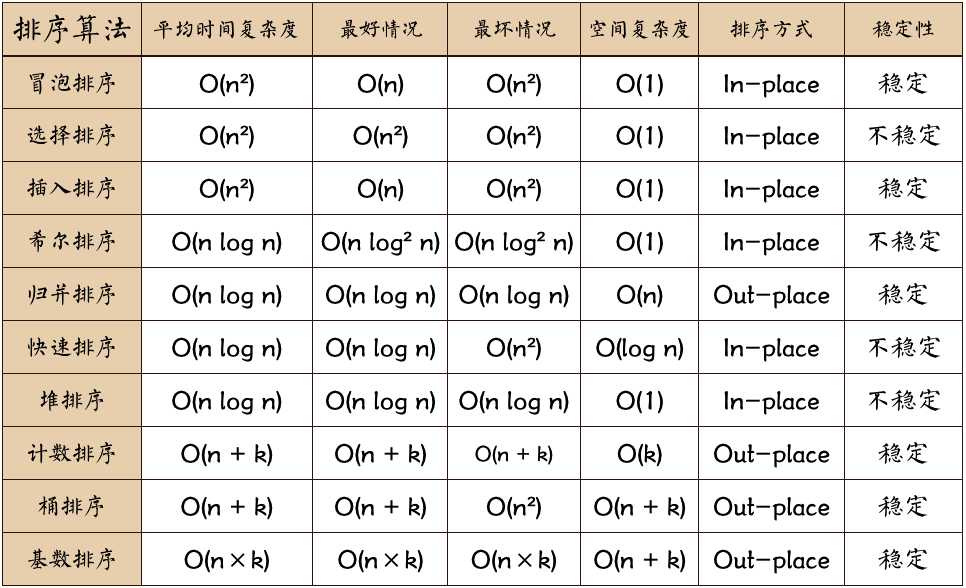
总结:
为什么堆排序的时间复杂度理想却很少被采用:
作者:qinzp
链接:https://www.zhihu.com/question/23873747/answer/327295185
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
-------------------------------------------------------------------
链接:https://www.zhihu.com/question/23873747/answer/327295185
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
-------------------------------------------------------------------
堆排序下,数据读取的开销变大。在计算机进行运算的时候,数据不一定会从内存读取出来,而是从一种叫cache的存储单位读取。原因是cache相比内存,读取速度非常快,所以cache会把一部分我们经常读取的数据暂时储存起来,以便下一次读取的时候,可以不必跑到内存去读,而是直接在cache里面找。
一般认为读取数据遵从两个原则:temporal locality,也就是不久前读取过的一个数据,在之后很可能还会被读取一遍;另一个叫spatial locality,也就是说读取一个数据,在它周围内存地址存储的数据也很有可能被读取到。因此,在读取一个单位的数据(比如1个word)之后,不光单个word会被存入cache,与之内存地址相邻的几个word,都会以一个block为单位存入cache中。另外,cache相比内存小得多,当cache满了之后,会将旧的数据剔除,将新的数据覆盖上去。
在进行堆排序的过程中,由于我们要比较一个数组前一半和后一半的数字的大小,而当数组比较长的时候,这前一半和后一半的数据相隔比较远,这就导致了经常在cache里面找不到要读取的数据,需要从内存中读出来,而当cache满了之后,以前读取的数据又要被剔除。
简而言之快排和堆排读取arr[i]这个元素的平均时间是不一样的。
一般认为读取数据遵从两个原则:temporal locality,也就是不久前读取过的一个数据,在之后很可能还会被读取一遍;另一个叫spatial locality,也就是说读取一个数据,在它周围内存地址存储的数据也很有可能被读取到。因此,在读取一个单位的数据(比如1个word)之后,不光单个word会被存入cache,与之内存地址相邻的几个word,都会以一个block为单位存入cache中。另外,cache相比内存小得多,当cache满了之后,会将旧的数据剔除,将新的数据覆盖上去。
在进行堆排序的过程中,由于我们要比较一个数组前一半和后一半的数字的大小,而当数组比较长的时候,这前一半和后一半的数据相隔比较远,这就导致了经常在cache里面找不到要读取的数据,需要从内存中读出来,而当cache满了之后,以前读取的数据又要被剔除。
简而言之快排和堆排读取arr[i]这个元素的平均时间是不一样的。
----------------------------------------------------------------------
快速排序最优的情况就是每一次取到的元素都刚好平分整个数组,最优的情况下时间复杂度为:O( nlogn )
最差的情况就是每一次取到的元素就是数组中最小/最大的,这种情况其实就是冒泡排序了(每一次都排好一个元素的顺序),快速排序最差的情况下时间复杂度为:O( n^2 )
最优的情况下空间复杂度为:O(logn) ;每一次都平分数组的情况
最差的情况下空间复杂度为:O( n ) ;退化为冒泡排序的情况(用来存储哨兵变量的临时值)
----------------------------------------------------------------------------
快排数据越无序越快(加入随机化后基本不会退化),平均常数最小,不需要额外空间,不稳定排序。
归排速度稳定,常数比快排略大,需要额外空间(还有个东西叫多路归并),稳定排序。(归并排序需要额外空间记录子数组的值)
------------------------------------------------------------------------
实际问题中归并排序并不比快排应用少。快排需要递归,就这一点基就可以在许多大数据应用场景把它枪毙了。而归并排序的scale能力比快排好很多,可以分布式处理,其实很受欢迎的
以上是关于归并排序的主要内容,如果未能解决你的问题,请参考以下文章