网络编程
Posted linxidong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网络编程相关的知识,希望对你有一定的参考价值。
网络编程
软件开发架构
c/s架构(client/server)
? c:客户端 和 s:服务端
? 例如: QQ,微信,网盘,这一类都属于c/s架构,我们都需要下载一个客户端才能够运行
? ps:这里的客户端一般泛指客户端应用程序EXE,程序需要先安装后,才能运行在用户的电脑上,对用户的电脑操作系统环境依赖较大。
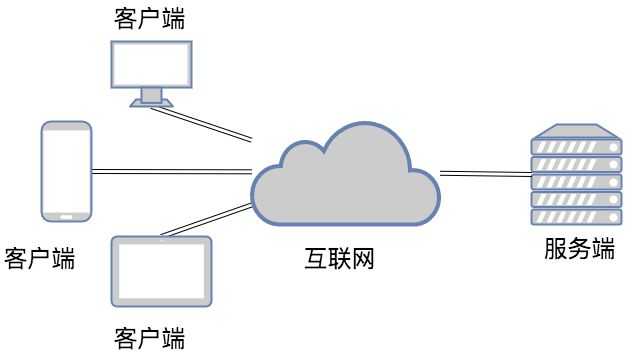
b/s架构(browser/server)
? b:浏览器 和 s:服务器
? 例如:百度,淘宝网页,博客园这类都属于b/s架构,我们可以直接通过浏览器访问直接使用的应用
? ps:Browser浏览器,其实也是一种Client客户端,只是这个客户端不需要大家去安装什么应用程序,只需在浏览器上通过HTTP请求服务器端相关的资源(网页资源),客户端Browser浏览器就能进行增删改查。
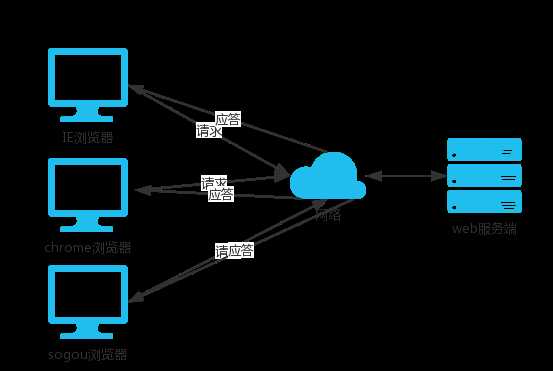
用大白话来总结客户端和服务端的作用基本上可以理解为:
服务端:24小时不间断提供服务
客户端:什么时候想体验服务就去服务端寻求服务
b/s架构的本质其实也是c/s架构,两者都是用于两个程序之间通讯的开发
网络基础
网络编程技术起源
绝大部分先进技术的兴起基本都来自于军事,网络编程这项技术就是来源于美国军事,为了实现数据的远程传输
人类实现远程沟通交流的方式
- 插电话线的电话
- 插网线的大屁股电脑
- 插无线网卡的笔记本电脑
综上我们能够总结出第一个规律:要想实现远程通信第一个需要具备的条件就是:**物理连接介质**
再来想人与人之间交流,中国人说中文,外国人说外语,那如果想实现不同国家的人之间无障碍沟通交流是不是得规定一个大家都能听得懂的语言>>>英语
再回来看计算机领域,计算机之间要想实现远程通信除了需要有物理连接介质之外是不是也应该有一套公共的标准?这套标准就是>>>OSI七层协议(也叫OSI七层模型)
OSI七层协议(模型)
- 应用层
- 表示层
- 会话层
- 传输层
- 网络层
- 数据链路层
- 物理连接层
也有人将其归纳为五层
- 应用层
- 传输层
- 网络层
- 数据链路层
- 物理连接层
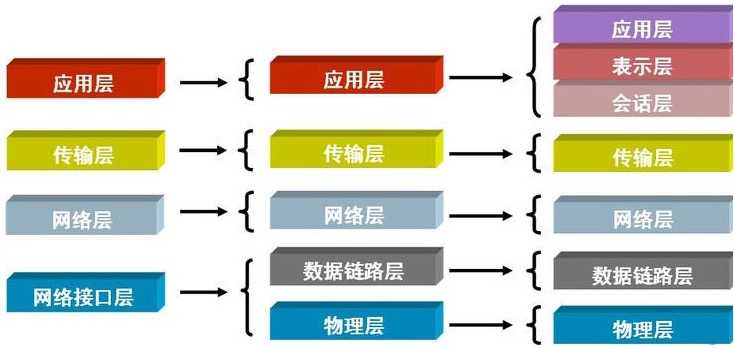
接下来我们就需要详细的看看每一层都有哪些需要我们了解掌握的知识点
物理连接层
实现计算机之间物理连接,传输的数据都是01010的二进制 电信号工作原理:电只有高低电平
数据链路层("以太网协议")
1.规定了二进制数据的分组方式 2.规定了只要是接入互联网的计算机,都必须有一块网卡! ps:网卡上面刻有世界唯一的编号: 每块网卡出厂时都被烧制上一个世界唯一的mac地址, 长度为48位2进制,通常由12位16进制数表示(前六位是厂商编号,后六位是流水线号) 我们管网卡上刻有的编号叫电脑的>>>mac地址 ----->上面的两个规定其实就是 "以太网协议"!
**基于以太网协议通信:**通信基本靠吼!!!弊端:广播风暴
**交换机:**如果没有交换机,你的电脑就变成了马蜂窝,有了交换机之后,所有的电脑只需要有一个网卡连接交换机,即可实现多台电脑之间物理连接
网络层(IP协议)
规定了计算机都必须有一个ip地址 ip地址特点:点分十进制 有两个版本ipv4和ipv6 为了能够兼容更多的计算机 最小:0.0.0.0 最大:255.255.255.255 IP协议可以跨局域网传输
ip地址能够唯一标识互联网中独一无二的一台机器!
**例如百度的ip地址:**[http://14.215.177.39](http://14.215.177.39/)/
传输层(端口协议)
TCP,UDP基于端口工作的协议! 其实计算机之间通信其实是计算机上面的应用程序于应用之间的通信 端口(port):唯一标识一台计算机上某一个基于网络通信的应用程序 端口范围:0~65535(动态分配) 注意:0~1024通常是归操作系统分配的端口号 通常情况下,我们写的软件端口号建议起在8000之后 flask框架默认端口5000 django框架默认端口8000 mysql数据库默认端口3306 redis数据库默认端口6379**注意:**一台计算机上同一时间一个端口号只能被一个应用程序占用
**小总结:** IP地址:唯一标识全世界接入互联网的独一无二的机器 port端口号:唯一标识一台计算机上的某一个应用程序 ip+port :能够唯一标识全世界上独一无二的一台计算机上的某一个应用程序
**补充:** arp协议:根据ip地址解析mac地址
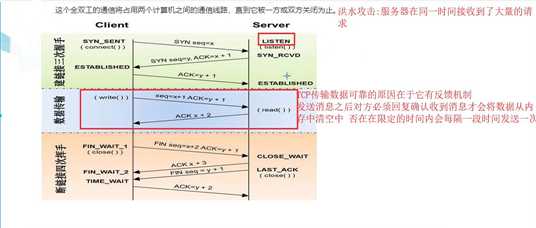
TCP协议(流式协议,可靠协议)
**三次握手四次挥手**
- 三次握手建连接
- 四次挥手断连接
星轨:
表示一个一线明星出轨所带来的流量,据说微博的服务器现在能同时扛8星轨。
也就是说:8个一线明星同一时间爆出出轨的新闻,微博都能扛得住!
应用层(HTTP协议,FTP协议)
套接字scoket概念
scoket层
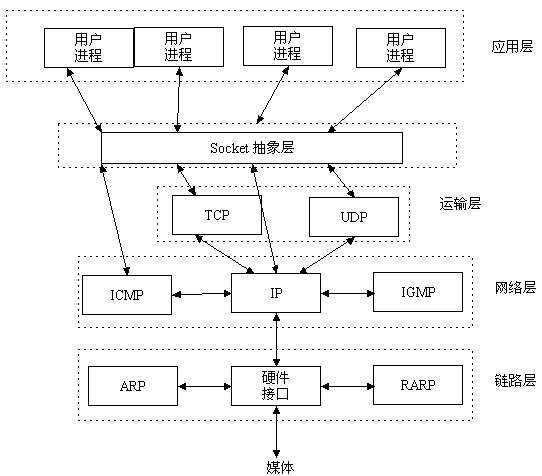
理解socket
Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。
TCP协议和UDP协议
TCP(Transmission Control Protocol)可靠的、面向连接的协议(eg:打电话)、传输效率低全双工通信(发送缓存&接收缓存)、面向字节流。使用TCP的应用:Web浏览器;电子邮件、文件传输程序。
UDP(User Datagram Protocol)不可靠的、无连接的服务,传输效率高(发送前时延小),一对一、一对多、多对一、多对多、面向报文,尽最大努力服务,无拥塞控制。使用UDP的应用:域名系统 (DNS);视频流;IP语音(VoIP)。
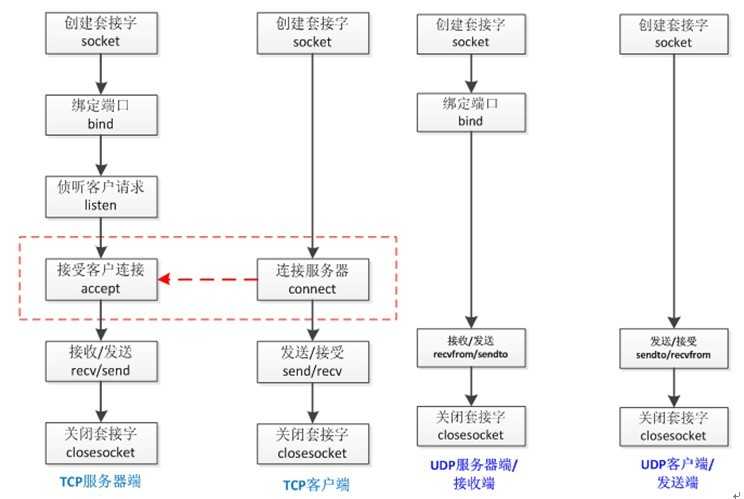
基于TCP协议的socket
socket通信的简单使用


import socket server = socket.socket() # 买手机 不传参数默认用的就是TCP协议 server.bind((‘127.0.0.1‘,8080)) # bind((host,port)) 插电话卡 绑定ip和端口 server.listen(5) # 开机 半连接池 conn, addr = server.accept() # 接听电话 等着别人给你打电话 阻塞 data = conn.recv(1024) # 听别人说话 接收1024个字节数据 阻塞 print(data) conn.send(b‘hello baby~‘) # 给别人回话 conn.close() # 挂电话 server.close() # 关机
import socket client = socket.socket() # 拿电话 client.connect((‘127.0.0.1‘,8080)) # 拨号 写的是对方的ip和port client.send(b‘hello world!‘) # 对别人说话 data = client.recv(1024) # 听别人说话 print(data) client.close() # 挂电话
ps:mac本在重启客户端时可能会遇到这样的问题:
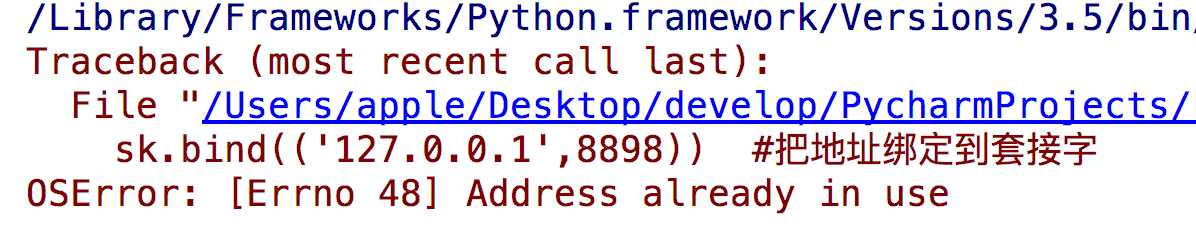
#加入一条socket配置,重用ip和端口 import socket from socket import SOL_SOCKET,SO_REUSEADDR sk = socket.socket() sk.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) #就是它,在bind前加 sk.bind((‘127.0.0.1‘,8898)) #把地址绑定到套接字 sk.listen() #监听链接 conn,addr = sk.accept() #接受客户端链接 ret = conn.recv(1024) #接收客户端信息 print(ret) #打印客户端信息 conn.send(b‘hi‘) #向客户端发送信息 conn.close() #关闭客户端套接字 sk.close() #关闭服务器套接字(可选)
TCP粘包问题
import socket server = socket.socket() # 买手机 不传参数默认用的就是TCP协议 server.bind((‘127.0.0.1‘,8080)) # bind((host,port)) 插电话卡 绑定ip和端口 server.listen(5) # 开机 半连接池 conn, addr = server.accept() # 接听电话 等着别人给你打电话 阻塞 data = conn.recv(1024) # 听别人说话 接收1024个字节数据 阻塞 print(data) data = conn.recv(1024) # 听别人说话 接收1024个字节数据 阻塞 print(data) data = conn.recv(1024) # 听别人说话 接收1024个字节数据 阻塞 print(data)
import socket client = socket.socket() # 拿电话 client.connect((‘127.0.0.1‘,8080)) # 拨号 写的是对方的ip和port client.send(b‘hello‘) client.send(b‘world‘) client.send(b‘baby‘)

同时执行多条命令之后,得到的结果很可能只有一部分,在执行其他命令的时候又接收到之前执行的另外一部分结果,这就是粘包现象
PS:只有TCP有粘包的现象,UDP永远不会粘包
解决TCP粘包问题
import socket import subprocess import struct import json server = socket.socket() server.bind((‘127.0.0.1‘,8080)) server.listen(5) while True: conn, addr = server.accept() while True: try: cmd = conn.recv(1024) if len(cmd) == 0:break cmd = cmd.decode(‘utf-8‘) obj = subprocess.Popen(cmd,shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE) res = obj.stdout.read() + obj.stderr.read() d = ‘name‘:‘jason‘,‘file_size‘:len(res),‘info‘:‘asdhjkshasdad‘ json_d = json.dumps(d) # 1.先制作一个字典的报头 header = struct.pack(‘i‘,len(json_d)) # 2.发送字典报头 conn.send(header) # 3.发送字典 conn.send(json_d.encode(‘utf-8‘)) # 4.再发真实数据 conn.send(res) # conn.send(obj.stdout.read()) # conn.send(obj.stderr.read()) except ConnectionResetError: break conn.close()
import socket import struct import json client = socket.socket() client.connect((‘127.0.0.1‘,8080)) while True: msg = input(‘>>>:‘).encode(‘utf-8‘) if len(msg) == 0:continue client.send(msg) # 1.先接受字典报头 header_dict = client.recv(4) # 2.解析报头 获取字典的长度 dict_size = struct.unpack(‘i‘,header_dict)[0] # 解包的时候一定要加上索引0 # 3.接收字典数据 dict_bytes = client.recv(dict_size) dict_json = json.loads(dict_bytes.decode(‘utf-8‘)) # 4.从字典中获取信息 print(dict_json) recv_size = 0 real_data = b‘‘ while recv_size < dict_json.get(‘file_size‘): # real_size = 102400 data = client.recv(1024) real_data += data recv_size += len(data) print(real_data.decode(‘gbk‘)) """ 1.如何将对方发送的数据收干净 """
在解决粘包问题的时候 我们用到了struct模块来解决接收端不知道发送端将要传送的字节流的长度的问题
struct模块
该模块可以把一个类型,如数字,转成固定长度的bytes
>>> struct.pack(‘i‘,1111111111111) struct.error: ‘i‘ format requires -2147483648 <= number <= 2147483647 #这个是范围
import json,struct #假设通过客户端上传1T:1073741824000的文件a.txt #为避免粘包,必须自定制报头 header=‘file_size‘:1073741824000,‘file_name‘:‘/a/b/c/d/e/a.txt‘,‘md5‘:‘8f6fbf8347faa4924a76856701edb0f3‘ #1T数据,文件路径和md5值 #为了该报头能传送,需要序列化并且转为bytes head_bytes=bytes(json.dumps(header),encoding=‘utf-8‘) #序列化并转成bytes,用于传输 #为了让客户端知道报头的长度,用struck将报头长度这个数字转成固定长度:4个字节 head_len_bytes=struct.pack(‘i‘,len(head_bytes)) #这4个字节里只包含了一个数字,该数字是报头的长度 #客户端开始发送 conn.send(head_len_bytes) #先发报头的长度,4个bytes conn.send(head_bytes) #再发报头的字节格式 conn.sendall(文件内容) #然后发真实内容的字节格式 #服务端开始接收 head_len_bytes=s.recv(4) #先收报头4个bytes,得到报头长度的字节格式 x=struct.unpack(‘i‘,head_len_bytes)[0] #提取报头的长度 head_bytes=s.recv(x) #按照报头长度x,收取报头的bytes格式 header=json.loads(json.dumps(header)) #提取报头 #最后根据报头的内容提取真实的数据,比如 real_data_len=s.recv(header[‘file_size‘]) s.recv(real_data_len)
#_*_coding:utf-8_*_ #http://www.cnblogs.com/coser/archive/2011/12/17/2291160.html __author__ = ‘Linhaifeng‘ import struct import binascii import ctypes values1 = (1, ‘abc‘.encode(‘utf-8‘), 2.7) values2 = (‘defg‘.encode(‘utf-8‘),101) s1 = struct.Struct(‘I3sf‘) s2 = struct.Struct(‘4sI‘) print(s1.size,s2.size) prebuffer=ctypes.create_string_buffer(s1.size+s2.size) print(‘Before : ‘,binascii.hexlify(prebuffer)) # t=binascii.hexlify(‘asdfaf‘.encode(‘utf-8‘)) # print(t) s1.pack_into(prebuffer,0,*values1) s2.pack_into(prebuffer,s1.size,*values2) print(‘After pack‘,binascii.hexlify(prebuffer)) print(s1.unpack_from(prebuffer,0)) print(s2.unpack_from(prebuffer,s1.size)) s3=struct.Struct(‘ii‘) s3.pack_into(prebuffer,0,123,123) print(‘After pack‘,binascii.hexlify(prebuffer)) print(s3.unpack_from(prebuffer,0)) 关于struct的详细用法
基于UDP协议的socket
简单使用
import socket server = socket.socket(type=socket.SOCK_DGRAM) # UDP协议 server.bind((‘127.0.0.1‘,8080)) # UDP不需要设置半连接池 它也没有半连接池的概念 # 因为没有双向通道 不需要accept 直接就是通信循环 while True: data, addr = server.recvfrom(1024) print(‘数据:‘,data) # 客户端发来的消息 print(‘地址:‘,addr) # 客户端的地址 server.sendto(data.upper(),addr)
import socket client = socket.socket(type=socket.SOCK_DGRAM) # 不需要建立连接 直接进入通信循环 server_address = (‘127.0.0.1‘,8080) while True: client.sendto(b‘hello‘,server_address) data, addr = client.recvfrom(1024) print(‘服务端发来的数据‘,data) print(‘服务端的地址‘,addr)
QQ聊天的简单实现
#_*_coding:utf-8_*_ import socket ip_port=(‘127.0.0.1‘,8081) udp_server_sock=socket.socket(socket.AF_INET,socket.SOCK_DGRAM) udp_server_sock.bind(ip_port) while True: qq_msg,addr=udp_server_sock.recvfrom(1024) print(‘来自[%s:%s]的一条消息:\\033[1;44m%s\\033[0m‘ %(addr[0],addr[1],qq_msg.decode(‘utf-8‘))) back_msg=input(‘回复消息: ‘).strip() udp_server_sock.sendto(back_msg.encode(‘utf-8‘),addr)
#_*_coding:utf-8_*_ import socket BUFSIZE=1024 udp_client_socket=socket.socket(socket.AF_INET,socket.SOCK_DGRAM) qq_name_dic= ‘金老板‘:(‘127.0.0.1‘,8081), ‘哪吒‘:(‘127.0.0.1‘,8081), ‘egg‘:(‘127.0.0.1‘,8081), ‘yuan‘:(‘127.0.0.1‘,8081), while True: qq_name=input(‘请选择聊天对象: ‘).strip() while True: msg=input(‘请输入消息,回车发送,输入q结束和他的聊天: ‘).strip() if msg == ‘q‘:break if not msg or not qq_name or qq_name not in qq_name_dic:continue udp_client_socket.sendto(msg.encode(‘utf-8‘),qq_name_dic[qq_name]) back_msg,addr=udp_client_socket.recvfrom(BUFSIZE) print(‘来自[%s:%s]的一条消息:\\033[1;44m%s\\033[0m‘ %(addr[0],addr[1],back_msg.decode(‘utf-8‘))) udp_client_socket.close()
粘包成因
基于tcp协议特点的黏包现象成因
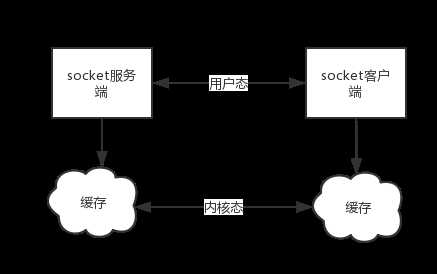
发送端可以是一K一K地发送数据,而接收端的应用程序可以两K两K地提走数据,当然也有可能一次提走3K或6K数据,或者一次只提走几个字节的数据。
也就是说,应用程序所看到的数据是一个整体,或说是一个流(stream),一条消息有多少字节对应用程序是不可见的,因此TCP协议是面向流的协议,这也是容易出现粘包问题的原因。
而UDP是面向消息的协议,每个UDP段都是一条消息,应用程序必须以消息为单位提取数据,不能一次提取任意字节的数据,这一点和TCP是很不同的。
怎样定义消息呢?可以认为对方一次性write/send的数据为一个消息,需要明白的是当对方send一条信息的时候,无论底层怎样分段分片,TCP协议层会把构成整条消息的数据段排序完成后才呈现在内核缓冲区。
例如基于tcp的套接字客户端往服务端上传文件,发送时文件内容是按照一段一段的字节流发送的,在接收方看了,根本不知道该文件的字节流从何处开始,在何处结束
此外,发送方引起的粘包是由TCP协议本身造成的,TCP为提高传输效率,发送方往往要收集到足够多的数据后才发送一个TCP段。若连续几次需要send的数据都很少,通常TCP会根据优化算法把这些数据合成一个TCP段后一次发送出去,这样接收方就收到了粘包数据。
相比于TCP, UDP不会发生粘包
UDP(user datagram protocol,用户数据报协议)是无连接的,面向消息的,提供高效率服务。 不会使用块的合并优化算法,, 由于UDP支持的是一对多的模式,所以接收端的skbuff(套接字缓冲区)采用了链式结构来记录每一个到达的UDP包,在每个UDP包中就有了消息头(消息来源地址,端口等信息),
这样,对于接收端来说,就容易进行区分处理了。 即面向消息的通信是有消息保护边界的。 对于空消息:tcp是基于数据流的,于是收发的消息不能为空,这就需要在客户端和服务端都添加空消息的处理机制,防止程序卡住,而udp是基于数据报的,即便是你输入的是空内容(直接回车),也可以被发送,udp协议会帮你封装上消息头发送过去。 不可靠不黏包的udp协议:udp的recvfrom是阻塞的,一个recvfrom(x)必须对唯一一个sendinto(y),收完了x个字节的数据就算完成,若是y;x数据就丢失,这意味着udp根本不会粘包,但是会丢数据,不可靠。
补充说明:
用UDP协议发送时,用sendto函数最大能发送数据的长度为:65535- IP头(20) – UDP头(8)=65507字节。用sendto函数发送数据时,如果发送数据长度大于该值,则函数会返回错误。(丢弃这个包,不进行发送)
用TCP协议发送时,由于TCP是数据流协议,因此不存在包大小的限制(暂不考虑缓冲区的大小),这是指在用send函数时,数据长度参数不受限制。而实际上,所指定的这段数据并不一定会一次性发送出去,如果这段数据比较长,会被分段发送,如果比较短,可能会等待和下一次数据一起发送。
总结
粘包现象只会发生在TCP协议中:
1.从表面上看,粘包问题主要是因为发送方和接受方的缓存机制,tcp协议面向流通信的特点.
2.实际上,主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据造成的
小练习:上传文件
客户端: # 获取电影存放文件夹绝对路径 # 获取电影列表 循环展示 # 用户选择 # 判断输入是否位数字 # 将字符串数字转化为整型 # 判断用户选择是否在列表范围内 # 获取用户想要上传的文件路径 # 拼接文件的绝对路径 # 获取文件大小 # 定一个字典 # 序列化字典 # 制作字典的报头 # 发送字典报头 # 发送字典 # 再发文件数据(打开文件循环发送 服务端: #接收字典报头 # 解析字典报头 # 再接收字典数据 # 获取数据长度 # 循环接收并写入文件 # 判断获取的数据是否小于0 # 接收数据并写入文件
import socket import json import struct server = socket.socket() server.bind((‘127.0.0.1‘,56289)) server.listen(5) while True: conn,addr = server.accept() while True: try: header_len = conn.recv(4) # 解析字典报头 header_len = struct.unpack(‘i‘,header_len)[0] # 再接收字典数据 header_dic = conn.recv(header_len) real_dic = json.loads(header_dic.decode(‘utf-8‘)) # 获取数据长度 total_size = real_dic.get(‘file_size‘) # 循环接收并写入文件 recv_size = 0 with open(real_dic.get(‘file_name‘),‘wb‘) as f: while recv_size < total_size: data = conn.recv(1024) f.write(data) recv_size += len(data) print(‘上传成功‘) except ConnectionResetError as e: print(e) break conn.close()
import socket import json import os import struct client = socket.socket() client.connect((‘127.0.0.1‘,56289)) while True: # 获取电影列表 循环展示 MOVIE_DIR = r‘C:\\Users\\admin\\Desktop\\复习视频\\day28视频‘ movie_list = os.listdir(MOVIE_DIR) # print(movie_list) for i,movie in enumerate(movie_list,1): print(i,movie) # 用户选择 choice = input(‘please choice movie to upload>>>:‘) # 判断是否是数字 if choice.isdigit(): # 将字符串数字转为int choice = int(choice) - 1 # 判断用户选择在不在列表范围内 if choice in range(0,len(movie_list)): # 获取到用户想上传的文件路径 path = movie_list[choice] # 拼接文件的绝对路径 file_path = os.path.join(MOVIE_DIR,path) # 获取文件大小 file_size = os.path.getsize(file_path) # 定义一个字典 res_d = ‘file_name‘:‘性感荷官在线发牌.mp4‘, ‘file_size‘:file_size, ‘msg‘:‘注意身体,多喝营养快线‘ # 序列化字典 json_d = json.dumps(res_d) json_bytes = json_d.encode(‘utf-8‘) # 1.先制作字典格式的报头 header = struct.pack(‘i‘,len(json_bytes)) # 2.发送字典的报头 client.send(header) # 3.再发字典 client.send(json_bytes) # 4.再发文件数据(打开文件循环发送) with open(file_path,‘rb‘) as f: for line in f: client.send(line) else: print(‘not in range‘) else: print(‘must be a number‘)
socketserver模块
socketserver内部使用IO多路复用以及“多线程”和“多进程”,从而实现并发处理多个客户端请求的scoket服务端。即,每个客户端请求连接到服务器时,socket服务端都会在服务器是创建一个“线程”或“进程”专门负责处理当前客户端的所有请求。
import socketserver class Myserver(socketserver.BaseRequestHandler): def handle(self): self.data = self.request.recv(1024).strip() print(" wrote:".format(self.client_address[0])) print(self.data) self.request.sendall(self.data.upper()) if __name__ == "__main__": HOST, PORT = "127.0.0.1", 9999 # 设置allow_reuse_address允许服务器重用地址 socketserver.TCPServer.allow_reuse_address = True # 创建一个server, 将服务地址绑定到127.0.0.1:9999 server = socketserver.TCPServer((HOST, PORT),Myserver) # 让server永远运行下去,除非强制停止程序 server.serve_forever()
import socket HOST, PORT = "127.0.0.1", 9999 data = "hello" # 创建一个socket链接,SOCK_STREAM代表使用TCP协议 with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as sock: sock.connect((HOST, PORT)) # 链接到客户端 sock.sendall(bytes(data + "\\n", "utf-8")) # 向服务端发送数据 received = str(sock.recv(1024), "utf-8")# 从服务端接收数据 print("Sent: ".format(data)) print("Received: ".format(received))
以上是关于网络编程的主要内容,如果未能解决你的问题,请参考以下文章