linux的fork函数
Posted 郭传瑞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了linux的fork函数相关的知识,希望对你有一定的参考价值。
fork函数
头文件:#include<unistd.h>
函数原型:pid_t fork( void);(pid_t 是一个宏定义,其实质是int 被定义在#include<sys/types.h>中)
返回值: 若成功调用一次则返回两个值,子进程返回0,父进程返回子进程ID;否则,出错返回-1
函数说明:一个现有进程可以调用fork函数创建一个新进程。由fork创建的新进程被称为子进程(child process)。fork函数被调用一次但返回两次。两次返回的唯一区别是子进程中返回0值而父进程中返回子进程ID。子进程是父进程的副本,它将获得父进程数据空间、堆、栈等资源的副本。注意,子进程持有的是上述存储空间的“副本”,这意味着父子进程间不共享这些存储空间。LINUX将复制父进程的地址空间内容给子进程,因此,子进程有了独立的地址空间。创建新进程成功后,系统中出现两个基本完全相同的进程,这两个进程执行没有固定的先后顺序,哪个进程先执行要看系统的进程调度策略。
举个例子:
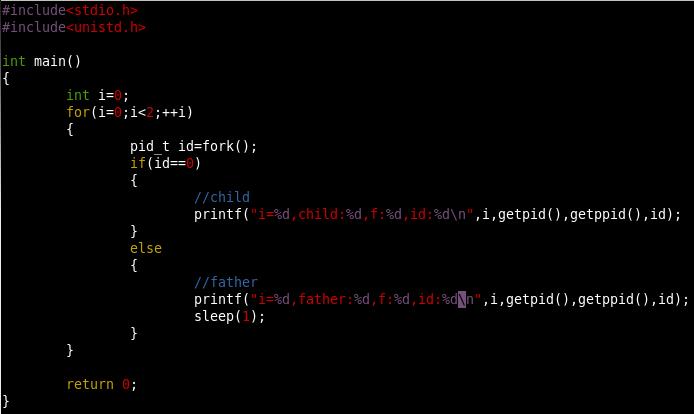
运行结果:
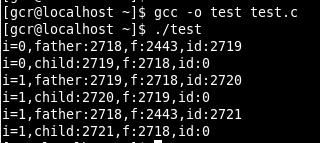
分析:
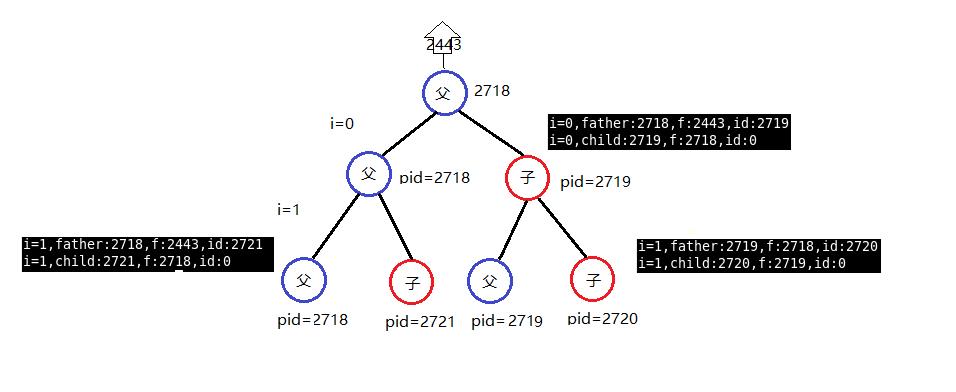
fork函数小结:
1.调用一次,返回两次。
2.子进程中fork返回0,父进程中fork返回子进程的PID。
原因是:①在子进程中通过调用getppid可以方便的指导父进程的PID;
②没有一个函数可以使父进程获得其所有子进程的PID。(所以在fork返回时,将子进程的PID直接返回给父进程)
注:子进程的ID不可能为0,因为PID为0的进程是swapper进程。
3.父、子进程共享正文段,不共享数据、堆、栈段,子进程获得父进程数据、堆、栈段的副本。
注:目前,大多数实现并直接复制父进程的数据、堆栈段,而是使用写时复制(Copy-On-Write)技术,在修改这块内存区域时,才会为被修改的数据创建副本。
4.子进程会获得缓冲区的副本,即fork前进程缓冲区中的数据未被flush掉,则fork后,子进程能够获得父进程缓冲区中的数据。
5.父进程所有被打开的文件描述符都会被复制到子进程中。
注:fork之后处理文件描述符通常有两种情况:
①父进程等待子进程结束;
②父、子进程各自执行不同的正文段(父、子进程各自关闭不需要使用的文件描述符);
6.fork之后父、子进程的区别:
①fork的返回值;
②进程ID不同;
③父进程也不同;
④子进程的tms_utime、tms_stime、tms_cutime和tms_ustime均被设置为0;
⑤父进程设置的文件锁不会被子进程继承;
⑥子进程的未处理的闹钟被清除;
⑦子进程的未处理信号集设置为空集;
7.fork失败的两个主要原因:
①系统中进程数目已经达到上限;
②该实际用户的进程总数达到系统限制;
8.fork的两种用法:
①一个进程希望复制自己,使得父、子进程执行不同的代码段。如父进程监听端口,收到消息后,fork出子进程处理消息,父进程仍然负责监听消息。
②一个进程需要执行另一个程序。如fork后执行一个shell命令。
以上是关于linux的fork函数的主要内容,如果未能解决你的问题,请参考以下文章