拉链表
Posted wqbin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了拉链表相关的知识,希望对你有一定的参考价值。
1.定义
拉链表是一种数据库设计模,用于储存历史数据和分析时间维度的数据。
所谓拉链,就是记录历史。记录一个事物从开始,一直到当前状态的所有变化的信息。
关键点:
- 储存开始时间和结束时间。
- 开始时间和结束时间首尾相接,形成链式结构。
拉链表一般用于解决历史版本查询的问题,也可用于解决数值区间问题,查询效率高,占用空间小。
如图是用户手机号拉链表:
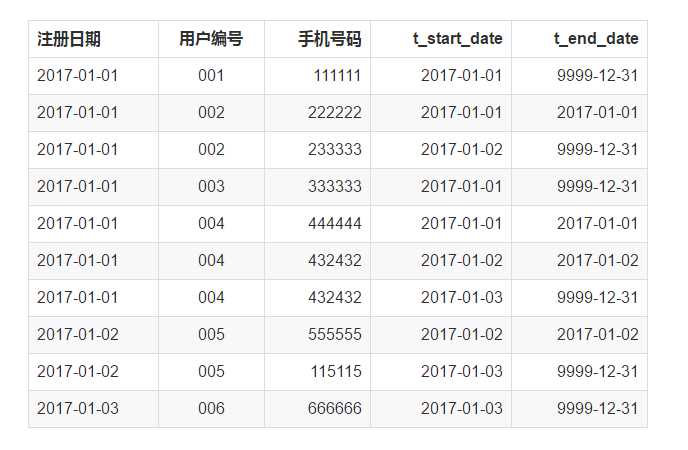
开链就是第一次插入数据,这条数据没有之前的记录与之对应,只需要设定START_DATE并将END_DATE置为很久以后(比如9999年12月31日)的日期即可。
关链就是设置整条链的结尾,将END_DATE置为一个有业务意义的日期(比如三天前或一个月后都可以)即可。
2.原因
为什么要设计拉链表?
因为要追踪数据 全量快照表空间占用大,增量表虽然小,但是无法直接在一个分区内直接看到所有的轨迹数据,同时前两者无法直接查看变化时间。
用拉链表可以做到记录变化时间也做的到一条语句直接查询,最近的轨迹,还避免全分区扫描。
SELECT * FROM LINK_TABLE WHERE USER = 1 AND ? >= START_DATE AND ? < END_DATE
3.使用场景案例
在数据仓库的数据模型设计过程中,经常会遇到下面这种表的设计:
- 有一些表的数据量很大,比如一张用户表,大约10亿条记录,50个字段,这种表,即使使用ORC压缩,单张表的存储也会超过100G,在HDFS使用双备份或者三备份的话就更大一些。
- 表中的部分字段会被update更新操作,如用户联系方式,产品的描述信息,订单的状态等等。
- 需要查看某一个时间点或者时间段的历史快照信息,比如,查看某一个订单在历史某一个时间点的状态。
- 表中的记录变化的比例和频率不是很大,比如,总共有10亿的用户,每天新增和发生变化的有200万左右,变化的比例占的很小。
4.拉链表的合并与拆分
由于某些特殊的业务需要,或为了方便查询,或因为历史遗留数据,常常造成拉链表的数据太单一或拉链表的数据太多,这时可能会需要对拉链表进行合并或拆分。
1. 合并
现在有两张表:LINK_TABLE(数据为大写字母),LINK_DEMO(数据为小写字母),现在要查ID为1数据为X和y的START_DATE和END_DATE。
我要查出所有ID的所有属性组合的起止时间。
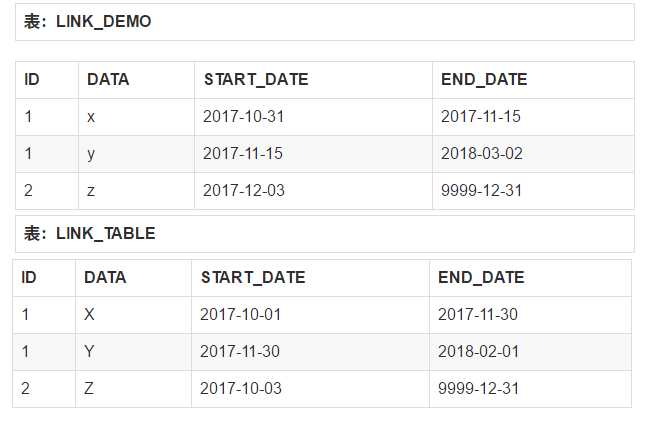
那么经过对表格的观察,我们可以画出如下的一个数轴。

最终结果应该是:
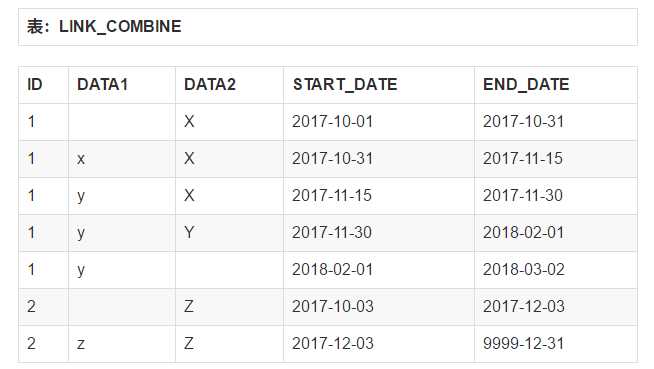
代码如下:
SELECT A.ID, A.DATA, B.DATA, CASE WHEN A.START_DATE<B.START_DATE THEN B.START_DATE ELSE A.START_DATE END, CASE WHEN A.END_DATE>B.END_DATE THEN B.END_DATE ELSE A.END_DATE END FROM LINK_DEMO A JOIN LINK_TABLE B ON A.ID=B.ID AND (A.START_DATE < B.END_DATE OR B.START_DATE < A.END_DATE);
2.拆分
拆分是合并的逆操作,就是将一个存了多个属性的拉链表拆成多个含有少量属性的拉链表。比如我们现在已经有这张LINK_COMBINE表了,我们想将它拆成LINK_DEMO和LINK_TABLE。
5.拉链表的生成
以上是关于拉链表的主要内容,如果未能解决你的问题,请参考以下文章