阴谋还是悲剧?- 基于机器学习假设检验视角,看泰坦尼克号事件
Posted littlehann
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阴谋还是悲剧?- 基于机器学习假设检验视角,看泰坦尼克号事件相关的知识,希望对你有一定的参考价值。
1. 引言
0x1:故事背景
泰坦尼克号(RMS Titanic),又译作铁达尼号,是英国白星航运公司下辖的一艘奥林匹克级邮轮,排水量46000吨,于1909年3月31日在北爱尔兰贝尔法斯特港的哈兰德与沃尔夫造船厂动工建造,1911年5月31日下水,1912年4月2日完工试航。
泰坦尼克号是当时世界上体积最庞大、内部设施最豪华的客运轮船,有“永不沉没”的美誉 。然而不幸的是,在它的处女航中,泰坦尼克号便遭厄运——它从英国南安普敦出发,途经法国瑟堡-奥克特维尔以及爱尔兰科夫(Cobh),驶向美国纽约。1912年4月14日23时40分左右,泰坦尼克号与一座冰山相撞,造成右舷船艏至船中部破裂,五间水密舱进水。次日凌晨2时20分左右,泰坦尼克船体断裂成两截后沉入大西洋底3700米处。2224名船员及乘客中,逾1500人丧生,其中仅333具罹难者遗体被寻回。泰坦尼克号沉没事故为和平时期死伤人数最为惨重的一次海难,其残骸直至1985年才被再度发现,目前受到联合国教育、科学及文化组织的保护。
这场耸人听闻的悲剧震惊了国际社会,并为船舶制定了更好的安全规定。造成海难失事的原因之一是乘客和机组人员没有足够的救生艇。尽管幸存下沉有一些运气因素,但有些人比其他人更容易生存,例如妇女,儿童和上流社会。
0x2:阴谋还是悲剧
在事件发生后,当时有很多阴谋论者怀疑泰坦尼克号事件是一个世纪大阴谋,是航运公司的一次骗保行为,一度争论了很久。
当然,笔者并不是历史学家,所以我们这次不从证据学的角度来分析这次事件。相反,我们尝试运用统计学的思维,从数据挖掘与分析层面来看一下,这次事故是真实的可能性有多少。
基本假设是这样的,我们首先建立一个二元对立假设,这是本文的最大的基础:
- 如果是一次骗保行为,则航运公司的目标是将 船给摧毁,除此之外不会有任何其他的行为,那么船长也不应该表现出任何的绅士和道德楷模风度,或者说,即使是作秀,表现出的道德程度也不应该很强。
- 如果是一个真实事故,则所有人(包括船长)表现出的行为都是按照人的第一反应作出的,则按照事后幸存者的采访记录,副船长爱德华·约翰·史密斯表现出了惊人的绅士风度和道德楷模风范,他说出了那句著名的话,『 lady and kid first!』,而自己则坚守到最后,非常令人感动。
接下来,我们将通过对数据进行建模,从而看某些特征指标(妇女、小孩)和生还之间是否存在强相关关系,以此推断出上述二元对立的结果。
Relevant Link:
https://baike.baidu.com/item/%E6%B3%B0%E5%9D%A6%E5%B0%BC%E5%85%8B%E5%8F%B7/5677
2. 数据建模
0x1:数据集
原始数据集可以从kaggle这里下载得到,kaggle的原题是做predict的,所以将数据集分为了train/test set,但是笔者这里并不做预测任务,因此将其合并起来作为一个统一的有标数据集,百度网盘链接在这里。
链接: https://pan.baidu.com/s/18Ushn_Oms8Q0RLw6TGFMnQ 提取码: u5gt
0x2:数据集字段探查
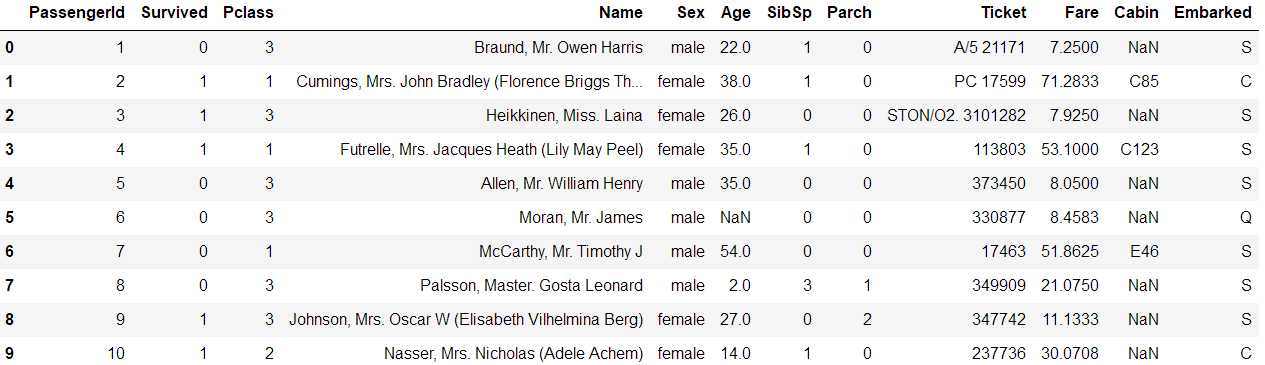
各个特征字段意义如下:
0x3:数据缺失值补充
在很多统计项目中,由于数据采集手段上的限制,缺失值是非常常见的。因此,这里我们先进行缺失值处理。
# -*- coding: utf-8 -*- import pandas as pd import numpy as np if __name__ == ‘__main__‘: dataset_file = "full_dataset.csv" dataset = pd.read_csv(dataset_file) print(dataset.info())
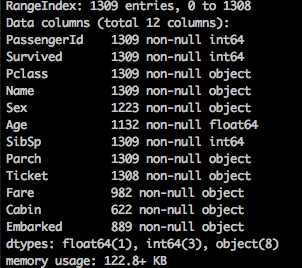
可以看到,【Sex,Age,Ticket,Fare,Cabin,Embarked】这几个字段都存在缺失值。
缺失值处理的思路有以下两种:
- 1. 默认填充值的范围[(mean - std) ,(mean + std)]。
- 2. 将缺失的Age当做label,将其他列的属性当做特征,通过已有的Age的记录训练模型,来预测缺失的Age值。
这里采取方法1,以Age为例:
for dataset in full_data: age_avg = dataset[‘Age‘].mean() age_std = dataset[‘Age‘].std() age_null_count = dataset[‘Age‘].isnull().sum() age_default_list = np.random.randint(low=age_avg-age_std,high=age_avg+age_std,size=age_null_count) dataset[‘Age‘][np.isnan(dataset[‘Age‘])] = age_default_list dataset[‘Age‘] = dataset[‘Age‘].astype(int)
其他字段以此类推,这里不再赘述,文末会给出完整代码。
0x4:离散特征数值化处理
对于有限离散的字符串特征,还需要进行映射处理或者one-hot处理。
def Passenger_Embarked(x): Embarked = ‘S‘:0, ‘C‘:1, ‘Q‘:2 return Embarked[x]
0x5:特征二次处理 - 专家经验特征
除了原始数据集的基础特征之外,还可以基于专家经验进行组合特征,当然这可以通过AutoEncoder进行自动完成,之所以不这么做的原因是因为AE的内部机制不容易对外暴露,可解释性工作会变得很复杂,因为我们这里使用人工特征组合,并使用XGB进行模型拟合。
1. 家族名特征
在所有特征中注意到有一个Name字段,这是一个字符串特征,字符串本身是无法输入模型的。显然,我们不能直接将Name进行ascii向量化,因为名字本身是没有任何意义的,我们需要将其groupby处理后得到某种统计意义上的特征。
我们发现Name的title name是存在类别的关系的。于是可以对Name进行提取出称呼这一类别title name。
import re def get_title_name(name): title_s = re.search(‘ ([A-Za-z]+)\\.‘, name) if title_s: return title_s.group(1) return "" for dataset in full_data: dataset[‘TitleName‘] = dataset[‘Name‘].apply(get_title_name) print(pd.crosstab(train[‘TitleName‘],train[‘Sex‘])) ###### out Sex female male TitleName Capt 0 1 Col 0 2 Countess 1 0 Don 0 1 Dr 1 6 Jonkheer 0 1 Lady 1 0 Major 0 2 Master 0 40 Miss 182 0 Mlle 2 0 Mme 1 0 Mr 0 517 Mrs 125 0 Ms 1 0 Rev 0 6 Sir 0 1 ####可以看出不同的titlename中男女还是有区别的。进一步探索titlename对Survived的影响。 ####看出上面的离散取值范围还是比较多,所以可以将较少的几类归为一个类别。 train[‘TitleName‘] = train[‘TitleName‘].replace(‘Mme‘, ‘Mrs‘) train[‘TitleName‘] = train[‘TitleName‘].replace(‘Mlle‘, ‘Miss‘) train[‘TitleName‘] = train[‘TitleName‘].replace(‘Ms‘, ‘Miss‘) train[‘TitleName‘] = train[‘TitleName‘].replace([‘Lady‘, ‘Countess‘,‘Capt‘, ‘Col‘, ‘Don‘, ‘Dr‘, ‘Major‘, ‘Rev‘, ‘Sir‘, ‘Jonkheer‘, ‘Dona‘], ‘Other‘) print (train[[‘TitleName‘, ‘Survived‘]].groupby(‘TitleName‘, as_index=False).mean()) ###### out1 TitleName Survived 0 Master 0.575000 1 Miss 0.702703 2 Mr 0.156673 3 Mrs 0.793651 4 Other 0.347826
可以看出TitleName对存活率还是有影响差异的,这就说明了TitleName中蕴含了信息,有信息就可以为模型所用。
从信息增益的角度出发,最后将TitleName总共为了5个类别:Mrs,Miss,Master,Mr,Other。
2. 家庭大小
SibSp和Parch分别为同船的兄弟姐妹和父母子女数,离散数据,没有缺失值。于是可以根据该人的家庭情况组合出不同的特征。
并且,根据FamilySize大小增加新特征IsAlone。
0x6:模型训练
# -*- coding: utf-8 -*- import pandas as pd import numpy as np import re from sklearn.preprocessing import LabelBinarizer from sklearn.ensemble import RandomForestRegressor import xgboost as xgb from xgboost import plot_importance import matplotlib.pyplot as plt def Passenger_sex(x): sex = ‘female‘: 0, ‘male‘: 1 return sex[x] def Passenger_Embarked(x): Embarked = ‘S‘: 0, ‘C‘: 1, ‘Q‘: 2 return Embarked[x] def get_title_name(name): title_s = re.search(‘ ([A-Za-z]+)\\.‘, name) if title_s: return title_s.group(1) return "" def Passenger_TitleName(x): TitleName = ‘Mr‘:0,‘Miss‘:1, ‘Mrs‘:2, ‘Master‘:3, ‘Other‘:4 return TitleName[x] def data_feature_engineering(full_data, age_default_avg=True, one_hot=True): """ :param full_data:全部数据集,包括train,test :param age_default_avg: age默认填充方式,是否使用平均值进行填充 :param one_hot: Embarked字符处理是否是one_hot编码还是映射处理 :return:处理好的数据集 """ for dataset in full_data: # Pclass,Parch,SibSp不需要处理 # Sex用 0,1做映射,‘female‘:0, ‘male‘:1 dataset[‘Sex‘] = dataset[‘Sex‘].map(Passenger_sex).astype(int) # SibSp和Parch均没有空值,组合特征FamilySize dataset[‘FamilySize‘] = dataset[‘SibSp‘] + dataset[‘Parch‘] + 1 # 根据FamilySize大小增加新特征IsAlone dataset[‘IsAlone‘] = 0 isAlone_mask = dataset[‘FamilySize‘] == 1 dataset.loc[isAlone_mask, ‘IsAlone‘] = 1 # Fare数据存在空值,先填充 fare_median = dataset[‘Fare‘].median() dataset[‘Fare‘] = dataset[‘Fare‘].fillna(fare_median) # Embarked存在空值,众数填充,映射处理或者one-hot 编码 dataset[‘Embarked‘] = dataset[‘Embarked‘].fillna(‘S‘) dataset[‘Embarked‘] = dataset[‘Embarked‘].astype(str) if one_hot: # 因为OneHotEncoder只能编码数值型,所以此处使用LabelBinarizer进行独热编码 Embarked_arr = LabelBinarizer().fit_transform(dataset[‘Embarked‘]) dataset[‘Embarked_0‘] = Embarked_arr[:, 0] dataset[‘Embarked_1‘] = Embarked_arr[:, 1] dataset[‘Embarked_2‘] = Embarked_arr[:, 2] dataset.drop(‘Embarked‘, axis=1, inplace=True) else: # 字符映射处理 dataset[‘Embarked‘] = dataset[‘Embarked‘].map(Passenger_Embarked).astype(int) # Name选取称呼Title_name,‘Mr‘:0,‘Miss‘:1, ‘Mrs‘:2, ‘Master‘:3, ‘Other‘:4 dataset[‘TitleName‘] = dataset[‘Name‘].apply(get_title_name) dataset[‘TitleName‘] = dataset[‘TitleName‘].replace(‘Mme‘,‘Mrs‘) dataset[‘TitleName‘] = dataset[‘TitleName‘].replace(‘Mlle‘, ‘Miss‘) dataset[‘TitleName‘] = dataset[‘TitleName‘].replace(‘Ms‘, ‘Miss‘) dataset[‘TitleName‘] = dataset[‘TitleName‘].replace([‘Lady‘, ‘Countess‘, ‘Capt‘, ‘Col‘, ‘Don‘, ‘Dr‘, ‘Major‘, ‘Rev‘, ‘Sir‘, ‘Jonkheer‘, ‘Dona‘], ‘Other‘) dataset[‘TitleName‘] = dataset[‘TitleName‘].map(Passenger_TitleName).astype(int) # age 缺失值,可以使用随机值填充,也可以用RF预测 if age_default_avg: # 缺失值使用avg处理 age_avg = dataset[‘Age‘].mean() age_std = dataset[‘Age‘].std() age_null_count = dataset[‘Age‘].isnull().sum() age_default_list = np.random.randint(low=age_avg-age_std, high=age_avg+age_std, size=age_null_count) dataset.loc[np.isnan(dataset[‘Age‘]),‘Age‘] = age_default_list dataset[‘Age‘] = dataset[‘Age‘].astype(int) else: # 将age作为label,使用RF的age # 特征为TitleName,Sex,pclass,SibSP,Parch,IsAlone,CategoricalFare,FamileSize,Embarked feature_list = [‘TitleName‘, ‘Sex‘, ‘Pclass‘, ‘SibSp‘, ‘Parch‘, ‘IsAlone‘, ‘CategoricalFare‘, ‘FamilySize‘, ‘Embarked‘, ‘Age‘] if one_hot: feature_list.append(‘Embarked_0‘) feature_list.append(‘Embarked_1‘) feature_list.append(‘Embarked_2‘) feature_list.remove(‘Embarked‘) Age_data = dataset.loc[:, feature_list] un_Age_mask = np.isnan(Age_data[‘Age‘]) Age_train = Age_data[~un_Age_mask] #要训练的Age feature_list.remove(‘Age‘) rf0 = RandomForestRegressor(n_estimators=60, oob_score=True, min_samples_split=10, min_samples_leaf=2, max_depth=7, random_state=10) rf0.fit(Age_train[feature_list], Age_train[‘Age‘]) def set_default_age(age): if np.isnan(age[‘Age‘]): data_x = np.array(age.loc[feature_list]).reshape(1,-1) age_v = np.round(rf0.predict(data_x))[0] print(age_v) return age_v return age[‘Age‘] dataset[‘Age‘] = dataset.apply(set_default_age, axis=1) return full_data # 特征选择 def data_feature_select(full_data): """ :param full_data:全部数据集 :return: """ drop_list = [‘PassengerId‘, ‘Name‘, ‘Ticket‘, ‘Cabin‘] for data_set in full_data: # remove meaningless feature data_set.drop(drop_list, axis=1, inplace=True) train_y = np.array(full_data[0][‘Survived‘]) train = full_data[0].drop(‘Survived‘, axis=1, inplace=False) return train, train_y def modelfit(alg,dtrain_x,dtrain_y,useTrainCV=True,cv_flods=5,early_stopping_rounds=50): """ :param alg: 初始模型 :param dtrain_x:训练数据X :param dtrain_y:训练数据y(label) :param useTrainCV: 是否使用cv函数来确定最佳n_estimators :param cv_flods:交叉验证的cv数 :param early_stopping_rounds:在该数迭代次数之前,eval_metric都没有提升的话则停止 """ if useTrainCV: xgb_param = alg.get_xgb_params() xgtrain = xgb.DMatrix(dtrain_x,dtrain_y) print(alg.get_params()[‘n_estimators‘]) cv_result = xgb.cv(xgb_param,xgtrain,num_boost_round = alg.get_params()[‘n_estimators‘], nfold = cv_flods, metrics = ‘auc‘, early_stopping_rounds=early_stopping_rounds) print(cv_result) print(cv_result.shape[0]) alg.set_params(n_estimators=cv_result.shape[0]) # train data alg.fit(train_X,train_y,eval_metric=‘auc‘) #predict train data train_y_pre = alg.predict(train_X) print ("\\nModel Report") print ("Accuracy : %.4g" % metrics.accuracy_score(train_y, train_y_pre)) feat_imp = pd.Series(alg.get_booster().get_fscore()).sort_values(ascending=False) feat_imp.plot(kind = ‘bar‘,title=‘Feature Importance‘) plt.ylabel(‘Feature Importance Score‘) plt.show() print(alg) if __name__ == ‘__main__‘: dataset_file = "./full_dataset.csv" full_data = pd.read_csv(dataset_file) full_data = [full_data] # feature engineering full_data = data_feature_engineering(full_data, age_default_avg=True, one_hot=False) # select feature train_X, train_y = data_feature_select(full_data) print train_X print train_y # train the model # 1. set booster param param = ‘max_depth‘: 7, ‘eta‘: 1, ‘silent‘: 1, ‘objective‘: ‘reg:linear‘ param[‘nthread‘] = 4 param[‘seed‘] = 100 param[‘eval_metric‘] = ‘auc‘ num_round = 10 dtrain = xgb.DMatrix(data=train_X, label=train_y, missing=-999.0) bst_xgboost_model = xgb.train(param, dtrain, num_round) # print the feature importance table ### plot feature importance fig, ax = plt.subplots(figsize=(15, 15)) plot_importance(bst_xgboost_model, height = 0.5, ax=ax, max_num_features=64) plt.show()
3. 结果分析
Xgboost训练后得到的特征重要性评估表如下:
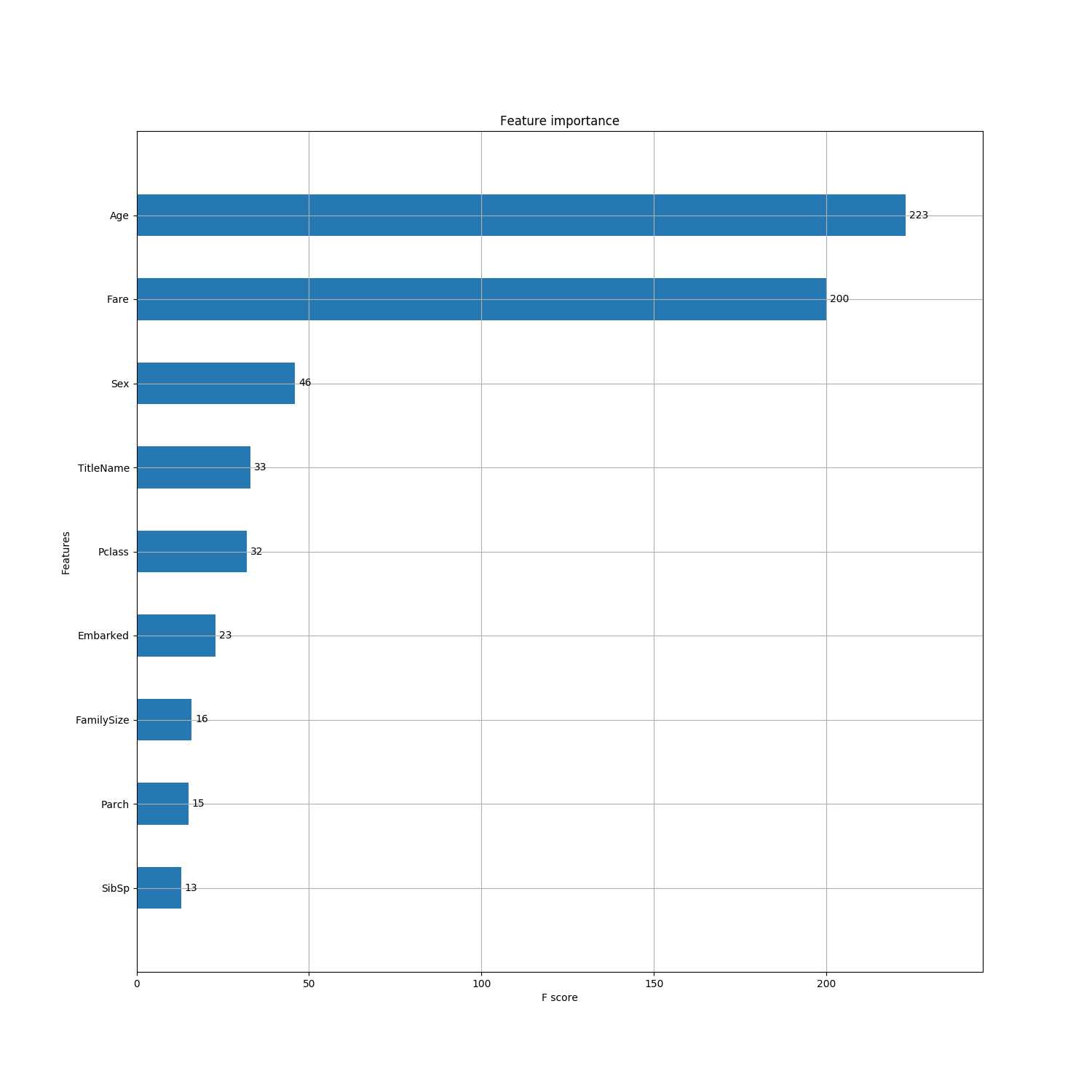
从结果中可以得到几点信息:
- Age年龄确实是和是否生还强相关的,占据了主导地位
- 紧随年龄之后,排名第二的生还因素是Fare(船票价格),这从一定程度上说明,不管是出于富人逃生意识更强,富人有更多机会上到顶层夹板玩了透气,还是说逃生的时候有意识地偏向了富人,财富在其中的作用一定程度上是存在的
- 排名第三的是Sex(性别),这也副船长的lady fisrt的说法也是一致的
- 往后的几个特征,从各个维度都说明了生还几率和财富有关
从数据和统计层面可以解读出很多信息,更深层次的猜测,读者朋友可以参阅下面一些链接:
https://baijiahao.baidu.com/s?id=1623250627137421869&wfr=spider&for=pc https://baijiahao.baidu.com/s?id=1621654492865556041&wfr=spider&for=pc https://baijiahao.baidu.com/s?id=1597619726579770526&wfr=spider&for=pc http://www.ufo-1.cn/article/201604/896.html
同样的分析方法,也可以用于二战珍珠港事件以及911事件的分析,读者朋友可以Google之。
笔者这里想说的是,无论什么时代,什么时候,总会有喷子无脑地抛出阴谋论的说法,好像所有事情背后总有一个看不见的手在操纵之类的,但是,历史总是在上演各种各样的大事件,所有事件的发生与否从单个事件来看也许是偶然离奇事件,但放到具体历史背景下,合理性是不容置疑的。
相反,当某个巨大灾难发生时,当民族遇到危机,当国家遭到危难时,站出来的总是看起来沉默寡言的英雄,正是这些英雄的存在,慰藉了我们的心灵,给了我们温暖与前进的力量,向英雄致敬。
以上是关于阴谋还是悲剧?- 基于机器学习假设检验视角,看泰坦尼克号事件的主要内容,如果未能解决你的问题,请参考以下文章