JDK8 的FullGC 之 metaspace
Posted liuys635
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JDK8 的FullGC 之 metaspace相关的知识,希望对你有一定的参考价值。
前言:
由于最近写的程序在运行一段时间后出现高cpu,然后不可用故进而进行排查,最终定位到由于metaspace引起fullgc,不断的fullgc又占用大量cpu导致程序最终不可用。下面就是这次过程的分析排查和总结,便于以后温故,同时也希望能给遇到同样问题的同学一些参考。
一 jvm的内存分配情况:
Eden Survivor1 Survivor2 Tenured
Tenured 包含perm jdk<=7
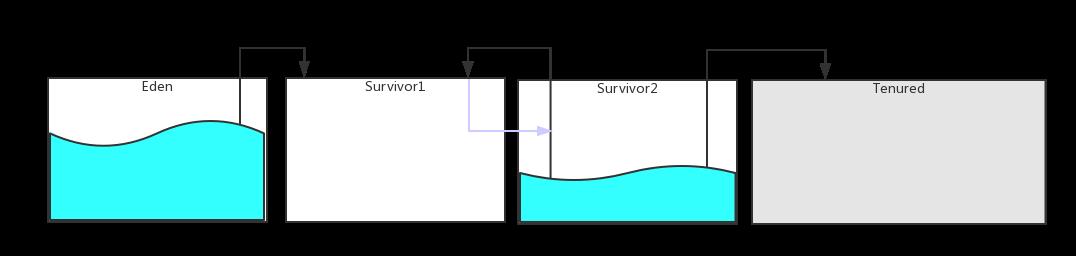
gc类型分为:minor gc 和 major gc ,major的速度比minor慢10倍至少
发生在 young(主要是Survivor)区的gc称为 minor gc
发生在 old(Tenured)区的gc称为 major gc
1.问题描述
jstat -gcutil 26819
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 43.75 0.00 42.22 67.19 50.93 4955 30.970 4890 3505.049 3536.020
可以看到M(metaSpace使用率)的值是67.19,metaSpace使用率为67.19;O为42.22,old区使用率为42.22
top -H -p 26819
26821 appdev 20 0 6864m 1.2g 13m R 87.6 7.5 53:40.18 java
26822 appdev 20 0 6864m 1.2g 13m R 87.6 7.5 53:41.40 java
26823 appdev 20 0 6864m 1.2g 13m R 87.6 7.5 53:43.64 java
26824 appdev 20 0 6864m 1.2g 13m R 85.6 7.5 53:41.59 java
26825 appdev 20 0 6864m 1.2g 13m R 85.6 7.5 53:43.82 java
26826 appdev 20 0 6864m 1.2g 13m R 85.6 7.5 53:40.47 java
26827 appdev 20 0 6864m 1.2g 13m R 85.6 7.5 53:45.05 java
26828 appdev 20 0 6864m 1.2g 13m R 83.6 7.5 53:39.08 java
可以发现26821到26828的cpu使用率很高,26821转为16进制为68c5
jstack 26819 > 26819.text
vim 26819.text 然后搜索68c5-68cc
"GC task thread#0 (ParallelGC)" os_prio=0 tid=0x00007f0aa401e000 nid=0x68c5 runnable
"GC task thread#1 (ParallelGC)" os_prio=0 tid=0x00007f0aa4020000 nid=0x68c6 runnable
"GC task thread#2 (ParallelGC)" os_prio=0 tid=0x00007f0aa4021800 nid=0x68c7 runnable
"GC task thread#3 (ParallelGC)" os_prio=0 tid=0x00007f0aa4023800 nid=0x68c8 runnable
"GC task thread#4 (ParallelGC)" os_prio=0 tid=0x00007f0aa4025800 nid=0x68c9 runnable
"GC task thread#5 (ParallelGC)" os_prio=0 tid=0x00007f0aa4027000 nid=0x68ca runnable
"GC task thread#6 (ParallelGC)" os_prio=0 tid=0x00007f0aa4029000 nid=0x68cb runnable
"GC task thread#7 (ParallelGC)" os_prio=0 tid=0x00007f0aa402a800 nid=0x68cc runnable
可以发现一致是full gc的线程在执行,占用cpu较高的资源,并且一致持续,表明一直达到了full gc的条件但是又不能回收掉内存从而占用大量cpu,导致程序不可用。
查看启动配置参数如下:
-Xms1000m -Xmx1000m -XX:MaxNewSize=256m -XX:ThreadStackSize=256 -XX:MetaspaceSize=38m -XX:MaxMetaspaceSize=380m
分析程序的逻辑,程序会加载很多jar到内存,程序是一个公共服务,很多同事会上传jar,然后程序把jar加载到classloader进行分析并保存。
2.问题分析:
根据jdk8的metaspace的fullgc的触发条件,初始metaspacesize是38m意味着当第一次加载的class达到38m的时候进行第一次gc(根据JDK 8的特性,G1和CMS都会很好地收集Metaspace区(一般都伴随着Full GC)。),然后jvm会动态调整 (gc后会进行调整)metaspacesize的大小。
JDK8: Metaspace
In JDK 8, classes metadata is now stored in the native heap
and this space is called Metaspace. There are some new flags added for
Metaspace in JDK 8:
-XX:MetaspaceSize=<NNN>
where <NNN> is the initial amount of space(the initial
high-water-mark) allocated for class metadata (in bytes) that may induce a
garbage collection to unload classes. The amount is approximate. After the
high-water-mark is first reached, the next high-water-mark is managed by
the garbage collector
-XX:MaxMetaspaceSize=<NNN>
where <NNN> is the maximum amount of space to be allocated for class
metadata (in bytes). This flag can be used to limit the amount of space
allocated for class metadata. This value is approximate. By default there
is no limit set.
-XX:MinMetaspaceFreeRatio=<NNN>
where <NNN> is the minimum percentage of class metadata capacity
free after a GC to avoid an increase in the amount of space
(high-water-mark) allocated for class metadata that will induce a garbage
collection.
-XX:MaxMetaspaceFreeRatio=<NNN>
where <NNN> is the maximum percentage of class metadata capacity
free after a GC to avoid a reduction in the amount of space
(high-water-mark) allocated for class metadata that will induce a garbage
collection.
By default class
metadata allocation is only limited by the amount of available native memory. We
can use the new option MaxMetaspaceSize to limit the amount of native memory
used for the class metadata. It is analogous(类似) to MaxPermSize. A garbage collection is induced to collect the dead classloaders
and classes when the class metadata usage reaches MetaspaceSize (12Mbytes on
the 32bit client VM and 16Mbytes on the 32bit server VM with larger sizes on
the 64bit VMs). Set MetaspaceSize to a higher value to delay the induced
garbage collections. After an induced garbage collection, the class metadata usage
needed to induce the next garbage collection may be increased.
根据这段描述可以知道:
1.当metadata usage reaches MetaspaceSize(默认MetaspaceSize在64为server上是20.8m)就会触发gc;
2.XX:MinMetaspaceFreeRatio是用来避免下次申请的空闲metadata大于暂时拥有的空闲metadata而触发gc,举个例子就是,当metaspacesize的使用大小达到了第一次设置的初始值6m,这时进行进行扩容(之前已经做过MinMetaspaceExpansion和MaxMetaspaceExpansion扩展,但还是失败),然后gc后,由于回收调的内存很小,然后计算((待commit内存)/(待commit内存+已经commmited内存) ==40%,(待commit内存+已经commmited内存)大于了metaspaceSize那么将尝试做扩容,也就是增大触发metaspaceGC的阈值,不过这个增量至少是MinMetaspaceExpansion才会做,不然不会增加这个阈值) ,这个参数主要是为了避免触发metaspaceGC的阈值和gc之后committed的内存的量比较接近,于是将这个阈值(metaspaceSize)进行扩大,尽量减小下次gc的几率。
3.同理-XX:MaxMetaspaceFreeRatio(默认70)是用来避免下次申请的空闲metadata很小,远远小于现在的空闲内存从而导致gc。主要作用是减小不必要的内存占用空间。
jdk8的metaspace引发的fullgc:
jdk8使用metaspace代替之前的perm,metaspace使用native memory,默认情况下使用的最大大小是系统内存大小,当然也可以使用-XX:MaxMetaspaceSize设置最大大小,这个设置和之前的max perm size是一样的。同时当设置-XX:MaxMetaspaceSize这个参数后,我们也可以实现和max perm引起oom的问题。
We can achieve the famed OOM error by setting the MaxMetaspaceSize argument to JVM and running the sample program provided.
metaspaceSize默认初始大小:
MetaspaceSize (12Mbytes on the 32bit client VM and 16Mbytes on the 32bit server VM with larger sizes on the 64bit VMs).
可以通过-XX:MetaspaceSize 设置我们需要的初始大小,设置大点可以增加第一次达到full gc的时间。
ps:下面是调整了下参数重启的进程,和上面的进程Id有出入。
jstat -gc 1706
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
31744.0 32768.0 0.0 21603.6 195584.0 192805.8 761856.0 384823.3 467712.0 309814.3 65536.0 36929.1 101 2.887 3 1.224 4.112
分析:MC是已经commited的内存,MU是当前使用的内存。这里有个疑惑就是MC是不是就是metaspace已经总共使用的内存,因为这个值已经达到了maxmetaspacesize,同时为什么mu不是和mc一样我猜测是由于碎片内存导致,这里有知道的同学可以告诉我下。在达到maxmetaspacesize的时候执行了3次fullgc。但是接下来由于不断申请内存,不断fullgc,fullgc不能回收内存,这时候fullgc的频率增大很多。在接下来 top -H -p 1706查看cpu可以看到大量高cpu进程,通过jstack查看都是在进行fullgc。
jmap -clstats 1706
第一次:total = 131 8016 13892091 N/A alive=45, dead=86 N/A
第二次:total = 1345 37619 77242171 N/A alive=1170, dead=175 N/A
alive的classloader基本都是自己创建的
classLoader不断增加,每次gc并没有回收掉classloader
VM中的Class只有满足以下三个条件,才能被GC回收,也就是该Class被卸载(unload):
- 该类所有的实例都已经被GC,也就是JVM中不存在该Class的任何实例。
- 加载该类的ClassLoader已经被GC。ClassLoader被回收需要所有ClassLoader的所有类的实例都被回收。
- 该类的java.lang.Class 对象没有在任何地方被引用,如不能在任何地方通过反射访问该类的方法
jcmd 1706 GC.class_stats | awk ‘print $13‘ | sort | uniq -c | sort -nrk1 > topclass.txt
通过自定义的classloader加载的类重复多次,并且数量一直增加。
看到大量的类重复数量
gc日志分析:
第一次fullgc:
[Heap Dump (before full gc): , 0.4032181 secs]2018-01-10T16:37:44.658+0800: 21.673: [Full GC (Metadata GC Threshold) [PSYoungGen: 14337K->0K(235520K)] [ParOldGen: 18787K->30930K(761856K)] 33125K->30930K(997376K), [Metaspace: 37827K->37827K(1083392K)], 0.1360661 secs] [Times: user=0.65 sys=0.04, real=0.14 secs]
主要是Metaspace这里:[Metaspace: 37827K->37827K(1083392K)] 达到了我们设定的初始值38m,并且gc并没有回收掉内存。1083392K这个值怀疑是使用了CompressedClassSpaceSize = 1073741824 (1024.0MB)这个导致的。
第四次fullgc:
[Heap Dump (before full gc): , 5.3642805 secs]2018-01-10T16:53:43.811+0800: 980.825: [Full GC (Metadata GC Threshold) [PSYoungGen: 21613K->0K(231424K)] [ParOldGen: 390439K->400478K(761856K)] 412053K->400478K(993280K), [Metaspace: 314108K->313262K(1458176K)], 1.2320834 secs] [Times: user=7.86 sys=0.06, real=1.23 secs]
主要是Metaspace这里:[Metaspace: 314108K->313262K(1458176K)]达到了我们设定的MinMetaspaceFreeRatio,并且gc几乎没有回收掉内存。1458176K这个值是CompressedClassSpaceSize = 1073741824 (1024.0MB)和 MaxMetaspaceSize = 503316480 (480.0MB)的和。
后面就是频率很快的重复fullgc。
3.问题解决:
有了以上基础,就知道怎么解决这次遇到的问题了。
总结下原因:classloader不断创建,classloader不断加载class,之前的classloader和class在fullgc的时候没有回收掉。
- 程序避免创建重复classloader,减少创建classLoader的数量。
- 增大XX:MinMetaspaceFreeRatio(默认40)的大小,可以看到现在是(100-67.19)。
- 设置更大的maxmetaspaceSize。
jdk8metadataspace参考:
http://www.sczyh30.com/posts/Java/jvm-metaspace/
http://blog.csdn.net/ouyang111222/article/details/53688986
http://lovestblog.cn/blog/2016/10/29/metaspace/
https://bugs.openjdk.java.net/browse/JDK-8151845
http://blog.csdn.net/ouyang111222/article/details/53688986
https://blogs.oracle.com/poonam/about-g1-garbage-collector%2c-permanent-generation-and-metaspace
http://zhuanlan.51cto.com/art/201706/541920.htm
http://blog.yongbin.me/2017/03/20/jaxb_metaspace_oom/
延伸阅读
jdk中触发gc的条件:
1,System.gc()方法的调用
system.gc(), 此方法的调用是建议JVM进行Full GC,虽然只是建议而非一定,但很多情况下它会触发 Full GC,从而增加Full GC的频率,也即增加了间歇性停顿的次数。强烈建议能不使用此方法就别使用,让虚拟机自己去管理它的内存,可通过通过-XX:+ DisableExplicitGC来禁止RMI调用System.gc。
2,老年代代空间(old/Tenured)不足
老年代空间只有在新生代对象转入及创建为大对象、大数组时才会出现不足的现象,当执行Full GC后空间仍然不足,则抛出如下错误:java.lang.OutOfMemoryError: Java heap space 为避免以上两种状况引起的Full GC,调优时应尽量做到让对象在Minor GC阶段被回收、让对象在新生代多存活一段时间及不要创建过大的对象及数组。
3,永生区(perm)空间不足(jdk<=7 ,在jdk8里面是metaspace ,后面会重点描述)
JVM规范中运行时数据区域中的方法区,在HotSpot虚拟机中又被习惯称为永生代或者永生区,Permanet Generation中存放的为一些class的信息、常量、静态变量等数据,当系统中要加载的类、反射的类和调用的方法较多时,Permanet Generation可能会被占满,在未配置为采用CMS GC的情况下也会执行Full GC。如果经过Full GC仍然回收不了,那么JVM会抛出如下错误信息:java.lang.OutOfMemoryError: PermGen space 为避免Perm Gen占满造成Full GC现象,可采用的方法为增大Perm Gen空间或转为使用CMS GC。
4,CMS GC时出现promotion failed和concurrent mode failure
对于采用CMS进行老年代GC的程序而言,尤其要注意GC日志中是否有promotion failed和concurrent mode failure两种状况,当这两种状况出现时可能会触发Full GC。promotion failed是在进行Minor GC时,survivor space放不下、对象只能放入老年代,而此时老年代也放不下造成的;concurrent mode failure是在执行CMS GC的过程中同时有对象要放入老年代,而此时老年代空间不足造成的(有时候“空间不足”是CMS GC时当前的浮动垃圾过多导致暂时性的空间不足触发Full GC)。对措施为:增大survivor space、老年代空间或调低触发并发GC的比率(-XX:CMSInitiatingOccupancyFraction=70,预留空间为70%),但在JDK 5.0+、6.0+的版本中有可能会由于JDK的bug29导致CMS在remark完毕后很久才触发sweeping动作。对于这种状况,可通过设置-XX: CMSMaxAbortablePrecleanTime=5(单位为ms)来避免。
5、统计得到的Minor GC晋升到旧生代(Eden到S2和S1到S2的和)的平均大小大于老年代的剩余空间
这是一个较为复杂的触发情况,Hotspot为了避免由于新生代对象晋升到旧生代导致旧生代空间不足的现象,在进行Minor GC时,做了一个判断,如果之前统计所得到的Minor GC晋升到旧生代的平均大小大于旧生代的剩余空间,那么就直接触发Full GC。例如程序第一次触发Minor GC后,有6MB的对象晋升到旧生代,那么当下一次Minor GC发生时,首先检查旧生代的剩余空间是否大于6MB,如果小于6MB,则执行Full GC。当新生代采用PS GC时,方式稍有不同,PS GC是在Minor GC后也会检查,例如上面的例子中第一次Minor GC后,PS GC会检查此时旧生代的剩余空间是否大于6MB,如小于,则触发对旧生代的回收。
除了以上4种状况外,对于使用RMI来进行RPC或管理的Sun JDK应用而言,默认情况下会一小时执行一次Full GC。可通过在启动时通过- java -Dsun.rmi.dgc.client.gcInterval=3600000来设置Full GC执行的间隔时间或通过-XX:+ DisableExplicitGC来禁止RMI调用System.gc。
6、堆中分配很大的对象
所谓大对象,是指需要大量连续内存空间的java对象,例如很长的数组,此种对象会直接进入老年代,而老年代虽然有很大的剩余空间,但是无法找到足够大的连续空间来分配给当前对象,此种情况就会触发JVM进行Full GC。
为了解决这个问题,CMS垃圾收集器提供了一个可配置的参数,即-XX:+UseCMSCompactAtFullCollection开关参数,用于在“享受”完Full GC服务之后额外免费赠送一个碎片整理的过程,空间碎片问题没有了,但提顿时间不得不变长了,JVM设计者们还提供了另外一个参数 -XX:CMSFullGCsBeforeCompaction,这个参数用于设置在执行多少次不压缩的Full GC后,跟着来一次带压缩的。
延伸阅读参考:
http://engineering.xueqiu.com/blog/2015/06/25/jvm-gc-tuning/
http://www.cnblogs.com/redcreen/archive/2011/05/04/2037057.html
http://blog.csdn.net/chenleixing/article/details/46706039
以上是关于JDK8 的FullGC 之 metaspace的主要内容,如果未能解决你的问题,请参考以下文章