聚类分析
Posted shenben
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聚类分析相关的知识,希望对你有一定的参考价值。
2.1 kmeans算法要点
(1) $ k $ 值的选择
$ k $ 的选择一般是按照实际需求进行决定,或在实现算法时直接给定 $ k $ 值。
(2) 距离的度量
给定样本 $ x^(i) = \lbrace x_1^(i),x_2^(i),,...,x_n^(i), \rbrace 与 x^(j) = \lbrace x_1^(j),x_2^(j),,...,x_n^(j), \rbrace ,其中 i,j=1,2,...,m,表示样本数,n表示特征数 $ 。距离的度量方法主要分为以下几种:
(2.1)有序属性距离度量(离散属性 $ \lbrace1,2,3 \rbrace $ 或连续属性):
闵可夫斯基距离(Minkowski distance): \[ dist_mk(x^(i),x^(j))=(\sum_u=1^n |x_u^(i)-x_u^(j)|^p)^\frac1p \]
欧氏距离(Euclidean distance),即当 $ p=2 $ 时的闵可夫斯基距离: \[ dist_ed(x^(i),x^(j))=||x^(i)-x^(j)||_2=\sqrt\sum_u=1^n |x_u^(i)-x_u^(j)|^2 \]
曼哈顿距离(Manhattan distance),即当 $ p=1 $ 时的闵可夫斯基距离: \[ dist_man(x^(i),x^(j))=||x^(i)-x^(j)||_1=\sum_u=1^n |x_u^(i)-x_u^(j)| \]
(2.2)无序属性距离度量(比如飞机,火车,轮船):
VDM(Value Difference Metric): \[ VDM_p(x_u^(i),x_u^(j)) = \sum_z=1^k \left|\fracm_u,x_u^(i),zm_u,x_u^(i) - \fracm_u,x_u^(j),zm_u,x_u^(j) \right|^p \]
其中 $ m_u,x_u^(i) $ 表示在属性 $ u $ 上取值为 $ x_u^(i) $ 的样本数, $ m_u,x_u^(i),z $ 表示在第 $ z $ 个样本簇中属性 $ u $ 上取值为 $ x_u^(i) $ 的样本数, $ VDM_p(x_u^(i),x_u^(j)) $ 表示在属性 $ u $ 上两个离散值 $ x_u^(i) 与 x_u^(i) $ 的 $ VDM $ 距离 。
(2.3)混合属性距离度量,即为有序与无序的结合: \[ MinkovDM_p(x^(i),x^(j)) = \left( \sum_u=1^n_c | x_u^(i) - x_u^(j) | ^p + \sum_u=n_c +1^n VDM_p (x_u^(i),x_u^(j)) \right) ^\frac1p \]
其中含有 $ n_c $ 个有序属性,与 $ n-n_c $ 个无序属性。
本文数据集为连续属性,因此代码中主要以欧式距离进行距离的度量计算。
(3) 更新“簇中心”
对于划分好的各个簇,计算各个簇中的样本点均值,将其均值作为新的簇中心。
聚类分析的Matlab 程序—系统聚类
(1)计算数据集每对元素之间的距离,对应函数为pdistw.
调用格式:Y=pdist(X),Y=pdist(X,’metric’), Y=pdist(X,’distfun’),Y=pdist(X,’minkowski’,p)
说明:X是m*n的矩阵,metric是计算距离的方法选项:
metric=euclidean表示欧式距离(缺省值);
metric=seuclidean表示标准的欧式距离;
metric=mahalanobis表示马氏距离。
distfun是自定义的距离函数,p是minkowski距离计算过程中的幂次,缺省值为2.Y返回大小为m(m-1)/2的距离矩阵,距离排序顺序为(1,2),(1,3),…(m-1,m),Y也称为相似矩阵,可用squareform将其转化为方阵。
(2)对元素进行分类,构成一个系统聚类树,对应函数为linkage.
调用格式:Z=linkage(Y), Z=linkage(Y,’method’)
说明:Y是距离函数,Z是返回系统聚类树,method是采用的算法选项,
如下:method=single表示最短距离(缺省值);
complete表示最长距离;median表示中间距离法;
centroid表示重心法;average表示类平均法;
ward 表示离差平方和法(Ward法)。
(3)确定怎样划分系统聚类树,得到不同的类,对应的函数为cluster.
调用格式:T=cluster(Z,’cutoff’,c),T=cluster(Z,’maxclust’,n)
说明:Z是系统聚类树,为(m-1)*3的矩阵,c是阈值,n是类的最大数目,
maxclust是聚类的选项,cutoff是临界值,决定cluster函数怎样聚类。
例题1 利用系统聚类法对5个变量进行分类。
matlab程序
%Matlab运行程序:
X=[20,7;18,10;10,5;4,5;4,3];
Y=pdist(X);
SF=squareform(Y);
Z=linkage(Y,’single’);
dendrogram(Z);%显示系统聚类树
T=cluster(Z,‘maxclust‘,3)
例题2
%例2的程序设计:
X=[1 1;1 2;6 3;8 2;8 0];
Y=pdist(X);
SF=squareform(Y);
Z=linkage(Y,‘single‘);
dendrogram(Z);
T=cluster(Z,‘maxclust‘,3)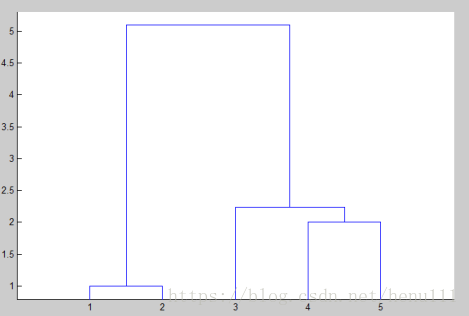
聚类分析案例
根据第三产业国内生产总值的9 项指标,对华东地区6 省1 市进行分类,原始数据如下表:

%Matlab程序如下:
X=[244.42 412.04 459.63 512.21 160.45 43.51 89.93 48.55 48.63
435.77 724.85 376.04 381.81 210.39 71.82 150.64 23.74 188.28
321.75 665.80 157.94 172.19 147.16 52.44 78.16 10.90 93.50
152.29 258.60 83.42 85.10 75.74 26.75 63.47 5.89 47.02
347.25 332.59 157.32 172.48 115.16 33.80 77.27 8.69 79.01
145.40 143.54 97.40 100.50 43.28 17.71 51.03 5.41 62.03
442.20 665.33 411.89 429.88 115.07 87.45 145.25 21.39 187.77 ]‘;
Y=pdist(X);
SF=squareform(Y);
Z=linkage(Y,‘average‘);
dendrogram(Z);
T=cluster(Z,‘maxclust‘,3)

K-means面临的问题以及解决办法:
1.它不能保证找到定位聚类中心的最佳方案,但是它能保证能收敛到某个解决方案(不会无限迭代)。
解决方法:多运行几次K-means,每次初始聚类中心点不同,最后选择方差最小的结果。
2.它无法指出使用多少个类别。在同一个数据集中,例如上图例,选择不同初始类别数获得的最终结果是不同的。
MATLAB函数Kmeans
使用方法:
Idx=Kmeans(X,K)
[Idx,C]=Kmeans(X,K)
[Idx,C,sumD]=Kmeans(X,K)
[Idx,C,sumD,D]=Kmeans(X,K)
[…]=Kmeans(…,’Param1’,Val1,’Param2’,Val2,…)
各输入输出参数介绍:
X: N*P的数据矩阵,N为数据个数,P为单个数据维度
K: 表示将X划分为几类,为整数
Idx: N*1的向量,存储的是每个点的聚类标号
C: K*P的矩阵,存储的是K个聚类质心位置
sumD: 1*K的和向量,存储的是类间所有点与该类质心点距离之和
D: N*K的矩阵,存储的是每个点与所有质心的距离
[…]=Kmeans(…,‘Param1‘,Val1,‘Param2‘,Val2,…)
这其中的参数Param1、Param2等,主要可以设置为如下:
1. ‘Distance’(距离测度)
‘sqEuclidean’ 欧式距离(默认时,采用此距离方式)
‘cityblock’ 绝度误差和,又称:L1
‘cosine’ 针对向量
‘correlation’ 针对有时序关系的值
‘Hamming’ 只针对二进制数据
2. ‘Start’(初始质心位置选择方法)
‘sample’ 从X中随机选取K个质心点
‘uniform’ 根据X的分布范围均匀的随机生成K个质心
‘cluster’ 初始聚类阶段随机选择10%的X的子样本(此方法初始使用’sample’方法)
matrix 提供一K*P的矩阵,作为初始质心位置集合
3. ‘Replicates’(聚类重复次数) 整数
使用案例:
data = [5.0 3.5 1.3 0.3 -1; 5.5 2.6 4.4 1.2 0; 6.7 3.1 5.6 2.4 1; 5.0 3.3 1.4 0.2 -1; 5.9 3.0 5.1 1.8 1; 5.8 2.6 4.0 1.2 0]; [Idx,C,sumD,D]=kmeans(data,3,‘dist‘,‘sqEuclidean‘,‘rep‘,3)
运行结果:
Idx =
1
2
3
1
3
2
C =
5.0000 3.4000 1.3500 0.2500 -1.0000
5.6500 2.6000 4.2000 1.2000 0
6.3000 3.0500 5.3500 2.1000 1.0000
sumD =
0.0300
0.1250
0.6300
D =
0.0150 11.4525 25.5350
12.0950 0.0625 3.5550
29.6650 5.7525 0.3150
0.0150 10.7525 24.9650
21.4350 2.3925 0.3150
10.2050 0.0625 4.0850
以上是关于聚类分析的主要内容,如果未能解决你的问题,请参考以下文章