数据仓库系列之维度建模
Posted fly-bird
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据仓库系列之维度建模相关的知识,希望对你有一定的参考价值。
上一篇文章我已经简单介绍了数据分析中为啥要建立数据仓库,从本周开始我们开始一起学习数据仓库。学习数据仓库,你一定会了解到两个人:数据仓库之父比尔·恩门(Bill Inmon)和数据仓库权威专家Ralph Kimball。Inmon和Kimball两种DW架构支撑了数据仓库以及商业智能近二十年的发展,其中Inmon主张自上而下的架构,不同的OLTP数据集中到面向主题、集成的、不易失的和时间变化的结构中,用于以后的分析;且数据可以通过下钻到最细层,或者上卷到汇总层;数据集市应该是数据仓库的子集;每个数据集市是针对独立部门特殊设计的。而Kimball正好与Inmon相反,Kimball架构是一种自下而上的架构,它认为数据仓库是一系列数据集市的集合。企业可以通过一系列维数相同的数据集市递增地构建数据仓库,通过使用一致的维度,能够共同看到不同数据集市中的信息,这表示它们拥有公共定义的元素。
这里我主要介绍维度建模方法。这一方法是Kimball最先提出的,其最简单的描述就是按照事实表、维度表来构建数据仓库、数据集市。在维度建模方法体系中,维度是描述事实的角度,如日期、客户、供应商等,事实是要度量的指标,如客户数、销售额等。按照一般书籍的介绍,维度建模还会分为星型模型、雪花模型等,各有优缺点,但很少直接回答一个问题,也就是数据仓库为什么要采用维度建模?
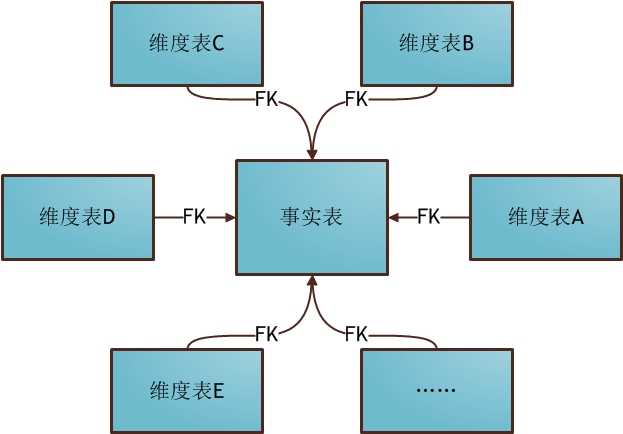
星型模型
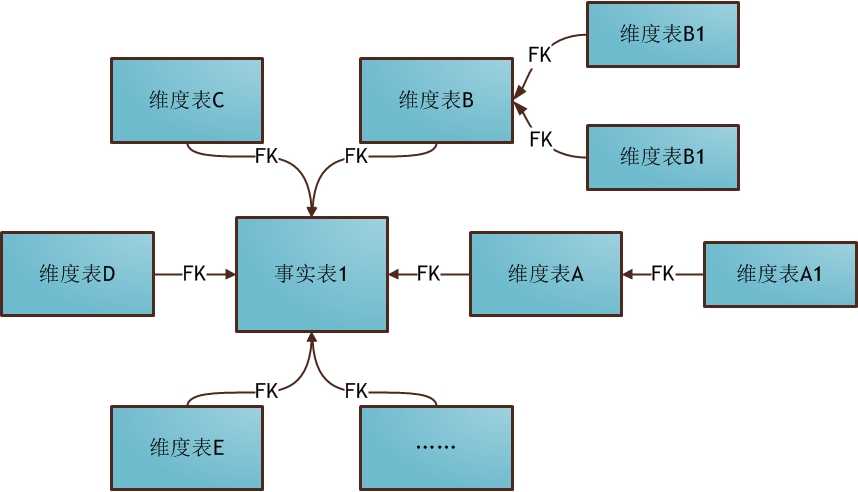
雪花模型
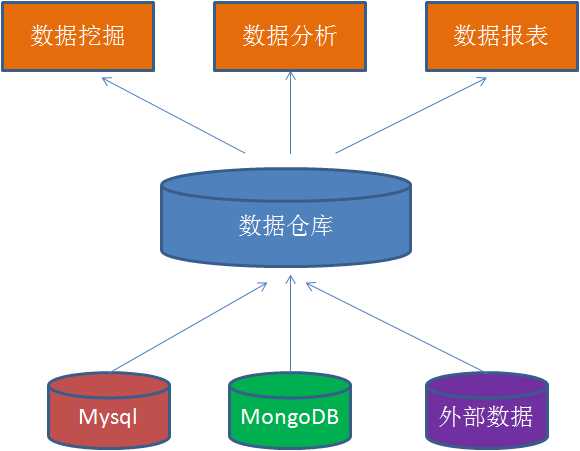
数据仓库包含的内容很多,它可以包括架构、建模和方法论。对应到具体工作中的话,它可以包含下面的这些内容:
1、数据架构体系:以Hadoop、Spark等组建为中心的数据架构体系。
2、各种数据建模方法:如维度建模、范式建模法、实体建模法。
3、辅助系统:调度系统、元数据系统、ETL系统、可视化系统这类辅助系统。
我们暂且不管数据仓库的范围到底有多大,在数据仓库体系中,数据模型的核心地位是不可替代的。因此,下面的将详细地阐述数据建模中的典型代表:维度建模,对它的的相关理论以及实际使用做深入的分析。
为了能更真切地理解什么是维度建模,我将在后续的文章中模拟一个大家都十分熟悉的电商场景,运用讲到的理论进行建模。理论和现实的工作场景毕竟会有所差距,这一块,我会分享一下企业在实际的应用中所做出的取舍。接下来具体来了解维度建模
一、什么是维度建模
维度模型是数据仓库领域大师Ralph Kimball 所倡导,他的《数据仓库工具箱》,是数据仓库工程领域最流行的数仓建模经典。维度建模以分析决策的需求出发构建模型,构建的数据模型为分析需求服务,因此它重点解决用户如何更快速完成分析需求,同时还有较好的大规模复杂查询的响应性能。
我们换一种方式来解释什么是维度建模。学过数据库的童鞋应该都知道星型模型,星型模型就是我们一种典型的维度模型。我们在进行维度建模的时候会建一张事实表,这个事实表就是星型模型的中心,然后会有一堆维度表,这些维度表就是向外发散的星星。那么什么是事实表、什么又是维度表,下面会专门来解释。
星型模型
二、维度建模的基本要素
维度建模中有一些比较重要的概念,理解了这些概念,基本也就理解了什么是维度建模。
1. 事实表
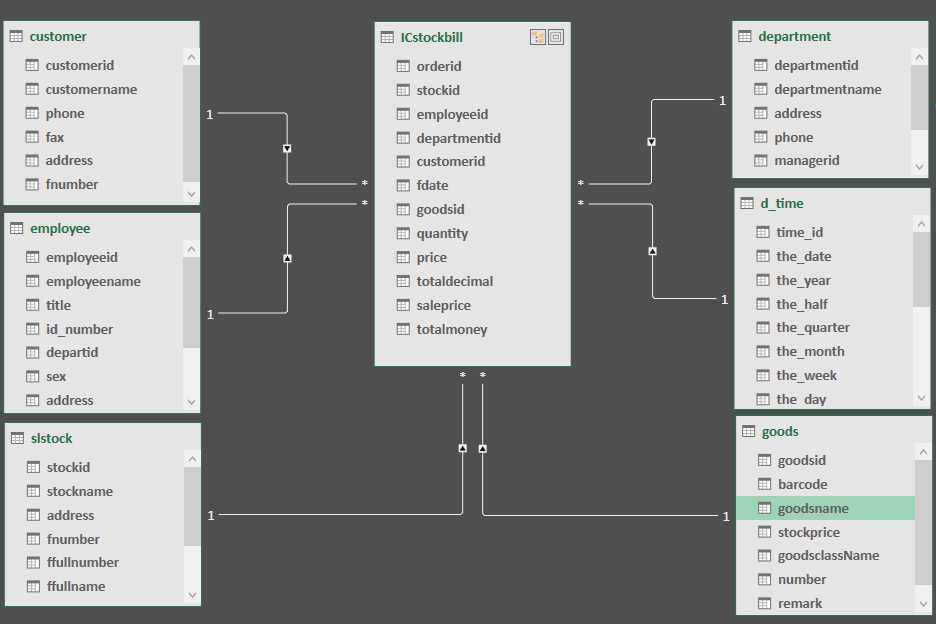
发生在现实世界中的操作型事件,其所产生的可度量数值,存储在事实表中。从最低的粒度级别来看,事实表行对应一个度量事件,反之亦然。不太理解举个例子。比如一次购买行为我们就可以理解为是一个事实,大家看一下星星模型示例。
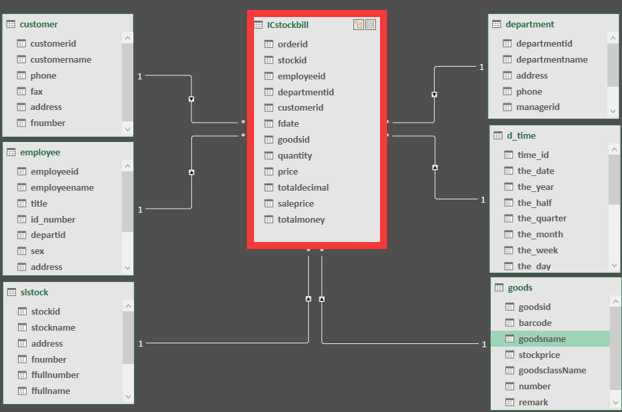
图中的订单表(ICstockbill)就是一个事实表,你可以理解他就是在现实中发生的一次操作型事件,我们每完成一个订单,就会在订单中增加一条记录。我们可以回过头再看一下事实表的特征,在事实表里没有存放实际的内容,他是一堆主键的集合,这些ID分别能对应到维度表中的一条记录。
2. 维度表
每个维度表都包含单一的主键列。维度表的主键可以作为与之关联的任何事实表的外键,当然,维度表行的描述环境应与事实表行完全对应。 维度表通常比较宽,是扁平型非规范表,包含大量的低粒度的文本属性。图中的customer(客户表)、goods(商品表)、d_time(时间表)这些都属于维度表,这些表都有一个唯一的主键,然后在表中存放了详细的数据信息。
最后说一下维度模型的优缺点:
1、数据冗余小(因为很多具体的信息都存在相应的维度表中了,比如客户信息就只有一份)
2、结构清晰(表结构一目了然)
3、便于做OLAP分析(数据分析用起来会很方便)
4、增加使用成本,比如查询时要关联多张表
5、数据不一致,比如用户发起购买行为的时候的数据,和我们维度表里面存放的数据不一致
再说没有数据仓库的宽事实表的优缺点:
1、业务直观,在做业务的时候,这种表特别方便,直接能对到业务中。
2、使用方便,写sql的时候很方便。
3、数据冗余巨大,真的很大,在几亿的用户规模下,他的订单行为会很恐怖、粒度僵硬,什么都写死了,这张表的可复用性太低。
数据仓库的建模方法有很多种,我目前主要学习了解的维度建模方法。开始尝试写数据仓库系列文章,文中如有错误或误导的地方欢迎大家指出纠正。 希望这篇文章能够给大家带来帮助,最后感谢大家的阅读。欢迎大家一起加入高效数据处理ETL交流群,一起讨论数据分析前ETL过程的问题,一起学习一起成长。
扫码加群:

以上是关于数据仓库系列之维度建模的主要内容,如果未能解决你的问题,请参考以下文章