爬取网页数据基础
Posted parent-absent-son
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取网页数据基础相关的知识,希望对你有一定的参考价值。
代码如下:
package com.tracker.offline.tools; import com.alibaba.fastjson.JSONObject; import com.google.common.collect.Lists; import com.tracker.common.utils.StringUtil; import com.tracker.coprocessor.utils.JsonUtil; import org.apache.commons.lang.StringUtils; import org.jsoup.Connection; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.File; import java.io.FileReader; import java.io.FileWriter; import java.io.IOException; import java.util.List; import java.util.Map; /** * 文件名:爬取页面上的数据 */ public class SpiderUserPosTag private static List<Integer> idList = Lists.newArrayList(113717565,113856580); private static final String url="http://192.168.202.17:8080/business/job51_jobstats/actions/jobshow_list"; private static final String output="E:\\\\result.tsv"; public String getDataFromWeb (String id) throws IOException Document response = Jsoup.connect(url).timeout(12 * 1000).userAgent("Mozilla/5.0").method(Connection.Method.POST) .ignoreContentType(true) .cookie("JSESSIONID", "986C7BA4E6FE3DB5C4591F3481D3FF1D") .header("Content-Type", "application/json;charset=UTF-8") .data("a","b") .requestBody("\\"startTime\\":\\"20190624\\",\\"endTime\\":\\"20190627\\",\\"seType\\":\\"2\\",\\"idType\\":\\"1\\",\\"timeType\\":\\"1\\",\\"startIndex\\":1,\\"offset\\":50,\\"id\\":"+id+"") .post(); return response.text(); public static void main(String[] args) throws Exception SpiderUserPosTag sp=new SpiderUserPosTag(); int n=0; int start=898440; BufferedWriter bw=new BufferedWriter(new FileWriter(new File(output),true)); try for (Integer id:idList)
//返回数据转化和解析,Map<String,List<Map<String,String>>> String line = sp.getDataFromWeb(String.valueOf(id)); Map<String,String> maps = JsonUtil.parseJSON2MapStr(line); String str2 = maps.get("result"); List<String> lists = JSONObject.parseArray(str2,String.class); for (String str3:lists) Map<String,String> maps2 = JsonUtil.parseJSON2MapStr(str3); bw.write(StringUtil.joinString("\\t",maps2.get("jobId"),maps2.get("jobName"),maps2.get("totalShowCount") ,maps2.get("totalClickCount"),maps2.get("totalApplyCount"),maps2.get("time"),maps2.get("webShowCount") ,maps2.get("webClickCount"),maps2.get("webApplyCount"),maps2.get("appShowCount"),maps2.get("appClickCount") ,maps2.get("appApplyCount"),maps2.get("mShowCount") ,maps2.get("mClickCount"),maps2.get("mApplyCount") ,maps2.get("showCount"),maps2.get("clickCount"),maps2.get("applyCount"))+"\\n"); bw.flush(); bw.close(); catch (IOException e) e.printStackTrace();
需要确定的三个元素:
url:
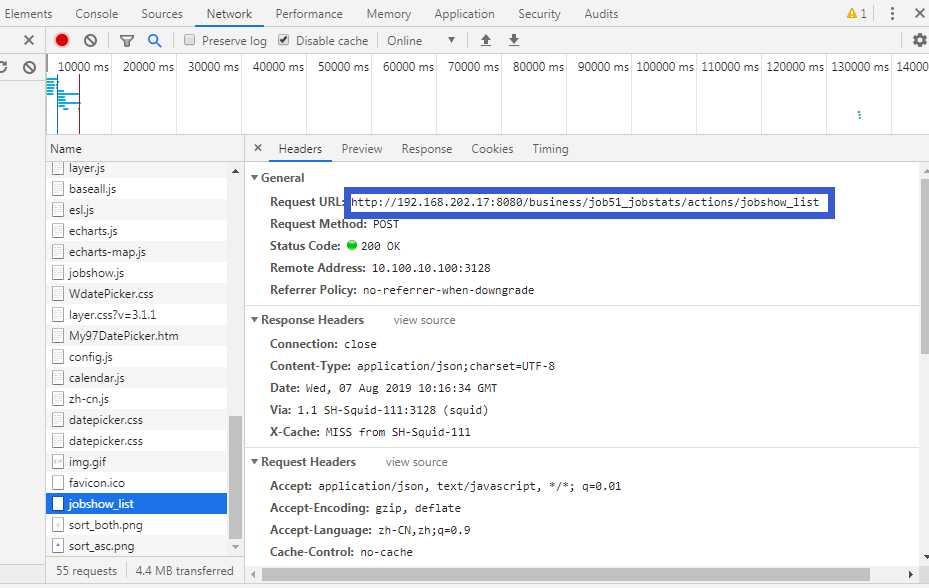
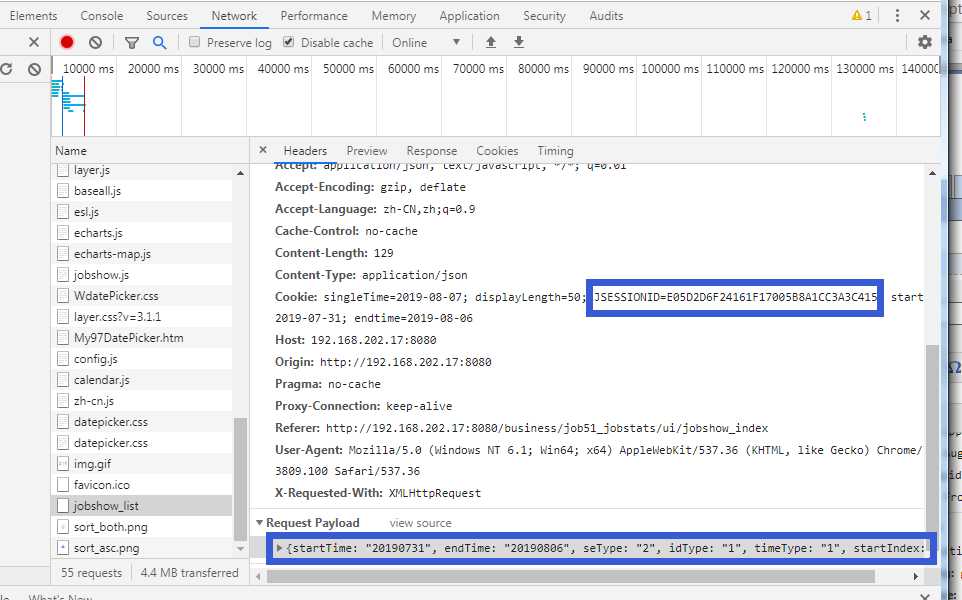
cookeid 和 请求body的格式:
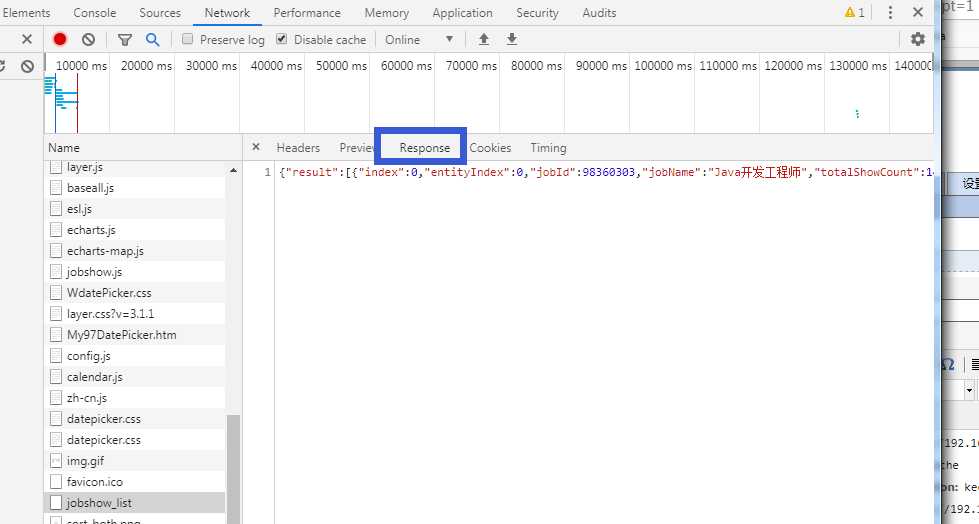
返回参数:
以上是关于爬取网页数据基础的主要内容,如果未能解决你的问题,请参考以下文章