避免缓存中出现脏数据分析
Posted tuhooo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了避免缓存中出现脏数据分析相关的知识,希望对你有一定的参考价值。
缓存能解决的问题
-
提升性能
绝大多数情况下,select 是出现性能问题最大的地方。一方面,select 会有很多像 join、group、order、like 等这样丰富的语义,而这些语义是非常耗性能的;另一方面,大多 数应用都是读多写少,所以加剧了慢查询的问题。
分布式系统中远程调用也会耗很多性能,因为有网络开销,会导致整体的响应时间下降。为了挽救这样的性能开销,在业务允许的情况(不需要太实时的数据)下,使用缓存是非常必要的事情。
-
缓解数据库压力
当用户请求增多时,数据库的压力将大大增加,通过缓存能够大大降低数据库的压力。
缓存的适用场景
-
对于数据实时性要求不高
对于一些经常访问但是很少改变的数据,读明显多于写,适用缓存就很有必要。比如一些网站配置项。
-
对于性能要求高
比如一些秒杀活动场景。
缓存三种模式
一般来说,缓存有以下三种模式:
-
Cache Aside 更新模式
-
Read/Write Through 更新模式
-
Write Behind Caching 更新模式
缓存的各种操作
写就是更新,更新就是写。
读
- R_1:先读缓存,读到了缓存则返回,读不到缓存则去读数据库,直接返回读到数据,不操作缓存
- R_2:先读缓存,读到了缓存则返回,读不到缓存则去读数据库,将数据库中读到的数据更新到缓存中
写
- W_1:先写缓存,再写数据库
- W_2:先写数据库,库再写缓存
- W_3:先删除缓存,再写数据库
- W_4:先写数据库,再删缓存
两种不同的读操作是互斥的,而写操作细分为:删除和更新,这两种操作也是互斥的,所以可能的组合其实只有这四种:
- (R_1,W_1)
- (R_1,W_2)
- (R_2,W_3)
- (R_2,W_4)
排列组合,逐个分析
由于 R_1 在读的时候不去操作缓存的,所以写操作要包括写缓存的操作。也就是有两种情况:(R_1,W_1),(R_1,W_2)
(R_1,W_1)分析
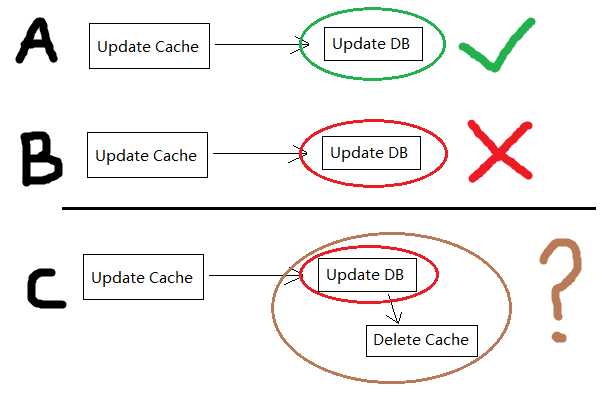
A:先写缓存,再写数据库,数据库写入成功,这是最理想的状况,并发的写操作不会带来脏数据
B:先写缓存,再写数据库,最后数据库写入失败,导致缓存中写入了脏数据
C:C 在 B 的基础上做了改良,当发现写数据库失败时,旋即把缓存删除掉;缺点就是在【写缓存结束,发现更新失败】这个时间区间内,缓存中的其实是脏数据
结论:(R_1,W_1)可用性存疑
(R_1,W_2)分析
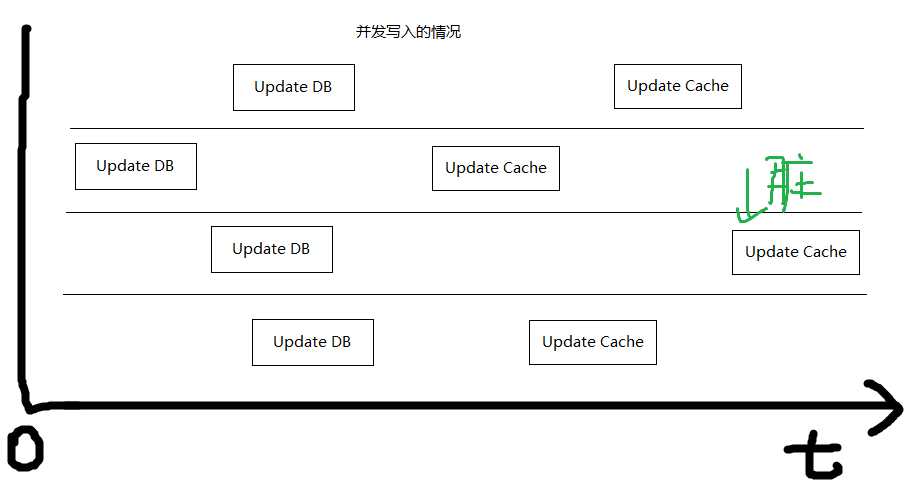
这个图一画完,其实你就知道了,先写数据库,再写缓存这种策略很容易就产生缓存的脏数据了,很好复现。
结论:(R_1,W_2)完全不可用,PASS
(R_2,W_3)分析
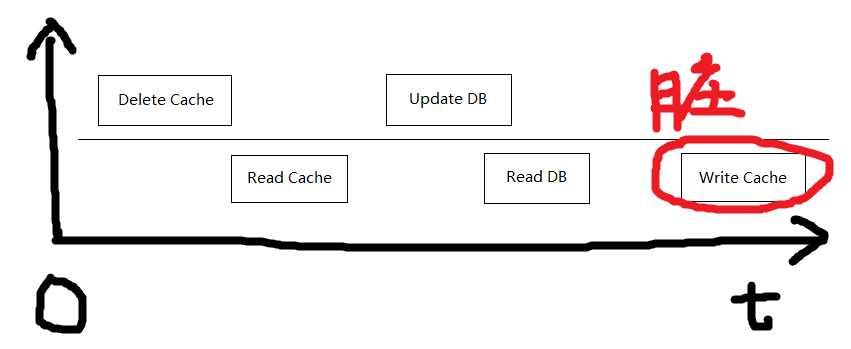
(R_2,W_3)这种操作和(R_1,W_1)中场景 C 有点类似,就是在【删除缓存,更新 DB 结束】这段时间内,发现缓存没了,然后读库,再写缓存,其实是有脏数据的。
(R_2,W_4)分析
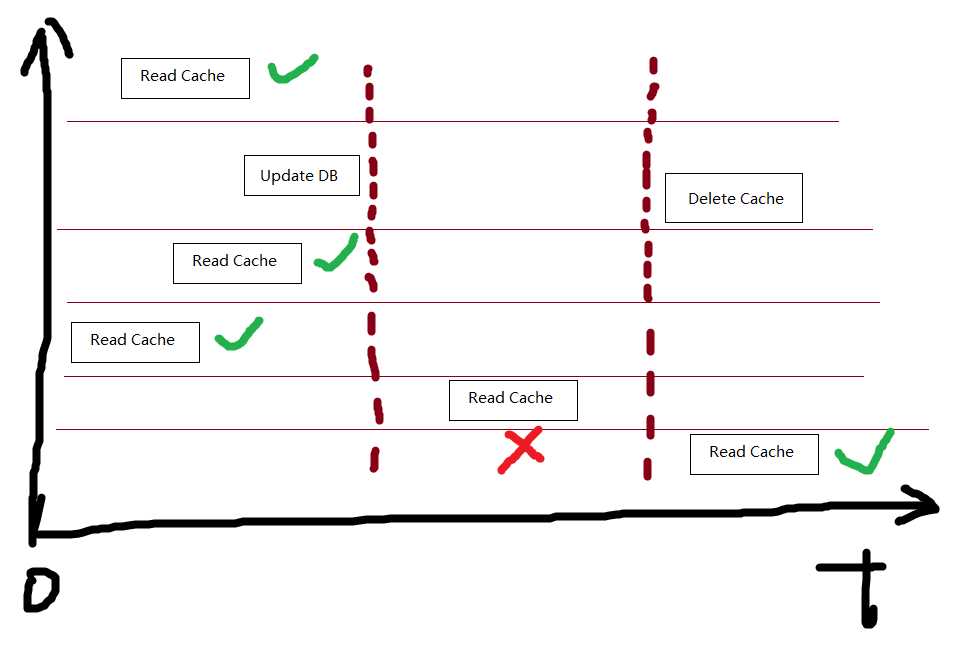
先更新数据,后删除缓存会脏成脏数据的时间范围是:【更新数据库成功,删除缓存】这段时间,这个时间间隔非常短,所以策略是最优的。
结论:(R_2,W_4)策略最优
整体结论:
(R_2,W_4) > (R_2,W_3)= (R_1,W_1) > (R_1,W_2)
思考
对脏数据的理解,什么是脏数据:缓存中的数据和 DB 中的数据不一致即为脏数据。
正是由于更新 DB 和更新 Cache 无法做到原子性,所以才会导致数据出现不一致的情况。
所以缓存的脏数据从根本上是无法避免的,只能尽量减少发生的概率。
减少发生概率的方法就是,减少出现不一致概率的时间区间。
一定要有意识,应用的所有读写都是并发的,要在这个背景下去考虑问题,所以画图理解是最好的办法。
数据库的读写要有基本概念:速度快慢,一致性,并发,阻塞等。
暂时搞懂了这个问题,下一步就是写代码验证。
以上是关于避免缓存中出现脏数据分析的主要内容,如果未能解决你的问题,请参考以下文章