Python机器学习·微教程
Posted zhuwjwh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python机器学习·微教程相关的知识,希望对你有一定的参考价值。
Python目前是机器学习领域增长最快速的编程语言之一。
该教程共分为11小节。在这个教程里,你将学会:
- 如何处理数据集,并构建精确的预测模型
- 使用Python完成真实的机器学习项目
这是一个非常简洁且实用的教程,希望你能收藏,以备后面复习!
接下来进入正题~

这个微课程适合谁学习?
开始之前,要搞清楚该教程是否属于你的菜。
如果你不符合以下几点,也没关系,只要花点额外时间搞清楚知识盲点就能跟上。
- 熟悉python语法,会写简单脚本。这意味着你在此之前接触过python,或者懂得其它编程语言,类C语言都是可以的。
- 了解机器学习的基本概念。基本概念包括知道什么是监督学习、非监督学习、分类和预测的区别、交叉验证、简单算法。不要被这些吓到了,并非要求你是个机器学习专家,只是你要知道如何查找并学习使用。
所以这个教程既不是python入门,也不是机器学习入门。而是引导你从一个机器学习初级开发者,到能够基于python生态开展机器学习项目的专业开发者。
教程目录
该教程分为12节
第1节:下载并安装python及Scipy生态
第2节:熟悉使用python、numpy、matplotlib和pandas
第3节:加载CSV数据
第4节:对数据进行描述性统计分析
第5节:对数据进行可视化分析
第6节:数据预处理
第7节:通过重采样进行算法评估
第8节:模型比较和选择
第9节:通过算法调整提高模型精度
第10节:通过集合预测提高模型精度
第11节:完善并保存模型
希望大家在学习的过程中能够自主寻找解决困难的办法,网上资源很丰富,这也是自我提升很关键的一步。当然也可以在评论区留言哦!
第1节:下载并安装python及Scipy生态
这一节内容比较简单,你需要下载python3.6并安装在你的系统里,我用的win10系统。
接着要安装Scipy生态和scikit-learn库,这里推荐使用pip安装。
简单介绍一下Scipy,Scipy是一个基于python的数学、科学和工程软件开源生态系统。包含一些核心库:numpy、scipy、pandas、matplotlib、ipython、sympy
如果你不想这么麻烦,那么也可以使用傻瓜式一条龙安装-Anaconda,这里面预装了python及一百多个库。
安装好后,就可以在命令行键入“python”,就可以运行python了。
看一下python及各个库的版本:
# Python version import sys print(‘Python: ‘.format(sys.version)) # scipy import scipy print(‘scipy: ‘.format(scipy.__version__)) # numpy import numpy print(‘numpy: ‘.format(numpy.__version__)) # matplotlib import matplotlib print(‘matplotlib: ‘.format(matplotlib.__version__)) # pandas import pandas print(‘pandas: ‘.format(pandas.__version__)) # scikit-learn import sklearn print(‘sklearn: ‘.format(sklearn.__version__))
如果没有报错,那么安装环节就成功了。
第2节:熟悉使用python、numpy、matplotlib和pandas
第一步,你要能够读写python脚本。
python是一门区分大小写、使用#注释、用tab缩进表示代码块的语言。
这一小节目的在于练习python语法,以及在python环境下如何使用重要的Scipy生态工具。
包括:
- 使用python列表
- 使用numpy array数组操作
- 使用matplotlib简单绘图
- 使用pandas两种数据结构Series和DataFrame
# 导入各个库 import numpy as np import pandas as pd import matplotlib.pyplot as plt myarray = np.array([[1, 2, 3], [4, 5, 6]]) # 使用numpy数组 rownames = [‘a‘, ‘b‘] colnames = [‘one‘, ‘two‘, ‘three‘] # 使用列表操作 mydataframe = pd.DataFrame(myarray, index=rownames, columns=colnames) #生成DataFrame print(mydataframe) mp = plt.plot(myarray) # 使用matplotlib绘制简单图表 plt.show() # 显示图像
第3节:加载CSV数据
机器学习算法需要有数据,这节讲解如何在python中正确地加载CSV数据集
有几种常用的方法供参考:
- 使用标准库中CSV的CSV.reader()加载
- 使用第三方库numpy中的numpy.loadtxt()加载
- 使用第三方库pandas中的pandas.read_csv()加载
这里使用pandas来加载数据集,数据集使用网上数据Pima Indians onset of diabetes,你也可以使用本地数据练习
# Load CSV using Pandas from URL import pandas # 导入pandas库 url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv" names = [‘preg‘, ‘plas‘, ‘pres‘, ‘skin‘, ‘test‘, ‘mass‘, ‘pedi‘, ‘age‘, ‘class‘] data = pandas.read_csv(url, names=names) # 读取数据 print(data.head(5)) # 打印数据集前5行
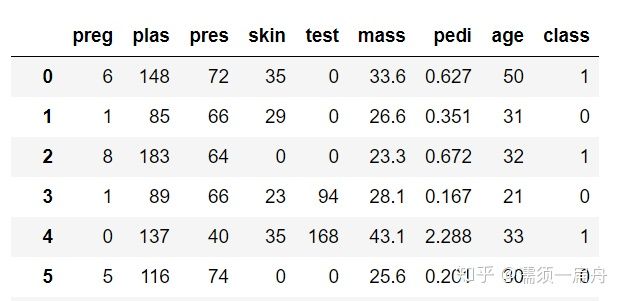
第4节:对数据进行描述性统计分析
导入数据后,第一步要做的是理解数据。
对数据理解的越透彻,建立的模型也会越精确。这里就要提到描述性统计分析,主要包括数据的频数分析、集中趋势分析、离散程度分析、分布以及一些基本的统计图形。
有以下几点操作:
- 使用head()和tail()函数查看数据样本
- 使用shape属性查看数据规格
- 使用dtypes属性查看每个变量的数据类型
- 使用describe()函数查看数据描述
- 使用corr()函数计算各个变量之间的相关性
依然使用pima数据集,接上一节读取数据后:
# Load CSV using Pandas from URL import pandas # 导入pandas库 url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv" names = [‘preg‘, ‘plas‘, ‘pres‘, ‘skin‘, ‘test‘, ‘mass‘, ‘pedi‘, ‘age‘, ‘class‘] data = pandas.read_csv(url, names=names) # 读取数据 head_5 = data.head(5) # 查看前5行 print(head_5) tail_5 = data.tail(5) # 查看后5行 print(tail_5) shape_ = data.shape # 查看数据规格,即多少行多少列 print(shape) dtypes_ = data.dtypes # 查看每个变量的数据类型 print(dtypes_) corr_ = data.corr() # 查看各个变量之间的相关性 print(corr_) description = data.describe() # 查看数据描述 print(description)
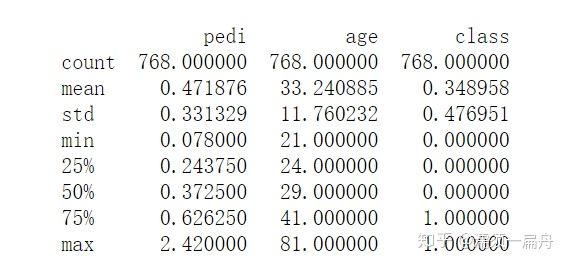 数据描述结果
数据描述结果
第5节:对数据进行可视化分析
仅仅是做描述性统计无法直观地理解数据,python提供了丰富的可视化工具,帮助展示数据。这一小节就是对上节数据集进行可视化描述,让你一目了然。
有以下几点操作:
- 使用hist()方法创建每个变量的直方图
- 使用plot(kind=‘box‘)方法创建每个变量的箱图
- 使用plotting.scatter_matrix()方法创建矩阵散点图
# Load CSV using Pandas from URL import pandas # 导入pandas库 url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv" names = [‘preg‘, ‘plas‘, ‘pres‘, ‘skin‘, ‘test‘, ‘mass‘, ‘pedi‘, ‘age‘, ‘class‘] data = pandas.read_csv(url, names=names) # 读取数据 import matplotlib.pyplot as plt # 导入绘图模块 data.hist() # 直方图 data.plot(kind=‘box‘) # 箱图 pd.plotting.scatter_matrix(data) # 矩阵散点图 plt.show() # 展示图表
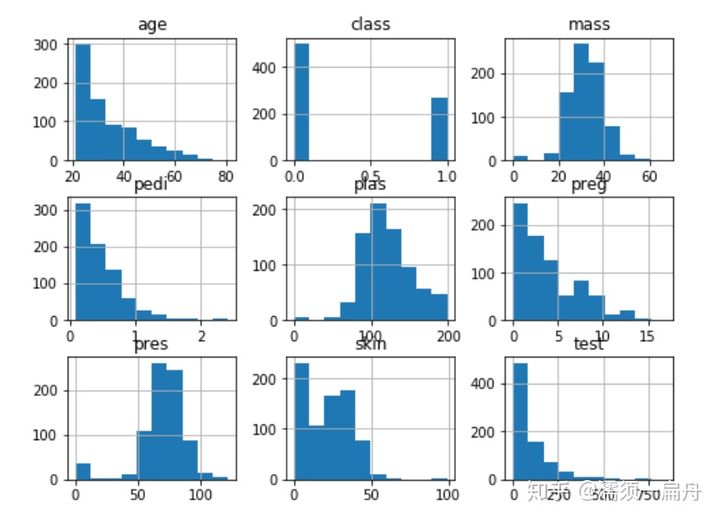 直方图
直方图
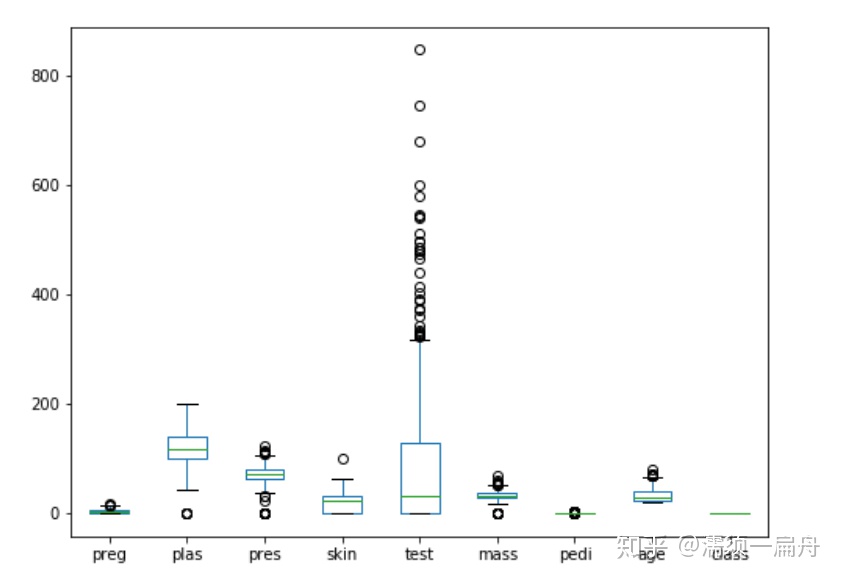
箱图
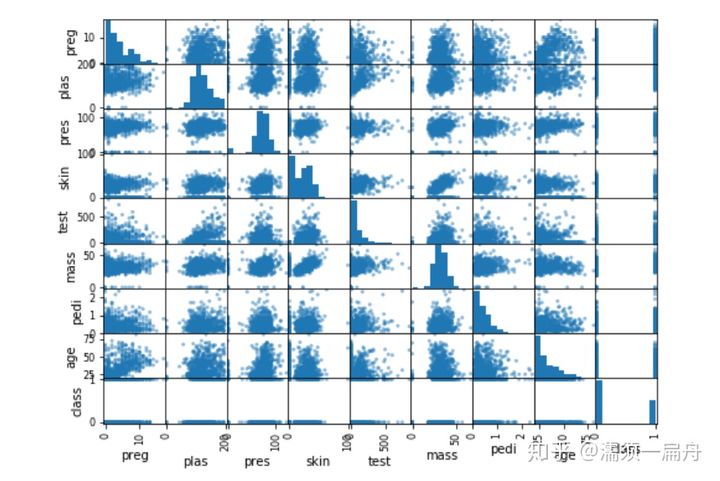 矩阵散点图
矩阵散点图
第6节:数据预处理
在将数据用作机器学习模型之前,需要对数据的内容和结构做适当的调整,才能更好的适应模型。这就是数据预处理工作。
有一些方法技术可以用于数据预处理,比如:
- 数据标准化。数据标准化是将数据按比例缩放,使之落入一个小的特定区间。有利于提升模型的收敛速度和模型精度。比较典型的标准化方法有min-max标准化、z-score 标准化、归一化等
- 数据二值化。特征二值化是对数值特征进行阈值处理以获得布尔值的过程,根据阈值将数据二值化(将特征值设置为0或1)大于阈值的值映射到1,而小于或等于阈值的值映射到0.默认阈值为0时,只有正值映射到1。方法有Binarizing等。
- 分类数据连续化。通常,特征不是作为连续值给出的,而是文本字符串或者数字编码的类别。比如性别数据通常是
["男", "女"]这样的数据, 可以编码成[1,2], 但是这种数据通常不是可以直接进入机器学习模型的。将这种分类数据进行连续化的方法最著名的就是one-hot-encoding - 估算缺失的值。由于各种原因,许多真实世界的数据集包含缺失值,通常编码为空白,NaN或其他占位符。然而,这样的数据集与scikit-learn估计器不兼容,它们假定数组中的所有值都是数值的,并且都具有并保持含义。使用不完整数据集的基本策略是放弃包含缺失值的整个行和/或列。然而,这是以丢失可能有价值的数据为代价的(尽管不完整)。更好的策略是推算缺失值,即从数据的已知部分推断它们。
上面提到的数据预处理技术都可以通过scikit-learn提供的方法实现。
简单介绍下scikit-learn,scikit-learn拥有可以用于监督和无监督学习的方法,一般来说监督学习使用的更多。sklearn中的大部分函数可以归为估计器(Estimator)和转化器(Transformer)两类。
估计器(Estimator)其实就是模型,它用于对数据的预测或回归。基本上估计器都会有以下几个方法:
- fit(x,y):传入数据以及标签即可训练模型,训练的时间和参数设置,数据集大小以及数据本身的特点有关
- score(x,y)用于对模型的正确率进行评分(范围0-1)。但由于对在不同的问题下,评判模型优劣的的标准不限于简单的正确率,可能还包括召回率或者是查准率等其他的指标,特别是对于类别失衡的样本,准确率并不能很好的评估模型的优劣,因此在对模型进行评估时,不要轻易的被score的得分蒙蔽。
- predict(x)用于对数据的预测,它接受输入,并输出预测标签,输出的格式为numpy数组。我们通常使用这个方法返回测试的结果,再将这个结果用于评估模型。
转化器(Transformer)用于对数据的处理,例如标准化、降维以及特征选择等等。同与估计器的使用方法类似:
- fit(x,y):该方法接受输入和标签,计算出数据变换的方式。
- transform(x):根据已经计算出的变换方式,返回对输入数据x变换后的结果(不改变x)
- fit_transform(x,y) :该方法在计算出数据变换方式之后对输入x就地转换。
列如,我要对数据集进行标准化处理,用到scikit-learn库中的StandardScaler()函数,那么先要用该函数的fit()方法,计算出数据转换的方式,再用transform()方法根据已经计算出的变换方式,返回对输入数据x标准化变换后的结果。
# 标准化数据 (0 mean, 1 stdev) from sklearn.preprocessing import StandardScaler # 导入标准化函数 import pandas import numpy # 读取数据 url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv" names = [‘preg‘, ‘plas‘, ‘pres‘, ‘skin‘, ‘test‘, ‘mass‘, ‘pedi‘, ‘age‘, ‘class‘] dataframe = pandas.read_csv(url, names=names) array = dataframe.values # 将数据分割为输入和响应两部分,即X和Y X = array[:,0:8] Y = array[:,8] # 对数据进行标准化处理 scaler = StandardScaler().fit(X) rescaledX = scaler.transform(X) # summarize transformed data numpy.set_printoptions(precision=3) print(rescaledX[0:5,:])
第7节:通过重采样方法进行算法评估
用于训练模型的数据集称为训练集,但如何评估训练出来的模型的准确度呢?显然不能再用训练集,否则既是裁判又是运动员。
所以,需要一个新的数据集用于验证模型的准确度,新数据的获取就需要用到重采样方法了。重采样可以将数据集切分为训练集和验证集两个数据,前者用于训练模型,后者用于评估模型。
验证数据取自训练数据,但不参与训练,这样可以相对客观的评估模型对于训练集之外数据的匹配程度。
模型在验证数据中的评估常用的是交叉验证,又称循环验证。它将原始数据分成K组(K-Fold),将每个子集数据分别做一次验证集,其余的K-1组子集数据作为训练集,这样会得到K个模型。这K个模型分别在验证集中评估结果,最后的误差MSE(Mean Squared Error)加和平均就得到交叉验证误差。
交叉验证有效利用了有限的数据,并且评估结果能够尽可能接近模型在测试集上的表现,可以做为模型优化的指标使用。
最后要通过某种评估规则计算出模型准确度的分数,这里提供了cross_val_score(scoring=‘‘)函数评估交叉验证结果,其中参数scoring代表评估规则。评估规则有很多种,针对回归和分类,有不同的选择,比如:
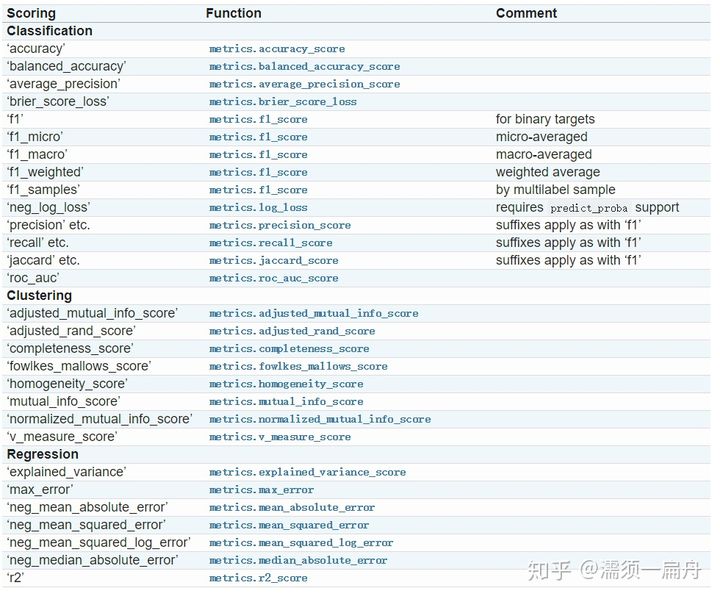
这一节要做的是:
- 将数据集切分为训练集和验证集
- 使用k折交叉验证估算算法的准确性
- 使用cross_val_score()函数评估交叉验证结果,输出k折交叉验证准确度评分
# 使用交叉验证评估模型
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
# 加载数据
url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv"
names = [‘preg‘, ‘plas‘, ‘pres‘, ‘skin‘, ‘test‘, ‘mass‘, ‘pedi‘, ‘age‘, ‘class‘]
dataframe = read_csv(url, names=names)
array = dataframe.values
X = array[:,0:8]
Y = array[:,8]
# 使用k折交叉验证,n-split就是K值,shuffle指是否对数据洗牌,random_state为随机种子
kfold = KFold(n_splits=10,shuffle = True, random_state=7)
# 使用逻辑回归模型,这是一个分类算法
model = LogisticRegression(solver=‘liblinear‘)
# 交叉验证,cv代表交叉验证生成器,这里是k折,scoring代表评估规则,输出模型对于10个验证数据集准确度的评估结果
results = cross_val_score(model, X, Y, cv=kfold,scoring=‘neg_mean_squared_error‘)
# 打印这10个结果的平均值和标准差
print("Accuracy: %.3f%% (%.3f%%)") % (results.mean()*100.0, results.std()*100.0)
未完待续
如果大家想要学习更多的python数据分析知识,请关注我的公众号:pydatas

以上是关于Python机器学习·微教程的主要内容,如果未能解决你的问题,请参考以下文章