SSD
Posted edbean
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SSD相关的知识,希望对你有一定的参考价值。
论文信息
Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg. SSD: Single Shot MultiBox Detector. ECCV 2016.
https://arxiv.org/abs/1512.02325
前言
本文算是一种one stage approach, 主要的开创性贡献是使用多长宽比和scale的feature map进行检测, 因为其尺寸不一, 自然也容易发现各个尺度的object. 作为one stage模型, 其低计算复杂度也是自然的.
Introduction
本文是第一个并不用proposal且之后不需要sample的模型, 并且本文的模型和需要此操作的模型精度相近.
本文的贡献在于使用一个小的像素块来预测class和location offsets, 且每个不同的map都使用不同的像素块.
主要的几个特点是高速(比YOLOv1快), 高精度(和Faster R-CNN相近), 对于不同的map使用不同的小像素块提取信息, 训练时end-to-end的.
The Single Shot Detector (SSD)
Model
生成固定数量的bbox和class存在的score, 其后跟一个NMS来最终整合结果. 前半部分时基于分类网络的标准结构(本文称作base network), 后层时辅助结构, 结构图如下:
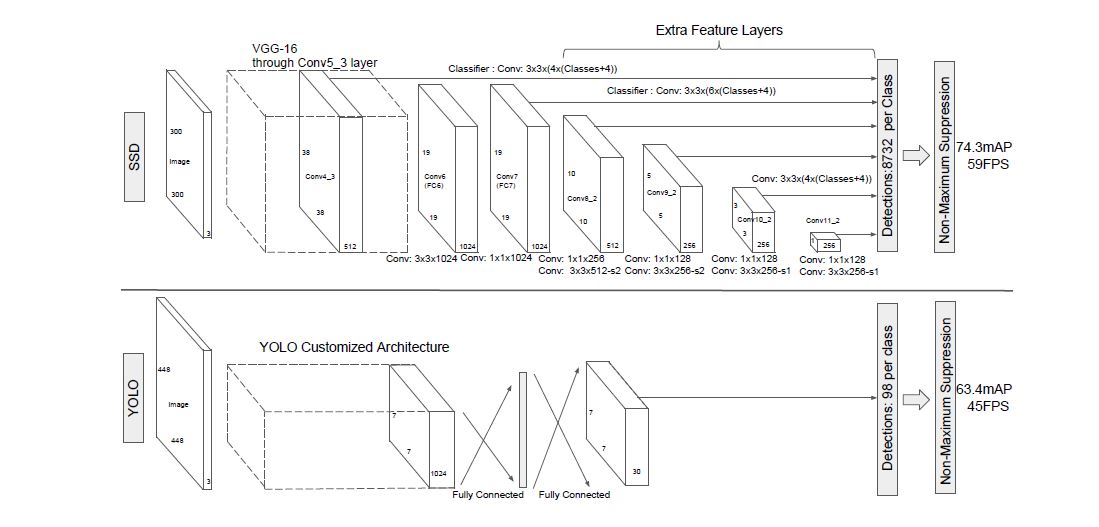
Multi-scale feature maps for detection
对base后跟上卷积层, 这些卷积层连续地减小feature map(FM for short), 因此可以使模型对多尺寸地物体预测, 因此每一层预测地内容可能都不一样.
Convolutional predictors for detection
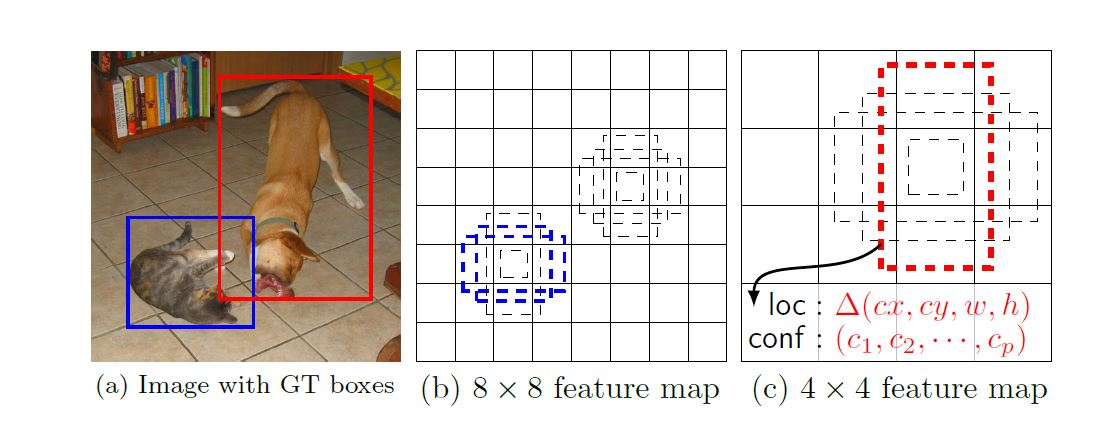
将每个后加的卷积层分成产生一系列固定的, 对于一个\(m \times n\)的\(p\)channel的FM, 基本的预测块是一个小的\(3 \times 3 \times p\)像素块. 这些小的像素块都能产生score和location offset. 这些像素块会在所有的FM像素点生成.
Default boxes and aspect ratios
同样还是上图中, 每个cell(像素块)都会产生\(k\)个bbox, 因为bbox使在FM上以卷积的方式平铺(The default boxes tile the feature map in a convolutional manner, 我也每想明白这句话但不影响以后的理解), 因此bbox对于cell的相对位置是固定的, 同时bbox还是和以前一样预测\(c + 4\)个结果, 因此每个cell含有\((c + 4)k\)个输出, 一个FM总的输出就是\((C + 4)kmn\).
Training
SSD和其他two stage模型最大的不同是, SSD需要将ground truth(GT for short)指定到FM的输出上去, 而two stage是proposal已知GT信息不需再次对应指定.
一旦将GT分配到FM所对应的位置上以后就可以end-to-end地优化了.
Matching strategy
训练过程中需要决定哪一个bbox对应GT, 本文首先计算bbox的, 其后去所有大于阈值的bbox, 而不是直接选择overlapping score最高的那个bbox.
Training objective
首先让\(x_ij^p = 1, 0\)代表第\(i\)个box是否对应class \(p\)的第\(j\)个GT, 要注意的是本文允许\(\sum\limits_ix_ij^p \geq 1\), 最终loss是由分类和定位loss加权构成的:
\[
L(x, c, l, g) = \frac1N(L_conf(x, c) + \alpha L_loc(x, l, g))
\]
其中\(N\)代表最终剩下bbox的数量, \(L_loc\)就是使用smooth L1的bbox regression loss, 而\(L_conf\)就是多class的softmax loss.
Choosing scales and aspect ratios for default boxes
此前有工作使用浅层FM来提升分类质量, 因为浅层包含更多细节(纹理等). 还有工作发现从FM添加全局背景池化(global context pool)能提升质量.
本文同时使用浅层和深层的FM. 如第二张图就是两个层次不同的FM, 实际操作时我们能使用更多的FM.
在不同深度产生的FM我们知道感受野各不相同, 但SSD并不对感受野敏感, 只需要知道粗略位置即可使bbox对其优化, 假设有\(m\)张FM, 那么就让scale为:
\[
s_k = s_min + \fracs_max - s_minm - 1(k - 1), k \in [1, m]
\]
例如, \(s_min = 0.2, s_max = 0.9\)就代表所有FM对于原始图像来说最小scale为0.2, 最大为0.9. 另外作者还使每个bbox都有多个aspect ratio: \(a_r \in 1, 2, 3, \frac12, \frac13\), 这样我们就得到了最终宽和高:
\[
w_k^a = s_k\sqrta_r, h_k^a = s_k / \sqrta_r
\]
这样就满足了以上的条件, 另外对于aspect ratio, 还额外加了一个bbox scale: \(s_k' = \sqrts_ks_k + 1\)
对于bbox取坐标\((\fraci + 0.5|f_k|, \fracj + 0.5|f_k|)\), 因为\(i, j\)是index, 加上0.5之后就正好是其中心, 最后再根据scale \(|f_k|\)缩放得到中心位置.
Hard negative mining
限制negative: positive = 3: 1.
Data augmentation
在以下几点选项中随机sample送入网络:
- 使用整个原始图像.
- 选取IOU分别是0.1, 0.3, 0.5, 0.7和0.9的部分物体训练.
- 随机剪裁.
并且以0.5的概率随机水平翻转.
Experiments
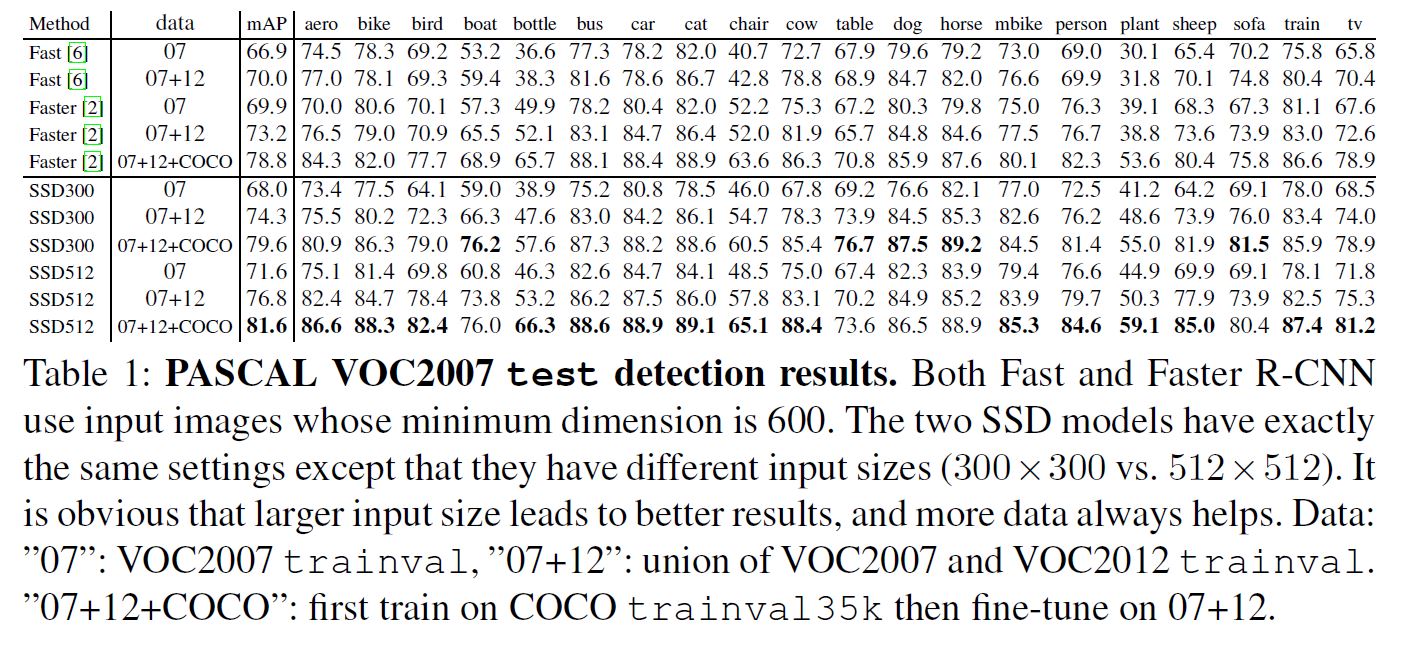
Model analysis
其中atrous指DeepLab-LargeFOV中的方法.

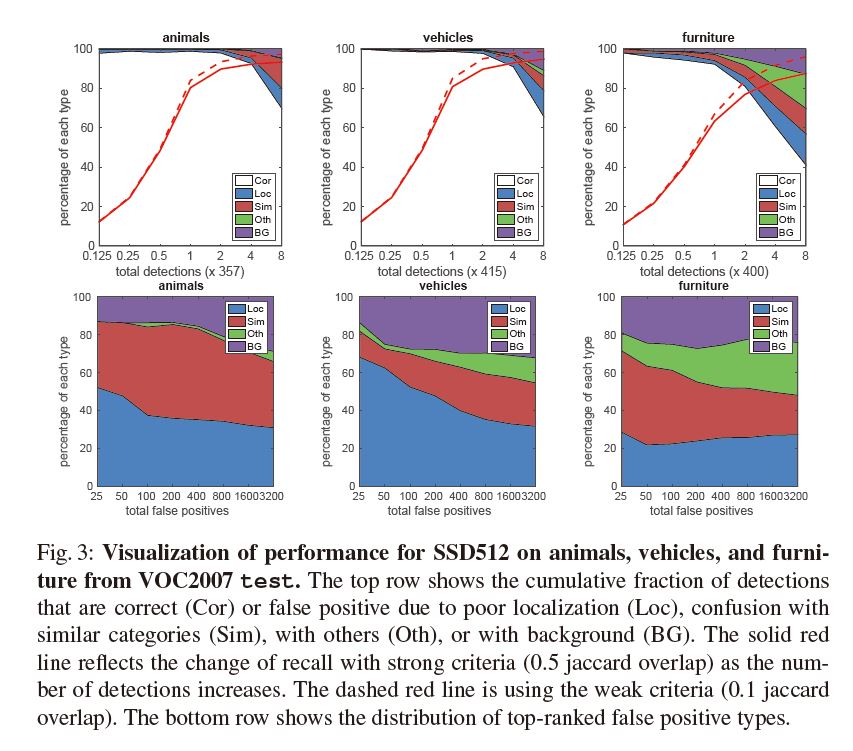
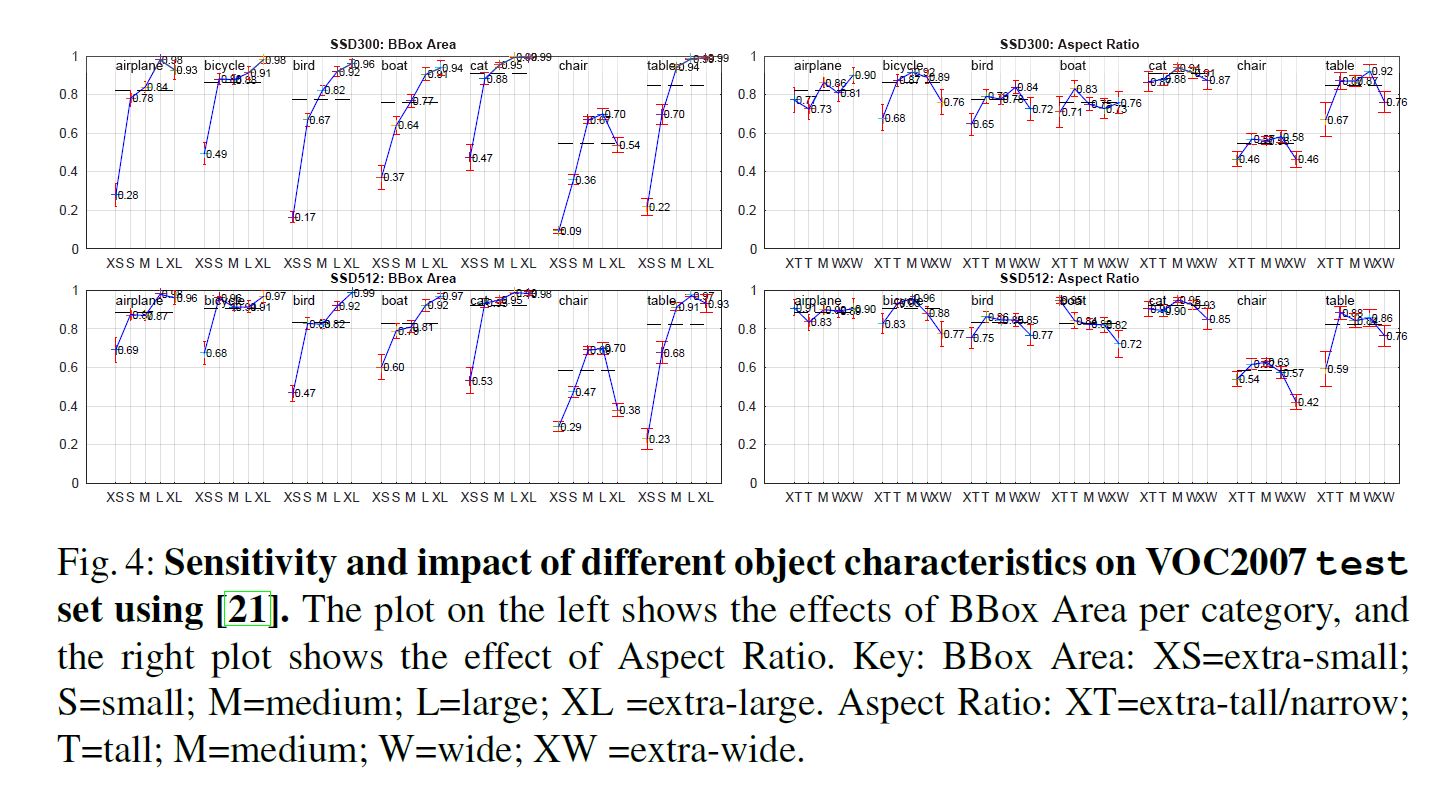

其他数据集
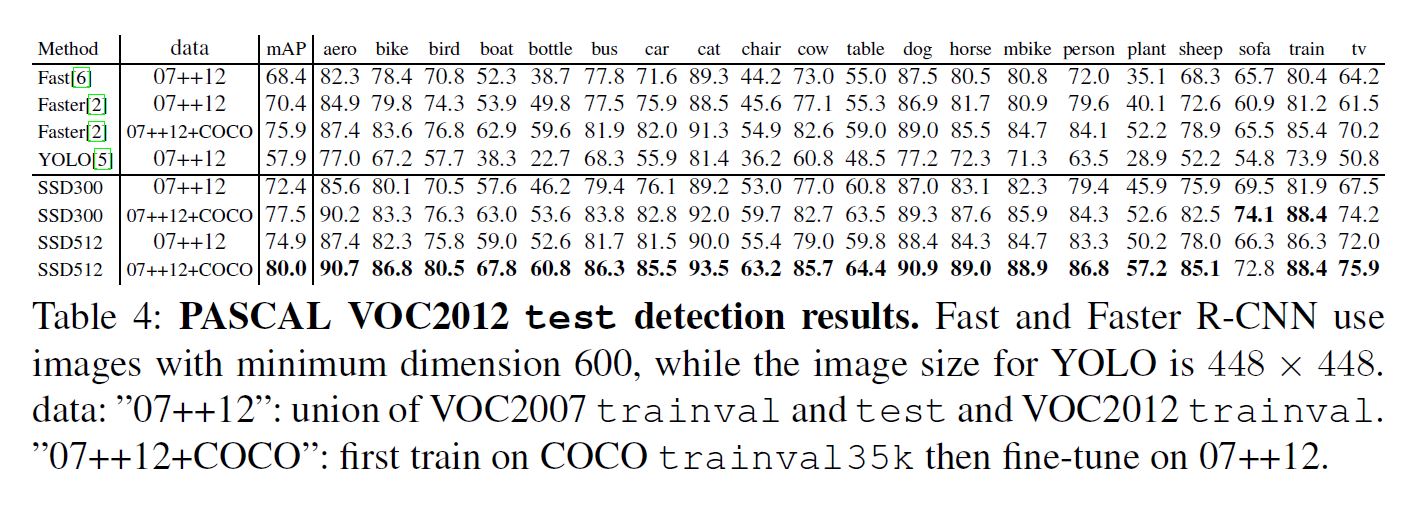
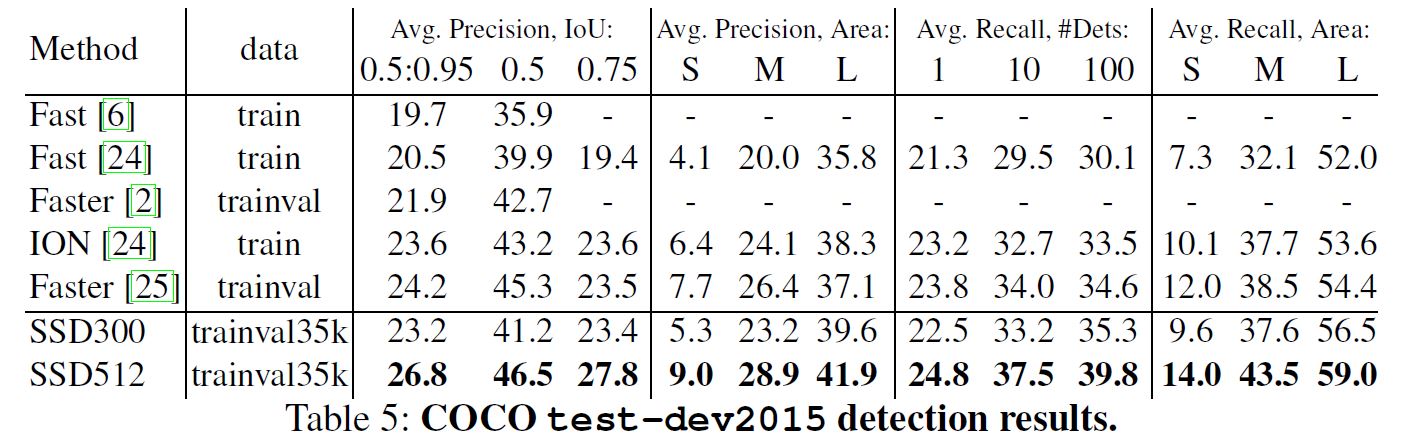
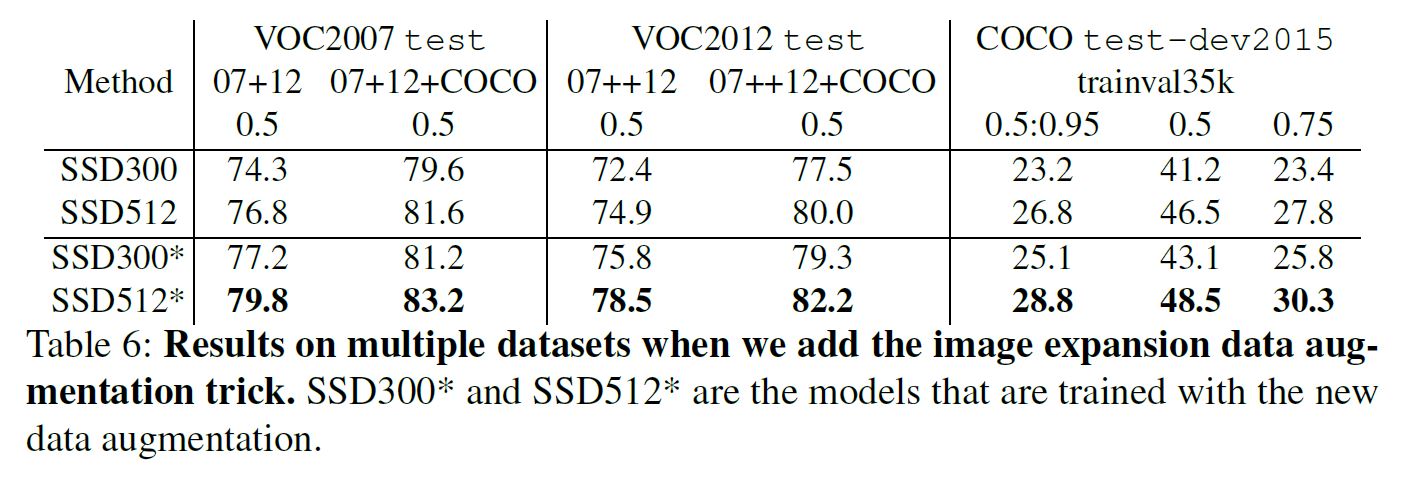
Data Augmentation for Small Object Accuracy
为了提升小物检测的性能, 作者首先将图片放大16倍, 对其用中值填充, 其后送入网络, 特别的因为扩大了尺度, 所以同时将迭代次数加倍.
Inference time
使用NMS压缩输出, 选择IOU大于0.45的前200个detection.
值得注意的是大概80%的时间花在base network.
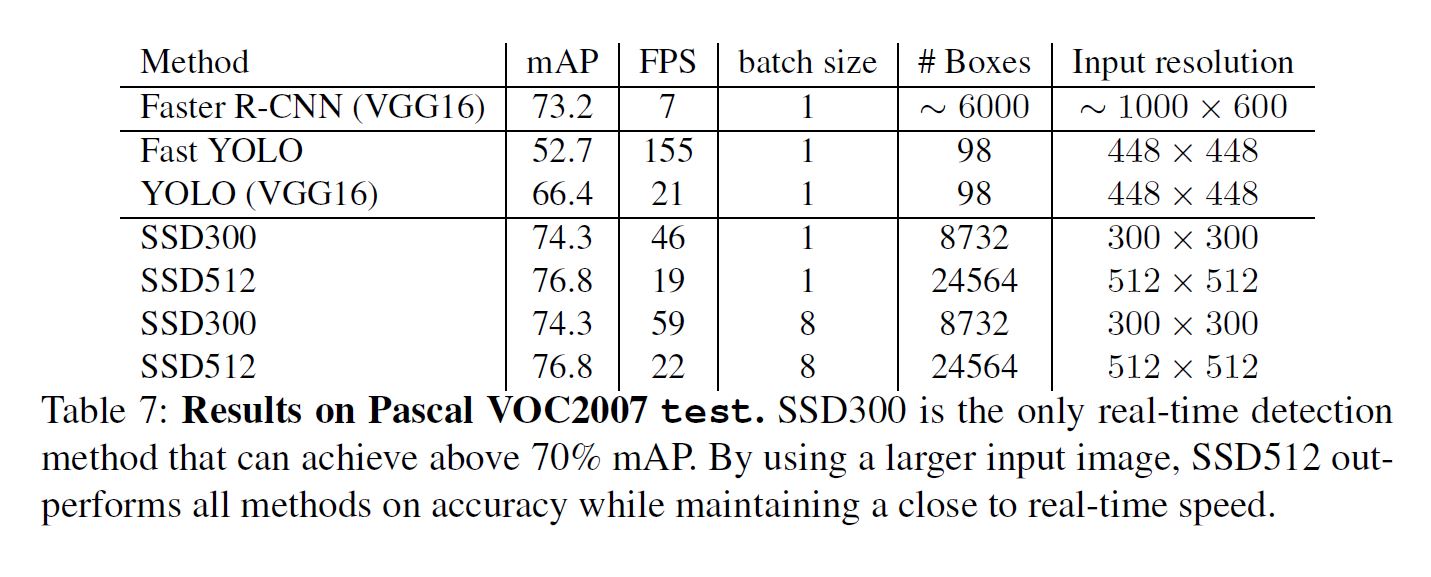
Conclusion
本文主要是提供了一种新的思路 - 使用多scale进行预测, 并且本文的方法是一个one stage方法, 因此速度也是非常快的, 尤其是他是唯一一个在real-time情况下mAP超过70的模型, 从创新型和性能都是无懈可击的.
以上是关于SSD的主要内容,如果未能解决你的问题,请参考以下文章