kubernetes statefulset
Posted crazymagic
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kubernetes statefulset相关的知识,希望对你有一定的参考价值。
概述
在应用程序中我们有两类,一种是有状态一种是无状态。此前一直演示的是deployment管理的应用,比如nginx或者我们自己定义的myapp它们都属于无状态应用。
而对于有状态应用,比如redis,mysql,还有etcd,还有zookeeper等等需要存数据的都属于有状态。它们不光有所谓的节点之分,每一个对应的pod还有角色之分,有的是主节点,有的是从节点。而后,从节点不光有所谓的从之分可能还有先后次序之分,我们不同的分布式系统它们的运维管理,逻辑和运维操作过程是不相同的,因此没有办法把一种控制器把每一种功能都同步进来让我们非常简单的去操作这些有状态的应用,几乎没有任何控制器能做到,后来即便有了 statefulset我们去用其实现真正功能控制时也是极其麻烦的。所以我们说statefulset即便在应用程度上能在一定程度上能实现有状态应用的管理效果,但我们需要自行把我们对某个应用的运维管理过程写成脚本注入到statefulset的应用文件中才能使用,但是稍有不慎就会有问题。好在k8s支持所谓叫做TPR,后来改成CRD了(第三方资源或自定义资源)这种机制,甚至于还支持其它更为复杂的机制比如叫api聚合,当我们使用api聚合时就需要自己去修改k8s源代码增强我们自己所需要功能,对大多数人来讲这是不可能的任务,因为它是使用GO语言开发的,所以好在k8s很有弹性支持非常灵活的扩展功能,所以我们能够实现需要自定义一些资源才能解决大多数问题,但即便如此我们想能够使用statefulset封装所有有状态应用还是一个难题,后来coreOS在此基础之上给我们提供了一个组件叫Operator,大家知道Operator就表示运维工程师的意思,所以我们可以把运维工程师的任务,做的日常操作封装在这么一个组件中就可以把Operator当运维工程师用了,能帮你运维很复杂的运维逻辑。里面主要是封装了一些自定义资源还有现有的系统上的应用资源来完成的。
StatefulSet(有状态副本集)
一般来讲,无状态的我们更关注的是群体,任何一个都可以轻易的被其它的所取代,换一个然后再新增一个,和原来一不一样都没关系。只要应用程序一样都ok,因为它没有任何数据和本地的状态,但是对有状态的应用来讲我们必须要把他们当宠物,相当于群体和个体(cattle[畜生],pet[宠物])的区别。k8s从1.3开始支持叫PetSet,就叫宠物集,在1.5的时候才改名叫StatefulSet,从名字中可以看出来他们是怎么被理解的
StatefulSet管理的应用程序,在k8s之上,StatefulSet一般要求主要用于管理拥有以下特性的应用程序
- 稳定且需要有唯一的网络标识符
- 稳定且持久的存储设备,意思是这个节点down了重新启动时确保这个节点存放的数据还在,不在的话构建起来就极其麻烦
- 有序,平滑的部署和扩展,比如redis的主从复制集群,那么我们应该先启动主节点,然后再启动从节点,如果没有先后顺序可以一下全启动,如果有先后顺序那么需要串行来,先启动第一个,再启第二个再启第三个这种方式来有序平滑的部署和扩展
- 有序,平滑的终止和删除,比如现在为一主八从的redis集群,那么应该把这八个从节点先关掉。并且如果启动为串行启动那么关闭时候也需要串行关闭。
- 有序的滚动更新。如果是主从复制服务器我们应该先滚动更新从节点然后再滚动更新主节点。
一个典型的statefulset应该由三个组件组成
- headless service(无头服务)
- StatefulSet (stateful控制器)
- volumeClaimTemplate(存储卷申请模板)
为什么会有上面的需求呢?
我们在定义deployment的时候每一个pod的名称是没有顺序的,它是随机字符串,我们无法识别他们的顺序,因此它是无序的。但是在statefulset中要求必须是有序的。比如我们有r1到r8,r1代表第一个从节点,r8代表最后一个节点,那我们启动时候应该是先启动r1再启动r8,关闭时应该是先关闭r8再关闭r1。既然如此,每一个pod都不能随意被别人所取代,此前是谁,挂了重新启动起来还是应该是谁,比如r6因为故障重建了那么他还是r6,尤其是redis cluster,redis中由很多槽位来存储,第一个节点1-5000,第二个是5001到10000,第三个节点是10001到16383,第一个节点挂了我所有替换出来的时候他没有顺序了这就很麻烦,因为它只有靠顺序才能识别出来它是管理哪些槽位的,由标识符或ip地址决定,但是pod的ip地址是经常发生变化的,因此我们不以ip地址来识别而是以节点名称,所以在有状态集中节点名不能变,每一个节点的节点名是不能动的,并且第一次是什么名我把它删了再重建后这个pod的名称还必须是这个名字。因为pod的名称是作为识别pod唯一性的标识符,这个标识符必须稳定,持久,可行,有效。那么怎么能确保其有这些特性呢?这个时候就需要用到一个headless service来确保我们解析的名称是直达后端pod ip地址,并确保还要给每一个pod配置一个唯一的名称,所以其需要一个headless
我们讲过大多数有状态副本集都会用到一个功能就是持久存储。任然以redis为例,redis cluster三个节点存储的数据一样么?对于分布式系统来讲其最大的特点就是数据是不一样的,所以这三个pod不能共享同一个后端存储,比如我们作为一个nfs存储卷,多路访问同一个节点上的同一个存储卷是可以的。那么现在我们能不能让我们三个redis的分布式的集群的各节点使用同一个存储卷?他们存的数据完全是不一样的,因此他们肯定不能使用同一个存储卷,因此每个节点应该有自己专用的存储卷。
如果我们在deployment中定义模板中定义一个存储卷,要基于pod模板创建一个pod,这个pod中定义的存储卷,那么如果做了5个pod副本,那么这5个副本肯定是访问同一个存储卷,因为是基于模板创建的pod,因此在模板中创建的存储卷对所有的pod都是一样的。但是我们并没有说在statefulset中每一个pod都不能使用同一个存储卷,因此我们基于Pod模板来创建pod是不适用的,这就是为什么要给其定义volumeClaimTemplate的原因。这样我们创建每一个pod时他会自动生成一个pvc,从而请求绑定一个pv,从而有自己的专用存储卷,每一个pod都会申请一个专用的pvc和pv,因此如果要做一主两从那么至少需要有三个卷让各自分别使用而不是多个pod使用同一个存储卷。
statefulset 实例
实例1
statufulset 控制器都应该由三部分组成
- 有一个service,这个service必须是无头服务,所以其ClusterIP为Node
- 有一个statefulset控制器,请求使用一个2G大小的pvc,因此在系统之上必须要有创建好的pvc以及与之绑定的pv,volumeClaimTemplates就是帮我们动态请求创建pvc的,所以我们要有提前创建好的pv,如果没有创建好的pv那我们就只有动态供给
- 我们此前有个nfs上做了5个目录,并在我们系统上我们做了5个pv,其中有一个实际的已经被用了,接下来做一个2G 存储空间的statefulset 的pod的pv
- 我们将来在集群中创建pod应该是这样来做的,第一,每个pod中应该定义一个pvc类型的volume,这个pvc类型的volume应该关联至当前同一个名称空间的pvc,这个pvc应该关联到集群级别的pv,pv创建好后pvc默认是不存在的,pvc需要使用volumeClaimTemplates来动态生成,每一个pod自己的存储卷是在Template中定义的。
开始实施
查看pv
kubectl get pv

定义 statefulset


apiVersion: v1 kind: Service metadata: name: myapp labels: app: myapp spec: ports: - port: 80 name: web clusterIP: None selector: app: myapp-pod --- apiVersion: apps/v1 kind: StatefulSet metadata: name: myapp spec: serviceName: myapp #这是必须要的字段,需要关联到每一个无头服务上,他基于这个无头服务才能给每一个pod分配一个唯一的,持久的,固定的标识符 replicas: 3 selector: matchLabels: app: myapp-pod template: metadata: labels: app: myapp-pod spec: containers: - name: myapp image: ikubernetes/myapp:v1 ports: - containerPort: 80 name: web volumeMounts: - name: myappdata mountPath: /usr/share/nginx/html volumeClaimTemplates: - metadata: name: myappdata spec: accessModes: [ "ReadWriteOnce" ] resources: requests: storage: 5Gi
查看创建好的 statefulset
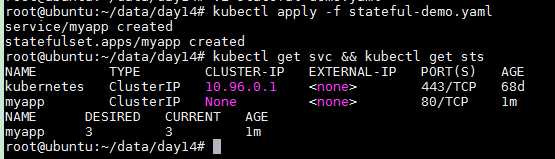
kubectl apply -f stateful-demo.yaml kubectl get svc && kubectl get sts
查看pvc可以看到已经处于绑定状态
kubectl get pvc

查看pv
kubectl get pv

可以看到volumeClaimTemplates能自动完成两个功能,第一,为每一个pod定义volume。第二,在pod所在名称空间中自动创建pvc
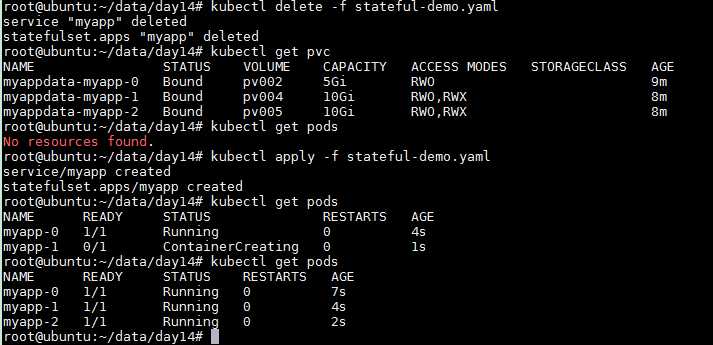
如果我们把sts删了,它会逆向删除pod,先删myapp-2 再删 myapp-1 最后删myapp-0,创建的时候其会顺序创建。并且,对应的动态创建的pvc不会随着sts或者pod删除而删除,当删除后再次启动sts时其会再次绑定至先前的pod,并且重启后的pod名字也不会改变
kubectl delete -f stateful-demo.yaml kubectl get pvc kubectl apply -f stateful-demo.yaml kubectl get pods
滚动更新
- 对于stateful来讲,要想实现滚动更新我们把image从v1变成v2即可。而且我们每一个pod自己的名字都是可被解析的,而且是固定名称。
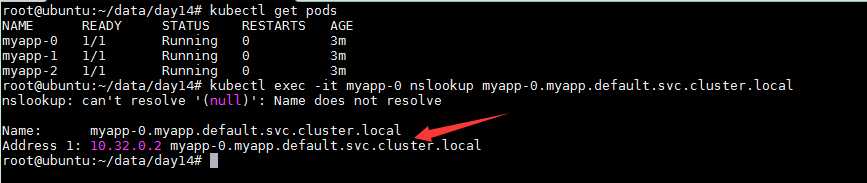
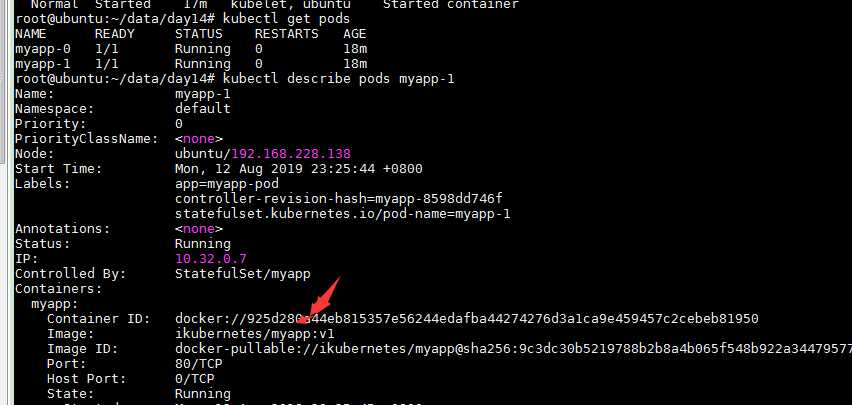
- 解析时pod的名称应该为 pod_name.service_name.ns_name.svc.cluster.local,比如上面的pod就叫 myapp-0.myapp.default.svc.cluster.local
kubectl get pods kubectl exec -it myapp-0 nslookup myapp-0.myapp.default.svc.cluster.local
每一个pod中名称是固定的,dns也能解析,所以我们靠这个唯一名称去识别它以后跟他的固定名称的pvc保持对应关系,我们连pvc的名字都隐含了pod的名字。使得他们可以持久持续的为同一个pod所使用

扩容和缩容
statefulset也能实现扩容和缩容,我们扩容方法也很简单,直接使用scale命令,这种扩展是有顺序的,先扩展第三个再扩展第四个,缩减的话是逆序的。
kubectl scale sts myapp --replicas=5 kubectl patch sts myapp -p ‘"spec":"replicas":2‘
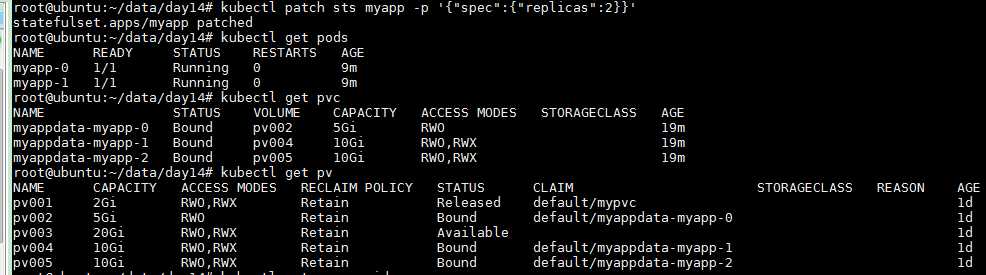
stateful只要定义好了也支持规模扩容和缩容,并且扩容和缩容时时也一样支持暂停。如果我们想升级stateful中应用版本我们可使用set image来实现,并且我们支持自定义更新策略,更新策略有两种。
KIND: StatefulSet VERSION: apps/v1 RESOURCE: updateStrategy <Object> DESCRIPTION: updateStrategy indicates the StatefulSetUpdateStrategy that will be employed to update Pods in the StatefulSet when a revision is made to Template. StatefulSetUpdateStrategy indicates the strategy that the StatefulSet controller will use to perform updates. It includes any additional parameters necessary to perform the update for the indicated strategy. FIELDS: rollingUpdate <Object> RollingUpdate is used to communicate parameters when Type is RollingUpdateStatefulSetStrategyType. type <string> Type indicates the type of the StatefulSetUpdateStrategy. Default is RollingUpdate. [root@k8smaster stateful]# kubectl explain sts.spec.updateStrategy.rollingUpdate KIND: StatefulSet VERSION: apps/v1 RESOURCE: rollingUpdate <Object> DESCRIPTION: RollingUpdate is used to communicate parameters when Type is RollingUpdateStatefulSetStrategyType. RollingUpdateStatefulSetStrategy is used to communicate parameter for RollingUpdateStatefulSetStrategyType. FIELDS: partition <integer> #分区更新,假如我们pod有 myapp-0 到 myapp-4,若定义partition值为5则大于等于5的将会被更新,因为pod最大为4因此都不会更新。因此我们可以先把partition设置为4,这样myapp-04就会更新,当发现myapp-04提供的服务没问题就将partition设置为0进行所有更新,可以这样来模拟金丝雀发布。 Partition indicates the ordinal at which the StatefulSet should be partitioned. Default value is 0.
我们sts默认更新策略为RollingUpdate,并没有指出我们分区是什么。所以我们接下来需要给其打一个补丁,改它的分区为4,即只有大于或等于4的才会更新。
kubectl patch sts myapp -p ‘"spec":"updateStrategy":"rollingUpdate":"partition":4‘ kubectl describe sts myapp
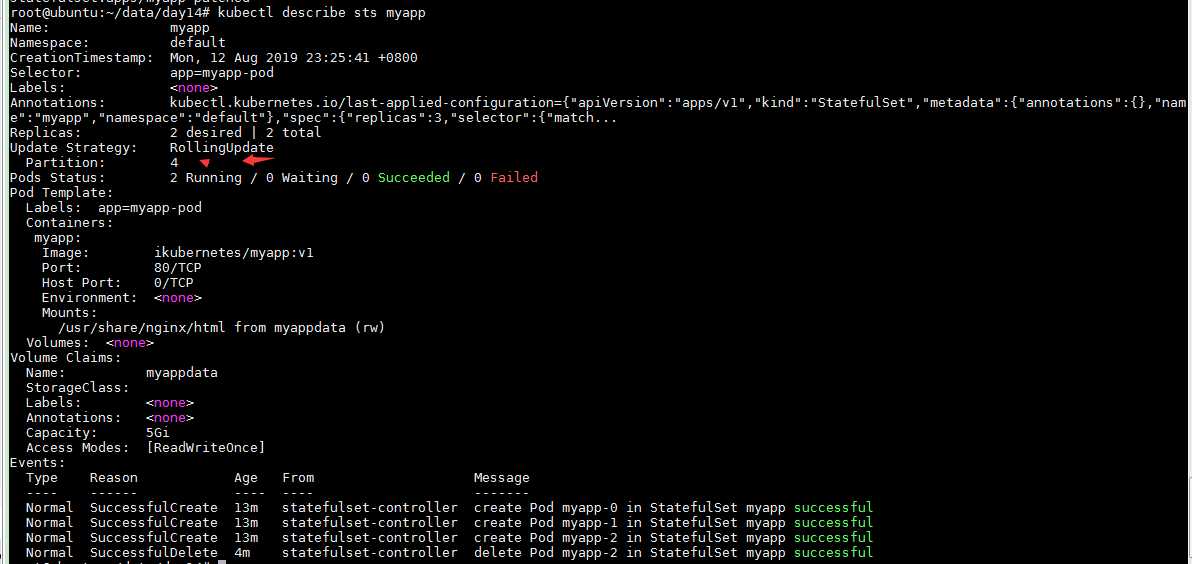
修改容器镜像
kubectl set image sts/myapp myapp=ikubernetes/myapp:v2

可以查看到pod中容器并没有更新镜像,因为默认是从第4个pod开始更新
当前pod为2个,通过 kubectl scale sts myapp --replicas=5 将pod扩展至5个,可以看到只有myapp-4 镜像为ikubernetes/myapp:v2 其它pod镜像都为ikubernetes/myapp:v1
金丝雀发布的下一步为: 再次打补丁将分区改为0,此修改实时生效,此时所有的容器都将镜像设置为ikubernetes/myapp:v2 了
以上是关于kubernetes statefulset的主要内容,如果未能解决你的问题,请参考以下文章