spark shuffle写操作三部曲之UnsafeShuffleWriter
Posted johnny666888
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark shuffle写操作三部曲之UnsafeShuffleWriter相关的知识,希望对你有一定的参考价值。
前言
在前两篇文章 spark shuffle的写操作之准备工作 中引出了spark shuffle的三种实现,spark shuffle写操作三部曲之BypassMergeSortShuffleWriter 讲述了BypassMergeSortShuffleWriter 用于shuffle写操作的具体细节,实现相对比较朴素,值得学习。本篇文章,主要剖析了 UnsafeShuffleWriter用作写shuffle数据的具体细节,它在 BypassMergeSortShuffleWriter 的思路上更进一步,建议先看 spark shuffle写操作三部曲之BypassMergeSortShuffleWriter,再来看本篇文章。下面先来看UnsafeShuffleWriter的主要依赖实现类 -- ShuffleExternalSorter。
sort-based shuffle的外部sorter -- ShuffleExternalSorter
在看本小节之前,建议先参照 spark 源码分析之二十二-- Task的内存管理 对任务的内存管理做一下详细的了解,因为ShuffleExternalSorter使用了内存的排序。任务在做大数据量的内存操作时,内存是需要管理的。
在正式剖析之前,先剖析其依赖类。
依赖之记录block元信息-- SpillInfo
它记录了block的一些元数据信息。
其类结构如下:

其中,blockId就是shuffle的临时的blockId,file就是shuffle合并后的文件,partitionLengths表示每一个分区的大小。
依赖之分区排序器 -- ShuffleInMemorySorter
可以在任何内存使用的数组--LongArray
它支持堆内内存和堆外内存,它有四个属性:

数组里的一个元素的地址等于:
if (baseObj == null) ? baseOffset(is real os address) + (length - 1) * WIDTH : address(baseObj) + baseOffset(is relative address 0) + (length - 1) * WIDTH
所有元素设为0:

设置元素

其底层使用unsafe类来设置值
获取元素

其底层使用unsafe类来获取值
记录指针地址压缩器 -- PackedRecordPointer
全称:org.apache.spark.shuffle.sort.PackedRecordPointer
成员常量:

压缩记录指针和分区:
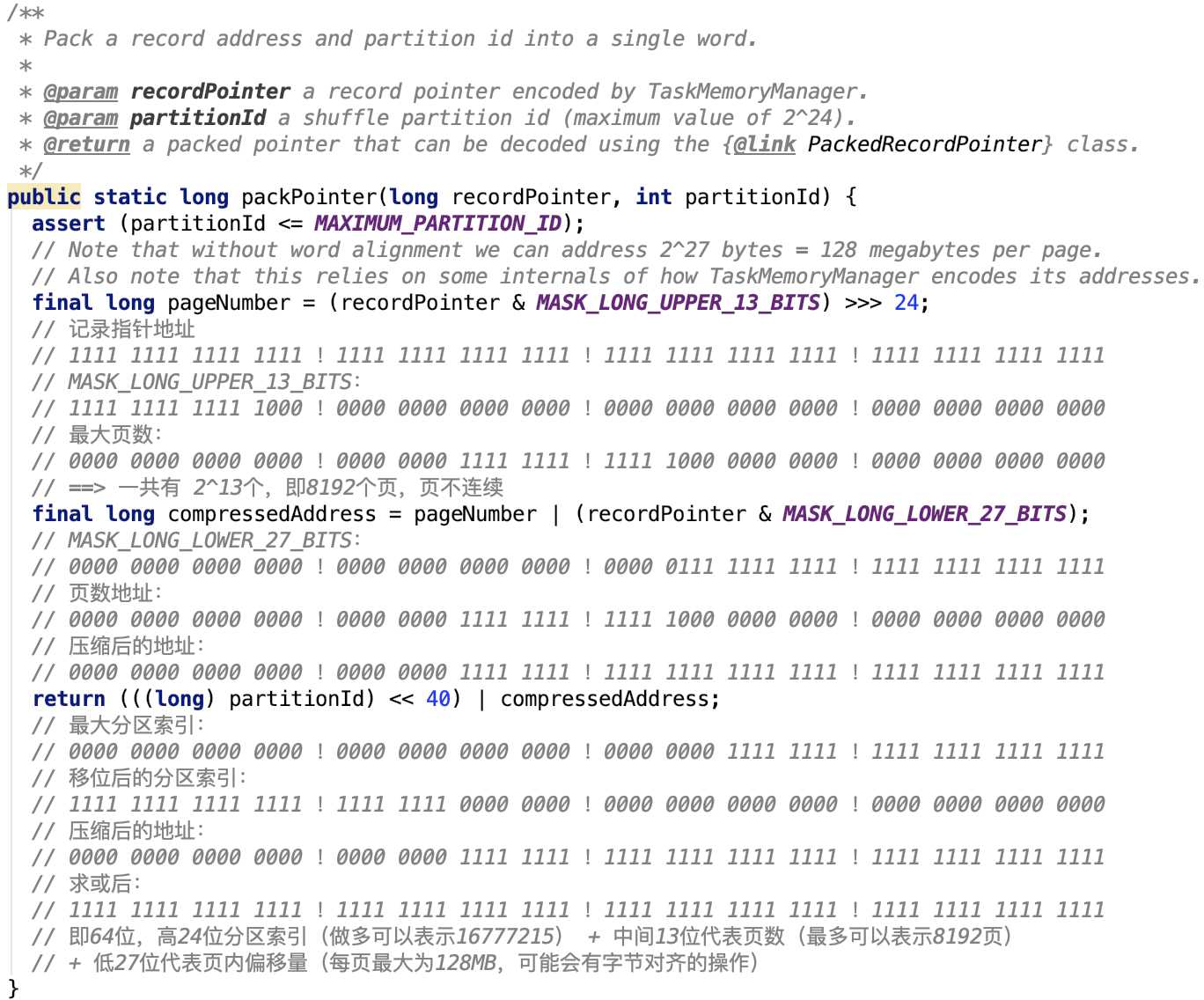
获取记录的地址:

获取记录的分区:
![]()
自定义比较器--SortComparator
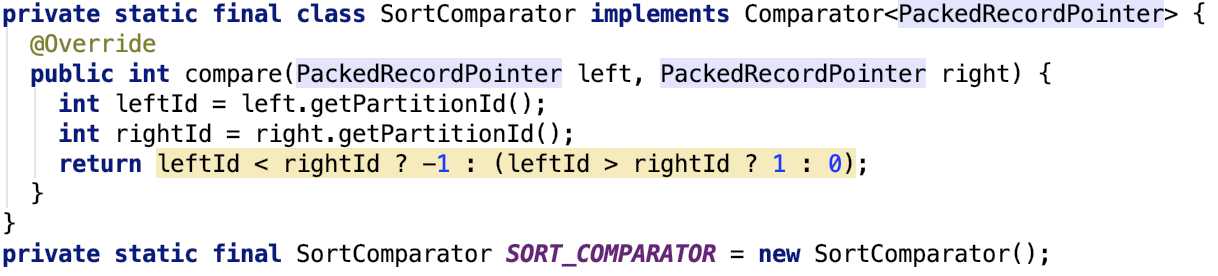
思路也很简单,就是根据分区来排序,即相同分区的数据被排到了一起。
遍历自定义数组的迭代器 -- ShuffleSorterIterator
其定义如下:

其思路很简单,hasNext跟JDK标准库的实现一致,多了一个loadNext,每次都需要把数组中下一个位置的元素放到packetRecordPointer中,然后从packedRecordPointer中取出数据的地址和分区信息。
获取迭代器
获取迭代器的源码如下:

其中 useRadixSort表示是否使用基数排序,默认是使用基数排序的,由参数 spark.shuffle.sort.useRadixSort 配置。
如果不使用基数排序,则会使用Spark的Sorter排序,sorter底层实现是TimSort,TimSort是优化之后的MergeSort。
总之,ShuffleSorterIterator中的数据已经是有序的了,只需要迭代式取出即可。
插入数据到自定义的数组中
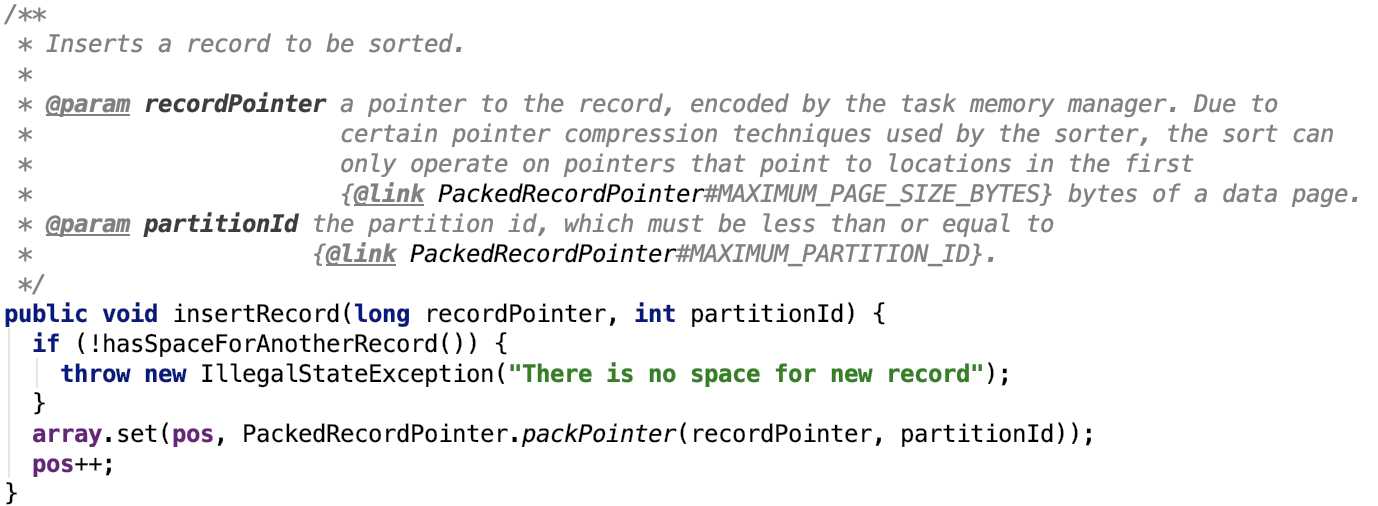
思路很简单,插入的数据就是记录的地址和分区数据,这两种数据被PackedRecordPointer压缩编码之后被存入到数组中。
继承关系
其继承关系如下:

即它是MemoryConsumer的子类,其实现了spill方法。
成员变量
其成员变量如下:
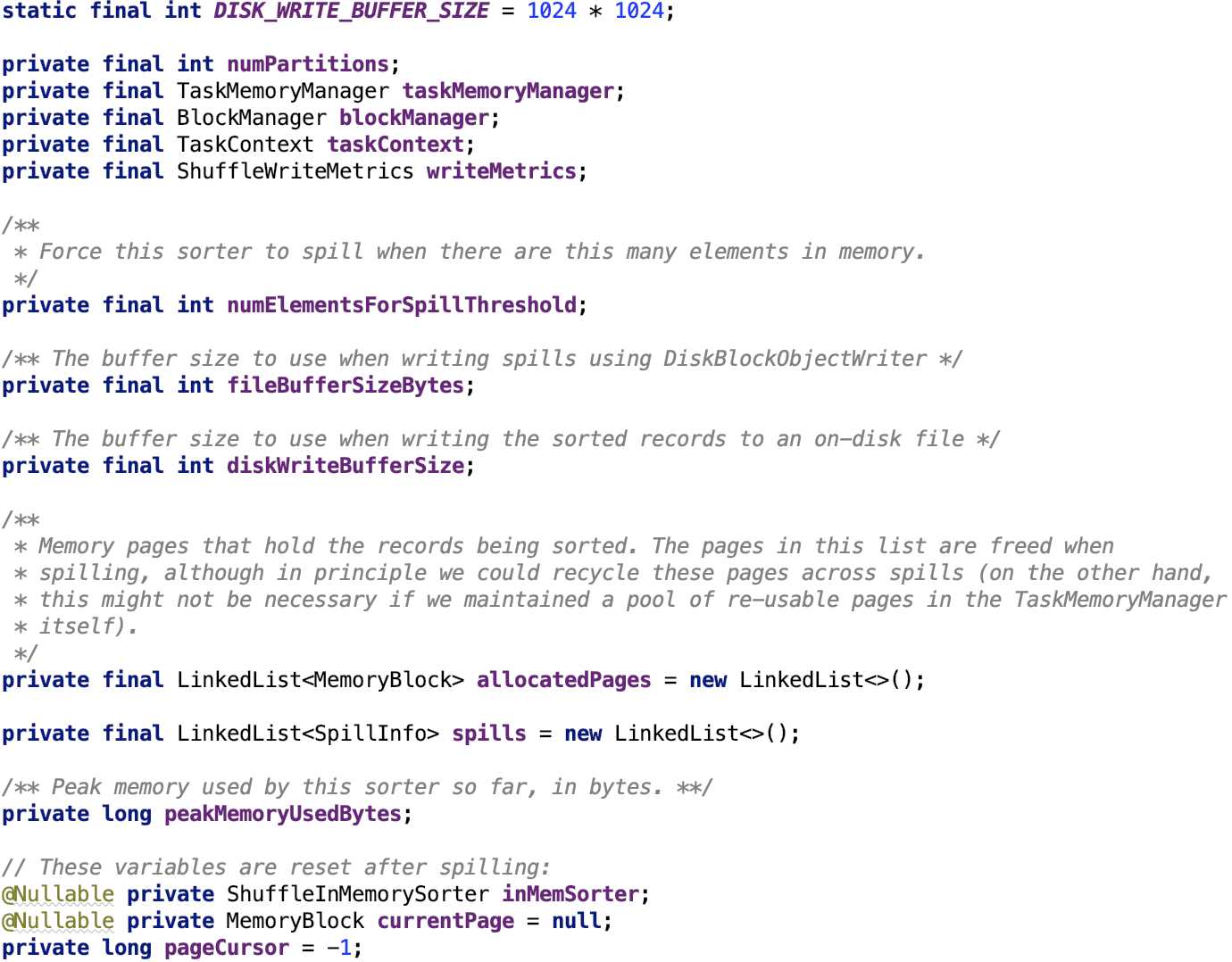
DISK_WRITE_BUFFER_SIZE:写到磁盘前的缓冲区大小为1M
numPartitions:reduce的分区数
taskMemoryManager:负责任务的内存管理。看 spark 源码分析之二十二-- Task的内存管理 做进一步了解。
blockManager:Spark存储系统的核心类。看 spark 源码分析之十八 -- Spark存储体系剖析 做进一步了解。
TaskContext:任务执行的上下文对象。
numElementsForSpillThreshold:ShuffleInMemorySorter 数据溢出前的元素阀值。
fileBufferSizeBytes:DiskBlockObjectWriter溢出前的buffer大小。
diskWriteBufferSize:溢出到磁盘前的buffer大小。
allocatedPages:记录分配的内存页。
spills:记录溢出信息
peakMemoryUsedBytes:内存使用峰值。
inMemSorter:内存排序器
currentPage:当前使用内存页
pageCursor:内存页游标,标志在内存页的位置。
构造方法
其构造方法如下:
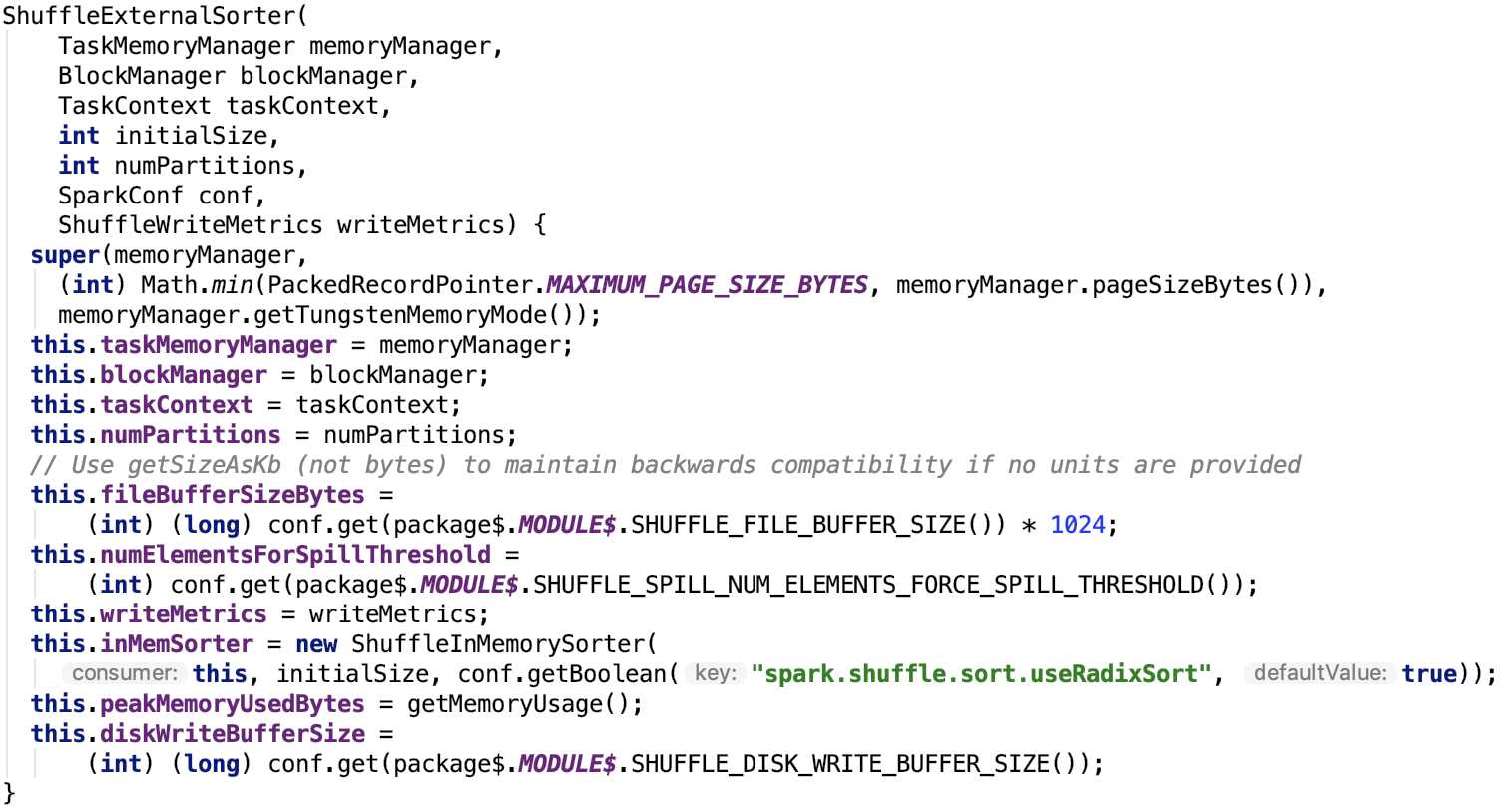
fileBufferSizeBytes:通过参数 spark.shuffle.file.buffer 来配置,默认为 32k
numElementsForSpillThreshold:通过参数spark.shuffle.spill.numElementsForceSpillThreshold来配置,默认是整数的最大值。
diskWriteBufferSize:通过 spark.shuffle.spill.diskWriteBufferSize 来配置,默认为 1M
核心方法
主要方法如下:

我们主要分析其主要方法。
溢出操作
其源码如下:
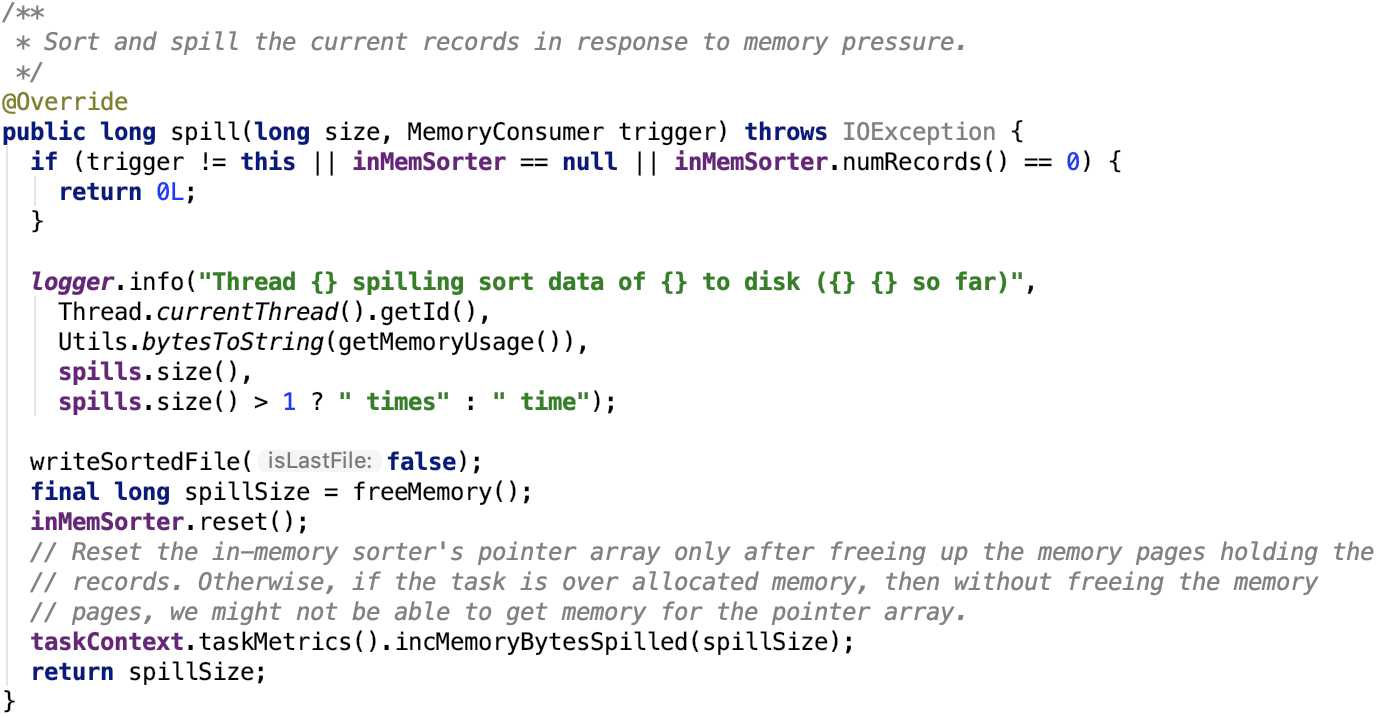
思路很简单,调用writeSortedFile将数据写入到文件中,释放内存,重置inMemSorter。
freeMemory方法如下:

writeSortedFile 源码如下:

图中,我大致把步骤划分为四部分。核心步骤是第3步。
整体思路:遍历sorter中的所有分区数据,最终同一分区的数据被写入到同一个FileSegment中,这些FileSegment最终又构成了一个合并的文件,其中FileSegment的大小被存放在SpillInfo中,最后放到了spills集合中。
插入记录
其源码如下:
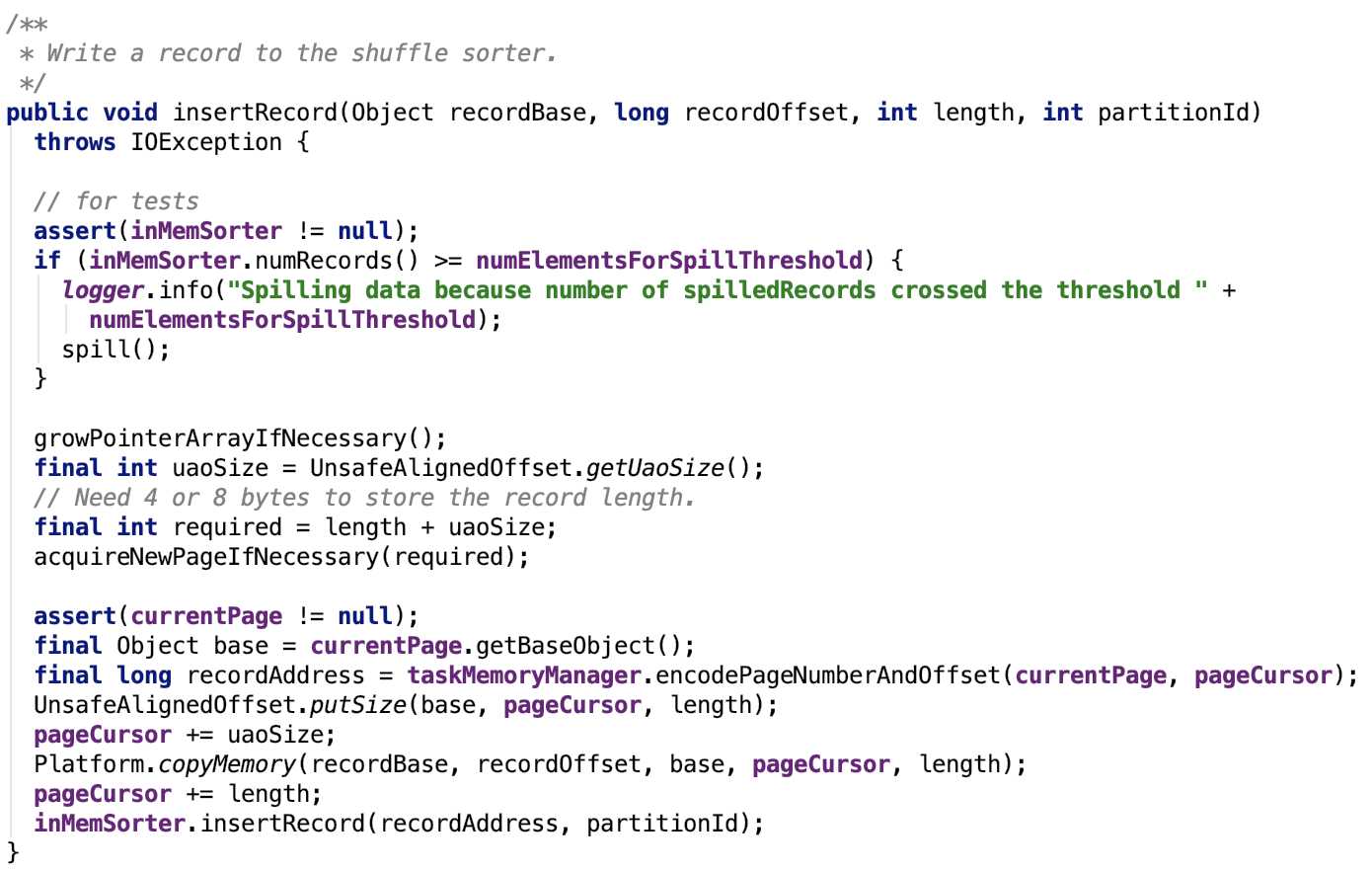
注意:它在插入数据之前,offset做了字节对齐,如果系统支持对齐,则向后错4位,否则向后错8位。这跟溢出操作里取数据是对应的,即可以跟上文中 writeSortedFile 方法对比看。
org.apache.spark.shuffle.sort.ShuffleExternalSorter#growPointerArrayIfNecessary源码如下:
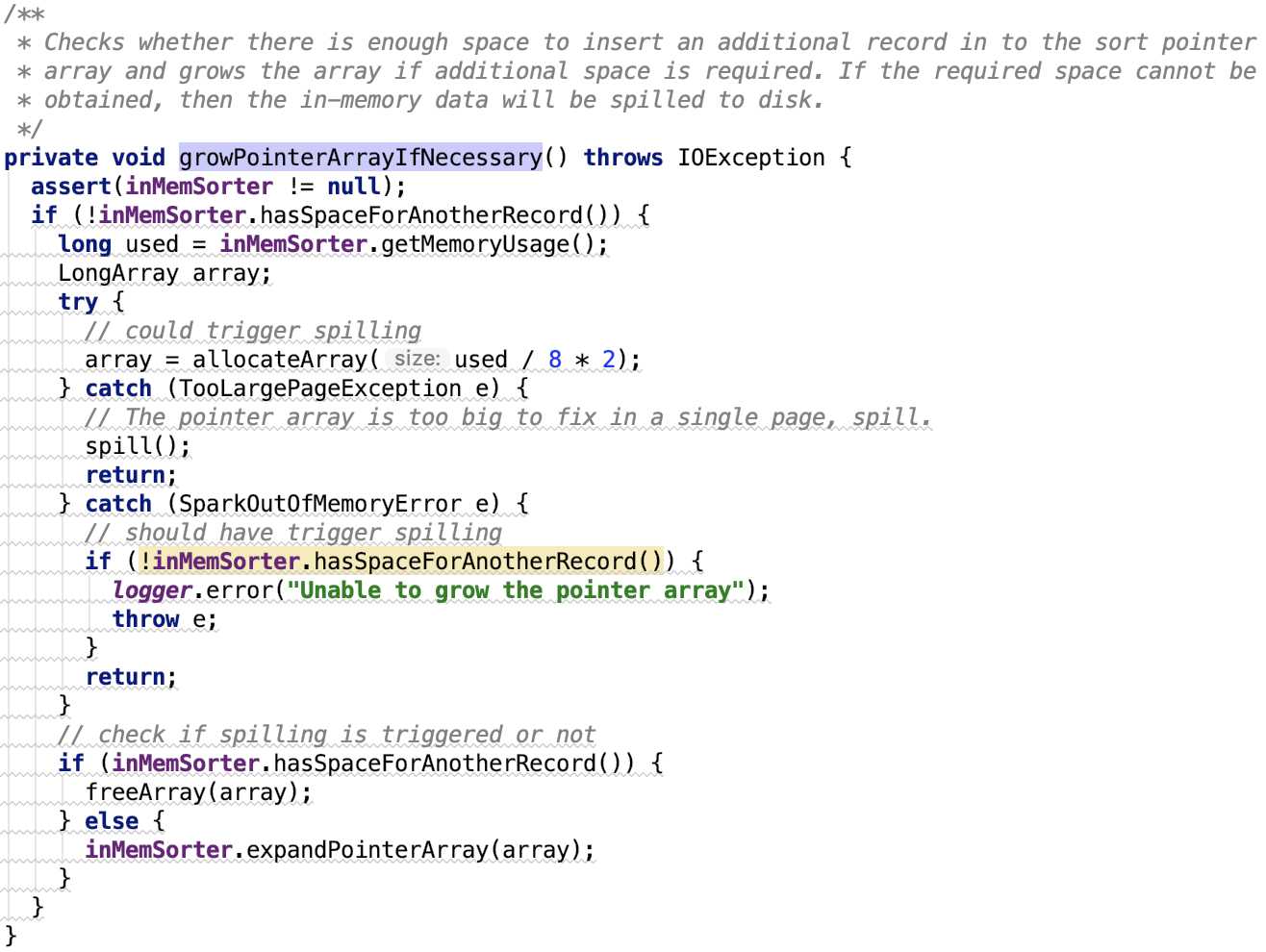
解释:首先hasSpaceForAnotherRecord会比较数组中下一个写的索引位置跟数组的最大容量比较,如果索引位置大于最大容量,那么就没有空间来存放下一个记录了,则需要把扩容,used是指的数组现在使用的大小,扩容倍数为源数组的一倍。
org.apache.spark.shuffle.sort.ShuffleExternalSorter#acquireNewPageIfNecessary 源码如下:
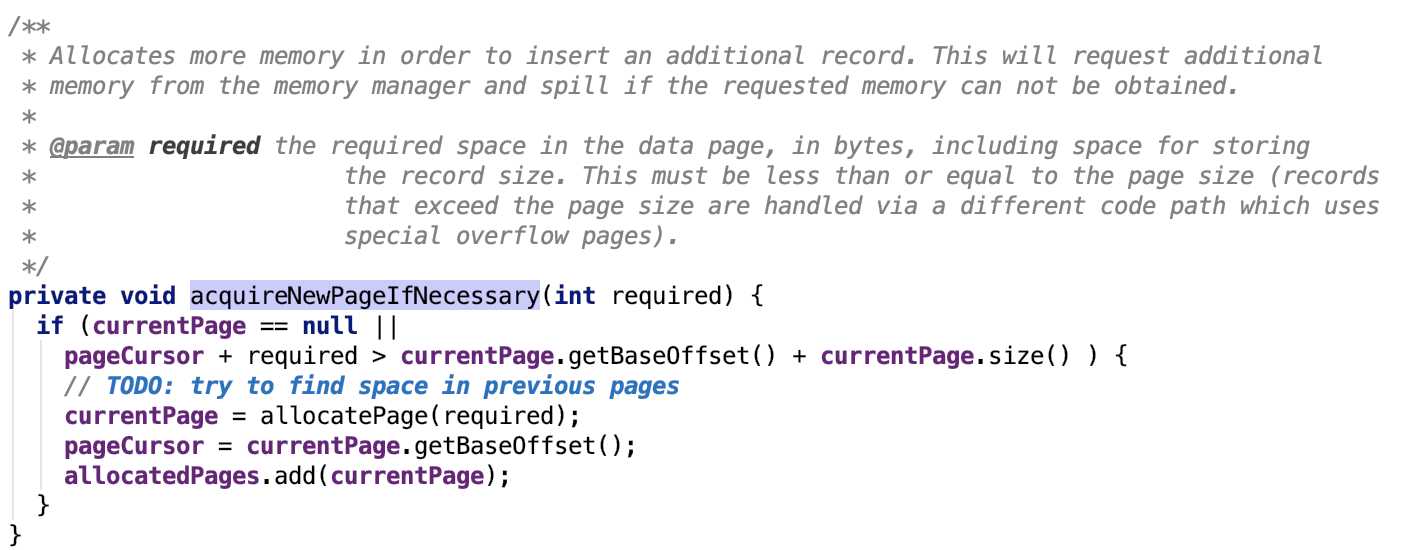
解释:分配内存页的条件是当前页的游标 + 需要的页大小 大于当前页的最大容量,则需要重新分配一个内存页。
关闭并且获取spill信息
其源码如下:
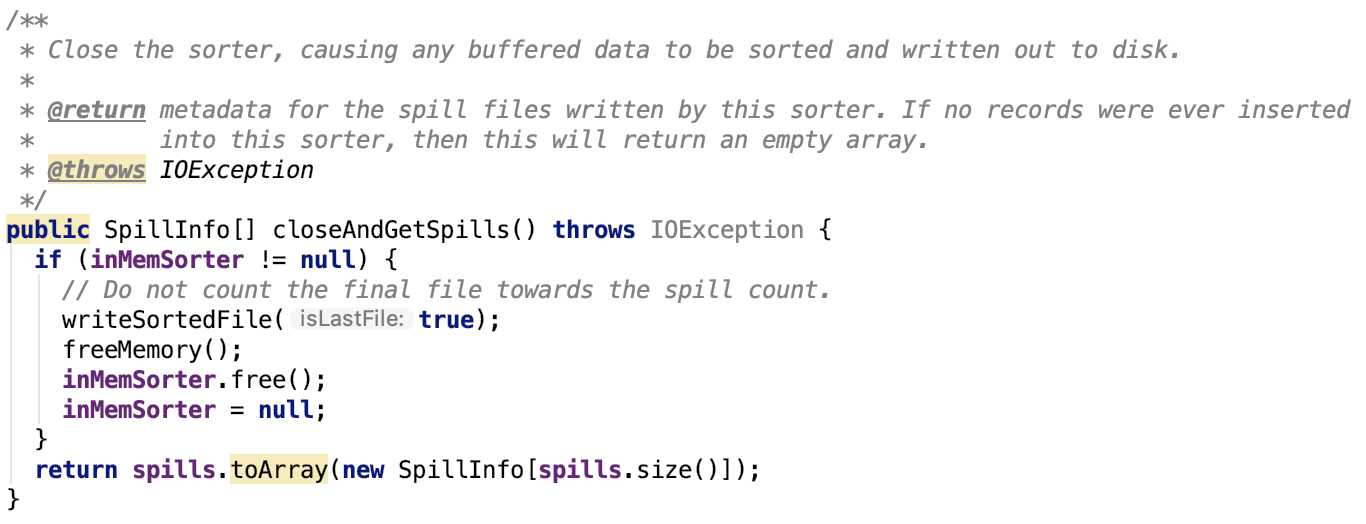
思路:执行最后一次溢出,然后将数据溢出信息返回。
清理资源
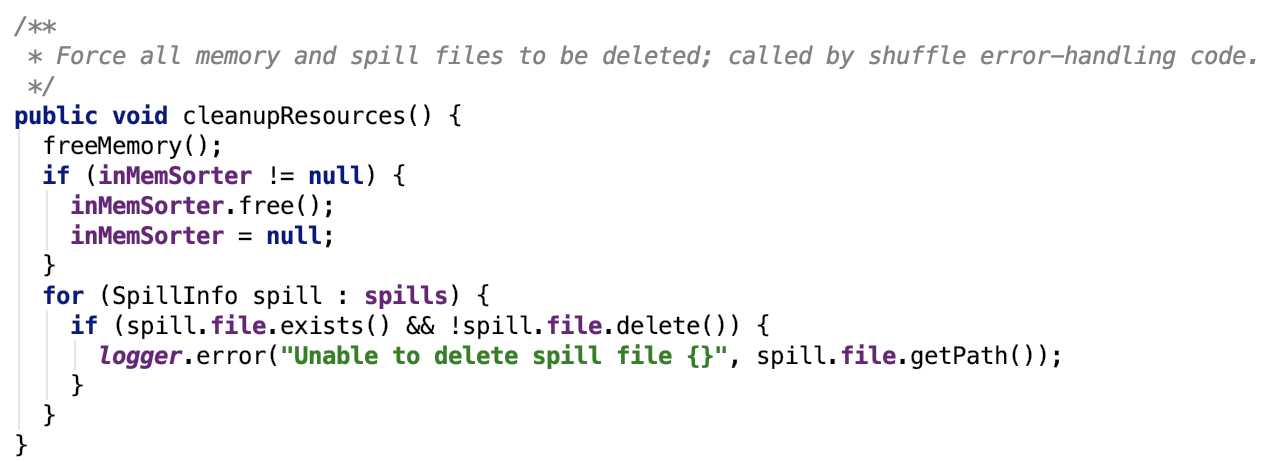
思路:释放内存排序器的内存,删除溢出的临时文件。
获取内存使用峰值
源码如下:
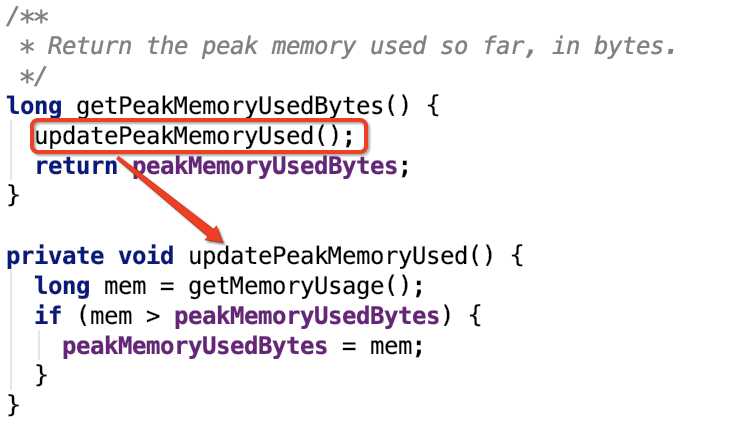
思路:当前使用内存大于最大峰值则更新最大峰值,否则直接返回。
总结
这个sorter内部集成的内存sorter会把同一分区的数据排序到一起,数据溢出时,相同分区的数据会聚集到溢出文件的一个segment中。
使用UnsafeShuffleWriter写数据
先上源码,后解释:
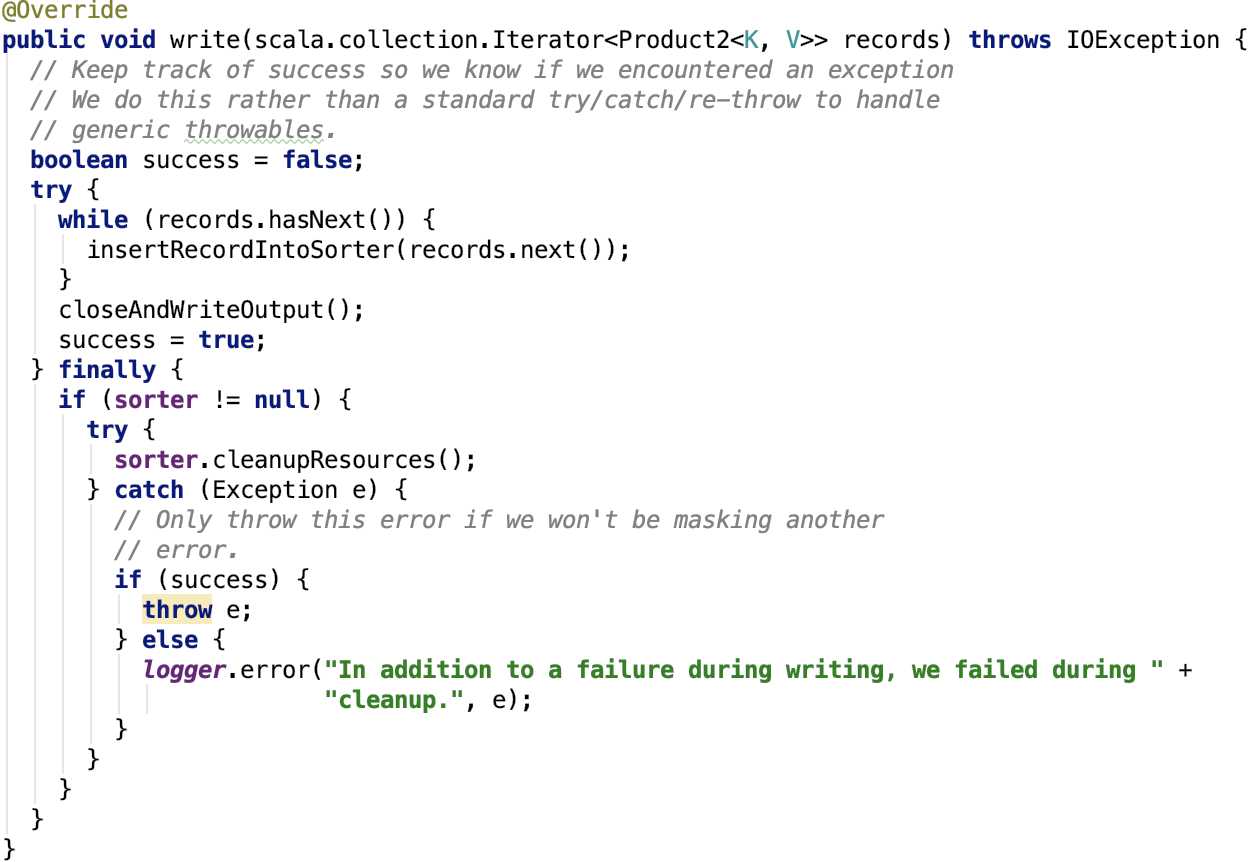
思路:流程很简单,将所有的数据逐一遍历放入sorter,然后将sorter关闭,获取输出文件,结束。
下面我们具体来看每一步是具体怎么实现的:
初始化Sorter
在org.apache.spark.shuffle.sort.UnsafeShuffleWriter的构造方法源码如下:
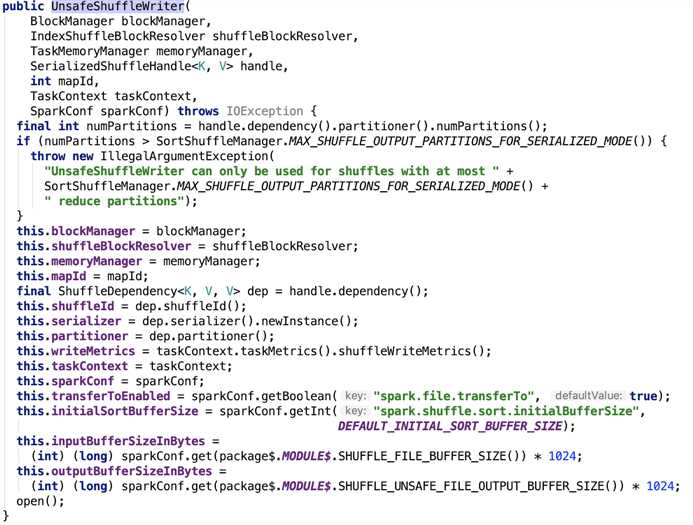
简单做一下说明:
DEFAULT_INITIAL_SORT_BUFFER_SIZE为 4096
DEFAULT_INITIAL_SER_BUFFER_SIZE 大小为 1M
reduce 分区数量最大为 16777216
SHUFFLE_FILE_BUFFER_SIZE默认为32k,大小由参数 spark.shuffle.file.buffer 配置。
SHUFFLE_UNSAFE_FILE_OUTPUT_BUFFER_SIZE 默认大小为32k,大小由参数 spark.shuffle.unsafe.file.output.buffer 配置。
其open方法如下:

这个方法里涉及了三个类:ShuffleExternalSorter,MyByteArrayOutputStream以及SerializationStream三个类。ShuffleExternalSorter在上文已经剖析过了,MyByteArrayOutputStream是一个ByteArrayOutputStream子类负责想堆内内存中写数据,SerializationStream是一个序列化之后的流,数据最终会被写入到serBuffer内存流中,调用其flush方法后,其内部的buf就是写入的数据,如下:

数据写入概述
核心方法write源码如下:
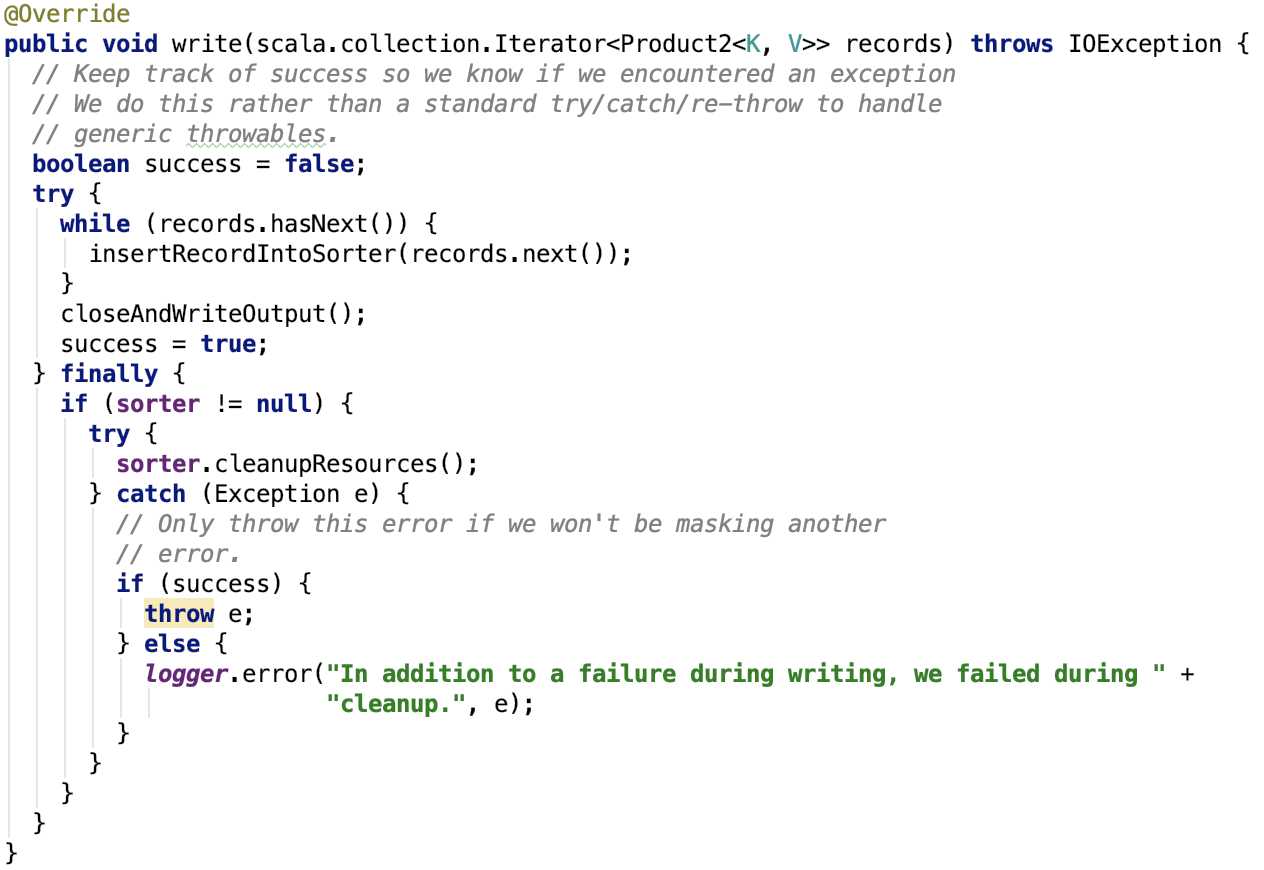
其主要有两步,一步是遍历每一条记录,将数据写入到sorter中;第二步是关闭sorter,并将数据写入到一个shuffle 文件中同时更新shuffle索引信息;最后清除shuffle过程中sorter使用的资源。
先来看第一步:数据写入到sorter中。
数据插入到Sorter

记录中的键值被序列化到serBuffer的buf字节数组中,然后被写入到 sorter(ShuffleExternalSorter)中。在sorter中序列化数据被写入到内存中(内存不足会溢出到磁盘中),其地址信息被写入到 ShuffleInMemorySorter 中,具体可以看上文介绍。
溢出文件归并为一个文件
一步是遍历每一条记录,将数据写入到sorter中后会调用sorter的closeAndGetSpills方法执行最后一次spill操作,然后获取到整个shuffle过程中所有的SpillInfo信息。然后使用ShuffleBlockResolver获取到shuffle的blockId对应的shuffle文件,最终调用mergeSpills 方法合并所有的溢出文件到最终的shuffle文件,然后更新shuffle索引文件,设置Shuffle结果的MapStatus信息,结束。
org.apache.spark.shuffle.sort.UnsafeShuffleWriter#closeAndWriteOutput 源码如下:
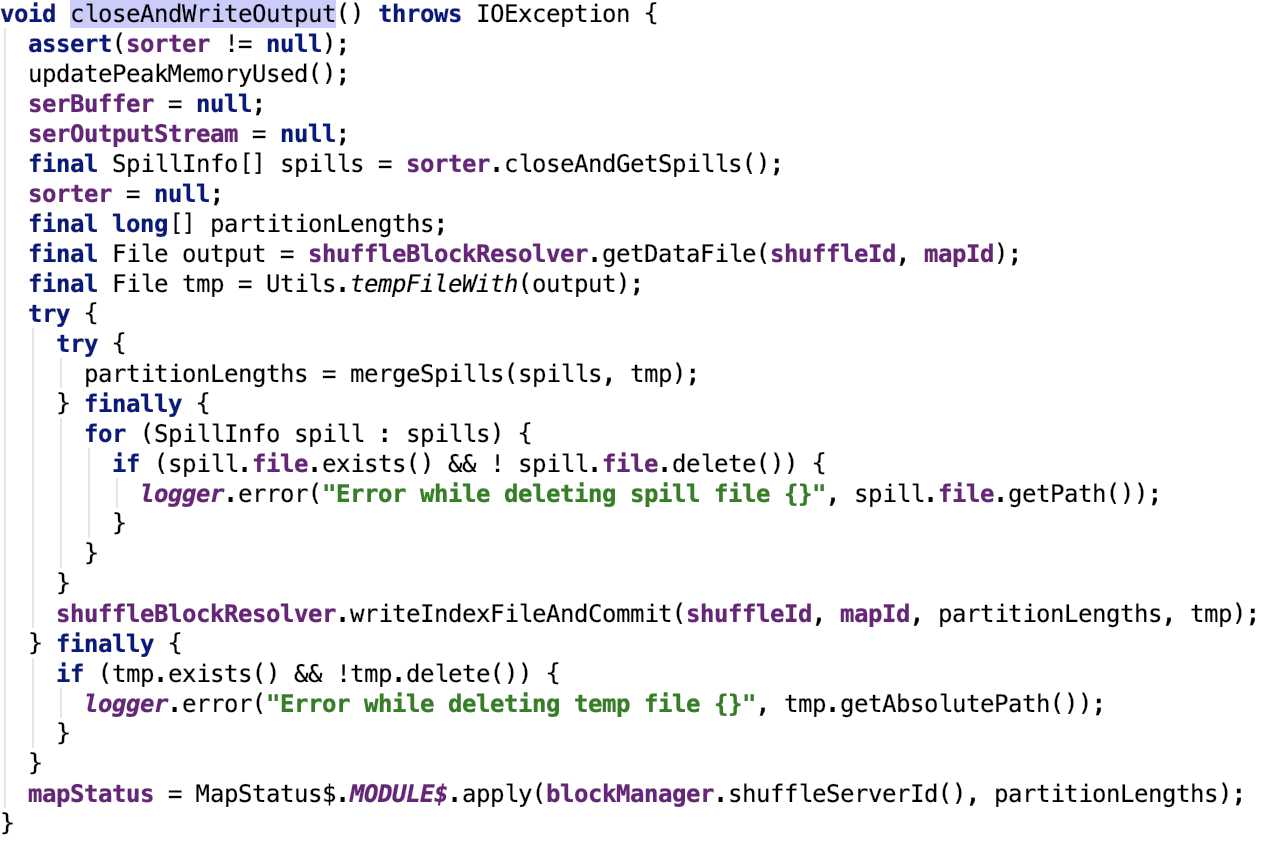
其关键方法 org.apache.spark.shuffle.sort.UnsafeShuffleWriter#mergeSpills 源码如下:

如果溢出文件为0,直接返回全是0的分区数组。
如果溢出文件为1,文件重命名后返回只有一个元素的分区数组。
如果溢出文件多于1个则,多个溢出文件开始merge。
首先先看一下五个变量:
encryptionEnabled:是否启用加密,默认为false,通过 spark.io.encryption.enabled 参数来设置。
transferToEnabled:是否可以使用nio的transferTo传输,默认为true,通过 spark.file.transferTo 参数来设置。
compressionEnabled:是否使用压缩,默认为true,通过 spark.shuffle.compress 参数来设置。
compressionCodec:默认压缩类,默认为LZ4CompressionCodec,通过 spark.io.compression.codec 参数来设置。
fastMergeEnabled:是否启用fast merge,默认为true,通过 spark.shuffle.unsafe.fastMergeEnabled 参数来设置。
fastMergeIsSupported:是否支持 fast merge,如果不使用压缩或者是压缩算法是 org.apache.spark.io.SnappyCompressionCodec、org.apache.spark.io.LZFCompressionCodec、org.apache.spark.io.LZ4CompressionCodec、org.apache.spark.io.ZStdCompressionCodec这四种支持连接的压缩算法中的一种都是可以使用 fast merge的。
三种merge多个文件的方式:transfered-based fast merge、fileStream-based fast merge以及slow merge三种方式。
使用transfered-based fast merge条件:使用 fast merge并且压缩算法支持fast merge,并且启用了nio的transferTo传输且不启用文件加密。
使用fileStream-based fast merge条件:使用 fast merge并且压缩算法支持fast merge,并且未启用nio的transferTo传输或启用了文件加密。
使用slow merge条件:未使用 fast merge或压缩算法不支持fast merge。
下面我们来看三种合并溢出的方式。
transfered-based fast merge
其核心方法org.apache.spark.shuffle.sort.UnsafeShuffleWriter#mergeSpillsWithTransferTo 源码如下:

其依赖方法 org.apache.spark.util.Utils#copyFileStreamNIO 如下:
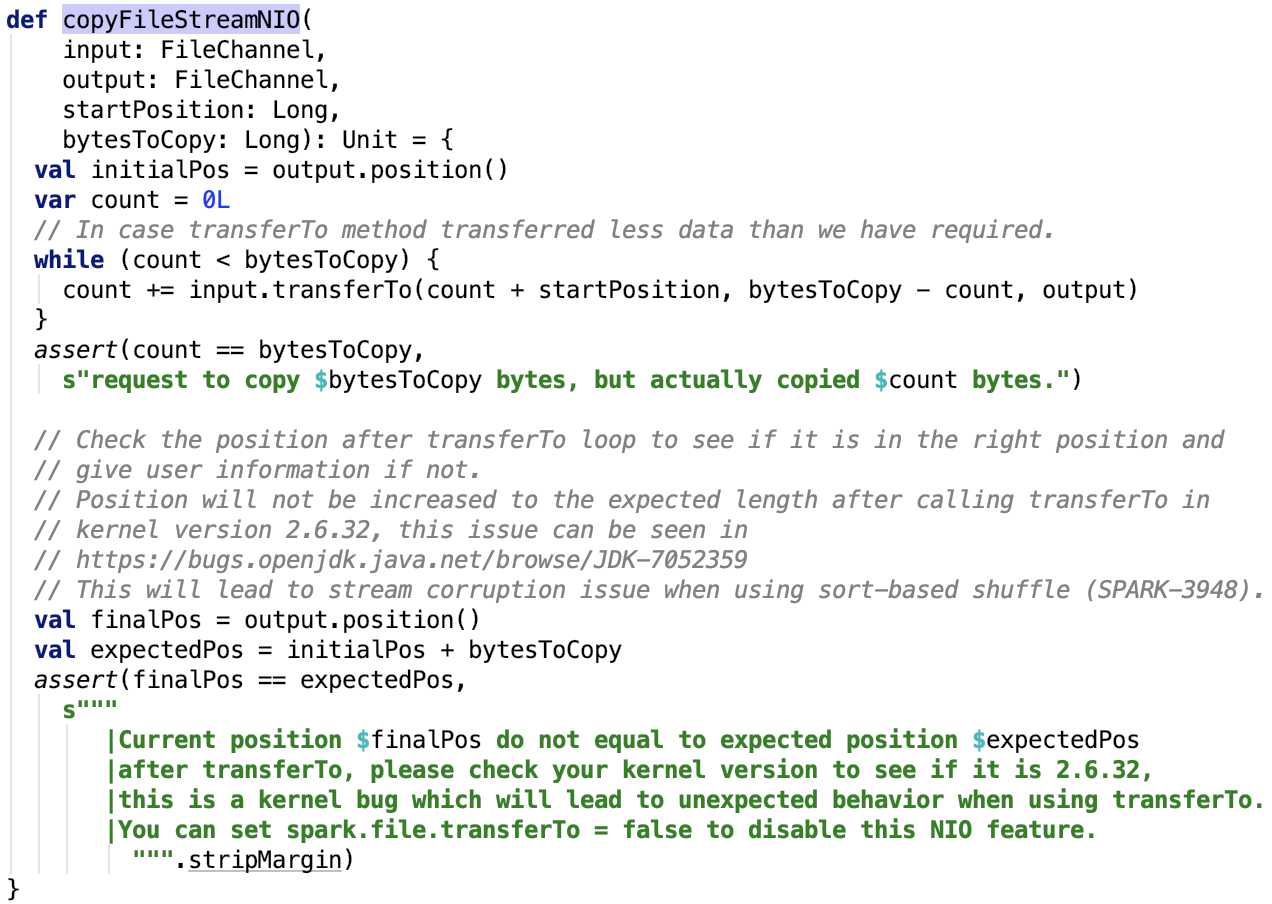
很简单,底层依赖于Java的NIO的transferTo方法实现。
fileStream-based fast merge
其核心方法 org.apache.spark.shuffle.sort.UnsafeShuffleWriter#mergeSpillsWithFileStream 源码如下,这里不传入任何压缩类,见 org.apache.spark.shuffle.sort.UnsafeShuffleWriter#mergeSpills 源码。
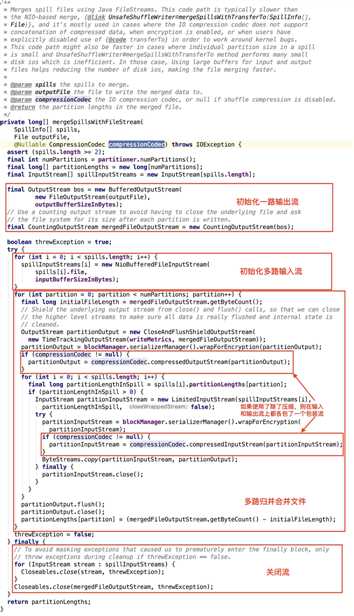
slow merge
其其核心方法 org.apache.spark.shuffle.sort.UnsafeShuffleWriter#mergeSpillsWithFileStream 源码跟 fileStream-based fast merge 里的一样,不做过多解释,只不过这里多传入了一个压缩类,见 org.apache.spark.shuffle.sort.UnsafeShuffleWriter#mergeSpills 源码。
更新shuffle索引
这部分更详细的可以看 org.apache.spark.shuffle.IndexShuffleBlockResolver#writeIndexFileAndCommit 源码。在上篇文章 spark shuffle写操作三部曲之BypassMergeSortShuffleWriter 中使用BypassMergeSortShuffleWriter写数据已经剖析过,不再剖析。
总结
ShuffleExternalSorter将数据不断溢出到溢出小文件中,溢出文件内的数据是按分区规则排序的,分区内的数据是乱序的。
多个分区的数据同时溢出到一个溢出文件,最后使用三种归并方式将多个溢出文件归并到一个文件,分区内的数据是乱序的。最终数据的格式跟第一种shuffle写操作的结果是一样的,即有分区的shuffle数据文件和记录分区大小的shuffle索引文件。
以上是关于spark shuffle写操作三部曲之UnsafeShuffleWriter的主要内容,如果未能解决你的问题,请参考以下文章