Hive的学习之路(理论篇)
Posted rmxd
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive的学习之路(理论篇)相关的知识,希望对你有一定的参考价值。
一、Hive介绍
Apache官网给出的logo,一半是Hadoop大象的头,一半是蜜蜂的身体,也是寓意着它是基于Hadoop,哈哈,纯属个人理解,进入正题。
Hive是基于Hadoop的一个数据仓库工具,可以将sql语句转换成MapReduce任务来运行。可以用来数据提取、转化、加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。
Hive定义了简单的类sql查询语言,成为HiveQL,它允许熟悉SQL的用户查询数据。
HiveSQL:Hive通过类sql的语法,来进行分布式的计算。HQL用起来和SQL非常的相似,Hive在执行的过程中会将HQL转换为MapReduce去执行,所以Hive其实就是基于Hadoop的一种分布式计算框架,底层依然是MapReduce程序,因此它本质上还是一种离线大数据分析工具。
二、Hive的适用场景
Hive是构建在静态(离线)批处理的Hadoop之上,Hadoop通常有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive并不能在大规模数据上实现低延迟快速的查询。
Hive查询操作过程严格遵守Hadoop MapReduce的作业执行模型,Hive将用户的HiveQL语句通过解释器转换为MapReduce作业提交到Hadoop集群 中,Hadoop监控作业执行过程,然后返回作业执行结果给用户。Hive并非为联机事务处理而设计,Hive并不提供实时的查询和基于行级的数据更新操作。Hive的最佳使用场景:大规模数据的离线批处理作业,例如网络日志分析等。
三、Hive的体系结构
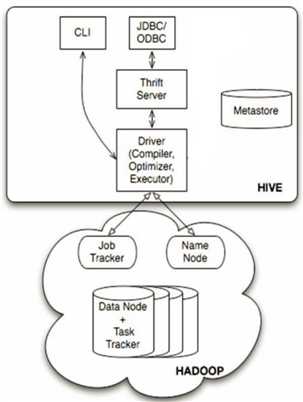
用户接口主要有3个:CLI,JDBC和WUI
①CLI,最常用的模式:实际上平时在>hive命令下操作,就是CLI用户接口
②JDBC,通过java代码操作,需要启动hiveserver,然后连接操作
MetaStroe元数据库
Hive将元数据存储在数据库中,如mysql,derby。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
解释器(Compiler)、优化器(optimizer)、执行器(executor)组件
这三个组件:HQL语句从词法分析、语法分析、编译、优化、以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行
Hadoop
Hive的数据存储在Hadoop中,大部分的查询、计算由MapReduce完成
四、Hive的原理分析

通过上图来分析Hive的原理(HQL的底层执行过程):
①客户端提交一条HQL语句(左侧UI部分)
②Driver将该HQL转发给Compiler(编译组件)对HQL进行词法分析、语法分析。在此,编译器要知道hql语句到底操作哪张表。
③底层查询元数据库(MetaStroe)寻找表信息(默认是derby数据库,后续会换成mysql)
④返回元信息
⑤Compiler编译器提交hql语句分析方案
⑥执行流程
i.executor执行器收到方案后,执行方案,在此需要注意:执行器在此执行方案时,会进行判断:如果不涉及MR组件,比如为表添加分区信息,简单的查询操作等,此时会直接与元数据库进行交互,然后去HDFS直接寻找具体数据;如果方案需要转换成MRJob,则会将job提交给Hadoop的JobTracker(后续为Yarn)
ii.MR Job执行完成,并且将结果写入HDFS中
iii.执行器与HDFS交互,获取结果文件信息
⑦如果客户端提交的hql语句是带有查询结果性,则会发生7~8~9,完成结果的查询。
以上是关于Hive的学习之路(理论篇)的主要内容,如果未能解决你的问题,请参考以下文章