numpy中ndarray数据结构简介
Posted wl413911
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了numpy中ndarray数据结构简介相关的知识,希望对你有一定的参考价值。
一、综述
1、ndarray的本质是:对象
2、ndarray是numpy中的数据结构(叫做:n维数组),是同构数据多维容器,所有元素必须是相同类型
3、面向数组的编程和思维方式:用简洁的数组表达式代替循环写法,通常叫做 --‘矢量化’
二、ndarray属性:
1、ndarray.ndim:数组的维数(即数组轴的个数,也被称作为 秩 )。
2、ndarray.shape:数组的维数、维度,返回一个元组,这个元组的长度就是维度的数目,即ndim属性。比如2排3列的矩阵,其shape就是二元组(2,3)
3、ndarray.size:数组元素的总个数,等于shape属性的 元组中各元素的乘积。
4、ndarray.dtype:表示数组中元素类型的对象
5、itemsize : 数组中 每个元素 占用的 字节大小
特殊,ndarray对象可 通过 reshape() 方法,重新组织数组的维数维度(即数组的形状),其中用 -1代表自动推断某维度的维数
三、创建ndarray对象
3种方式: (1)从python的基础数据对象转化; (2)通过numpy内置函数生成 ; (3)从硬盘(文件)中直接读取
3.1 直接从list对象创建
a = np.array([1,2,3,4,5]) # array([1,2,3,4,5])
b = np.array([1,2,3,4,5],dtype=np.float) # array([1.,2.,3.,4.,5.]) 创建时直接转换数据类型
c = a.astype(np.float64) #array([1.,2.,3.,4.,5.]) 创建后,通过内置的astype() 函数,转换数据类型
3.2 通过numpy内置函数生成

3.3 从硬盘(文件)中直接读取
numpy.loadtxt()
参数:
fname :文件 或者文件路径(字符串),支持压缩的数据文件 包括gz、bz
dtype:数据类型,默认为float64(64位双精度浮点数)
comments: 字符串或 字符串组成的列表,默认为# , 是表示注释字符集开始的标志
delimiter: 字符串,用来分割多个列的分隔符,默认 为 空格
converters: 字典, 用于将特定列的数据,转换为字典中对应的函数的浮点型数据,默认为空
skiprows : 正整数n,读取时跳过前n行,默认为零
usecols : 元组(元组内数据为列的数值索引), 用来指定要读取数据的列(第一列为0),默认为空
unpack: 布尔值(True/False), 用来指定是否转置
ndmin : 整数型,值域为0、1、2,默认为0, 用于指定返回的数组至少包含特定维度的数组
numpy.savetxt()
四 、ndarray数据类型
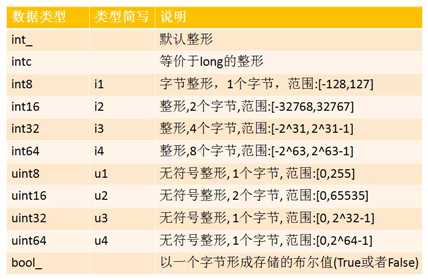
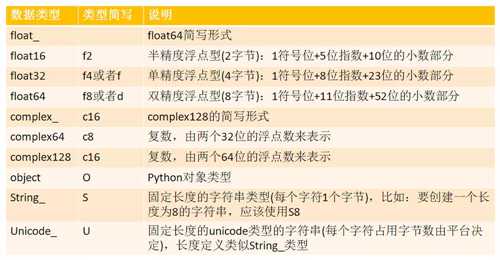
以上是关于numpy中ndarray数据结构简介的主要内容,如果未能解决你的问题,请参考以下文章