zookeeper
Posted zj-xu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了zookeeper相关的知识,希望对你有一定的参考价值。
功课:
事务是由一组SQL语句组成的逻辑处理单元,事务具有以下4个属性,通常简称为事务的ACID属性。
Atomic(原子性)
Consistency(一致性)
Isolation(隔离性)
Durability(持久性)
CAP原则又称CAP定理,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。
简介:
它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等
zookeeper=文件系统+监听通知机制
ZooKeeper是一个分布式小文件系统,并且被设计为高可用性。通过选举算法和集群复制可以避免单点故障3,由于是文件系统,所以即使所有的ZooKeeper节点全部挂掉,数据也不会丢失,重启服务器之后,数据即可恢复。另外ZooKeeper的节点更新是原子的,也就是说更新不是成功就是失败。通过版本号,ZooKeeper实现了更新的乐观锁4,
(解析:文件系统 文件系统由三部分组成:与文件管理有关软件、被管理文件以及实施文件管理所需数据结构。从系统角度来看,文件系统是对文件存储器空间进行组织和分配,负责文件存储并对存入的文件进行保护和检索的系统。分布式文件系统(Distributed File System)是指文件系统管理的物理存储资源不一定直接连接在本地节点上)
乐观锁:每次获取数据的时候,都不会担心数据被修改,所以每次获取数据的时候都不会进行加锁,但是在更新数据的时候需要判断该数据是否被别人修改过。如果数据被其他线程修改,则不进行数据更新,如果数据没有被其他线程修改,则进行数据更新
悲观锁; 每次获取数据的时候,都会担心数据被修改,所以每次获取数据的时候都会进行加锁,确保在自己使用的过程中数据不会被别人修改,使用完成后进行数据解锁。由于数据进行加锁,期间对该数据进行读写的其他线程都会进行等待
Zookeeper维护一个类似文件系统的数据结构:
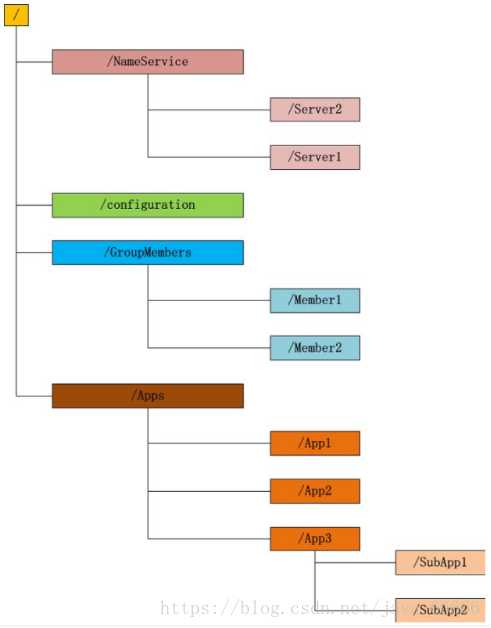
每个子目录项如 NameService 都被称作为 znode(目录节点),和文件系统一样,我们能够自由的增加、删除znode,在一个znode下增加、删除子znode,唯一的不同在于znode是可以存储数据的。
有四种类型的znode:
-
PERSISTENT-持久化目录节点
客户端与zookeeper断开连接后,该节点依旧存在
-
PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
-
EPHEMERAL-临时目录节点
客户端与zookeeper断开连接后,该节点被删除
-
EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
2、 监听通知机制
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、被删除、子目录节点增加删除)时,zookeeper会通知客户端。
Zookeeper能做什么
可以实现诸如分布式应用配置管理、统一命名服务、状态同步服务、集群管理等功能
,如果我们要改变程序的配置文件,需要逐台机器去修改,非常麻烦,现在把这些配置全部放到zookeeper上去,保存在 zookeeper 的某个目录节点中,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 zookeeper 的通知,然后从 zookeeper 获取新的配置信息应用到系统中。
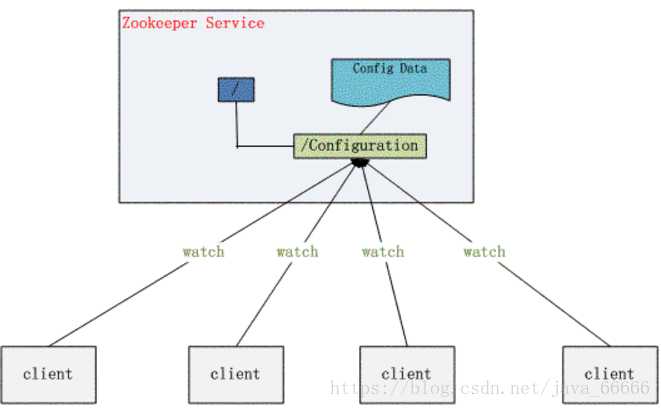
zookeeper分布式一致性的特点:
顺序一致性:客户端访问zookeeper的一个节点,发起事务,是排着队到leader那让他发起提议,一个一个来;
单一视图:任何节点上的数据都是一样的,所以客户端访问任意节点都看到是相同的数据。
可靠性:给了一个客户端反馈,同意他的请求,那么就是真的同意了。
实时性:zookeeper保证在一定时间内,比如5秒之后你可以访问到最新数据。这是最终一致性导致的。
特点:
-
简单的数据模型:就是文件夹的树形结构
-
可以构建集群:
-
顺序访问:客户端提出了一个事务请求,会获得一个唯一的id编号,用于操作的先后顺序;
-
高性能:这里指的是读取数据
3. zookeeper的几个角色
zookeeper有几个角色:leader、follower、observer;其中observer一般不配置,它也不参与投票,observer可以在不影响写性能的情况下提升集群的读性能;
zookeeper中节点有实体机器节点,还有znode数据节点。znode数据节点指的是目录文件夹。数据节点有永久数据节点和临时节点。
以上是关于zookeeper的主要内容,如果未能解决你的问题,请参考以下文章