文本分类:survey
Posted the-wolf-sky
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本分类:survey相关的知识,希望对你有一定的参考价值。
作者:尘心
链接:https://zhuanlan.zhihu.com/p/76003775
- 简述
文本分类在文本处理中是很重要的一个模块,它的应用也非常广泛,比如:垃圾过滤,新闻分类,词性标注等等。它和其他的分类没有本质的区别,核心方法为首先提取分类数据的特征,然后选择最优的匹配,从而分类。但是文本也有自己的特点,根据文本的特点,文本分类的一般流程为:1.预处理;2.文本表示及特征选择;3.构造分类器;4.分类。
通常来讲,文本分类任务是指在给定的分类体系中,将文本指定分到某个或某几个类别中。被分类的对象有短文本,例如句子、标题、商品评论等等,长文本,如文章等。分类体系一般人工划分,例如:1)政治、体育、军事 2)正能量、负能量 3)好评、中性、差评。因此,对应的分类模式可以分为:二分类与多分类问题。
- 应用
文本分类的应用十分广泛,可以将其应用在:
- 垃圾邮件的判定:是否为垃圾邮件
- 根据标题为图文视频打标签 :政治、体育、娱乐等
- 根据用户阅读内容建立画像标签:教育、医疗等
- 电商商品评论分析等等类似的应用:消极、积极
- 自动问答系统中的问句分类
- 方法概述
文本分类问题算是自然语言处理领域中一个非常经典的问题了,相关研究最早可以追溯专家规则(Pattern)进行分类,但显然费时费力,覆盖的范围和准确率都非常有限。
后来伴随着统计学习方法的发展,特别是90年代后互联网在线文本数量增长和机器学习学科的兴起,逐渐形成了人工特征工程+浅层分类建模流程。
传统做法主要问题的文本表示是高纬度高稀疏的,特征表达能力很弱,此外需要人工进行特征工程,成本很高。而深度学习最初在图像和语音取得巨大成功,也相应的推动了深度学习在NLP上的发展,使得深度学习的模型在文本分类上也取得了不错的效果。
- 传统文本分类方法
传统的机器学习分类方法将整个文本分类问题就拆分成了特征工程和分类器两部分。特征工程分为文本预处理、特征提取、文本表示三个部分,最终目的是把文本转换成计算机可理解的格式,并封装足够用于分类的信息,即很强的特征表达能力。
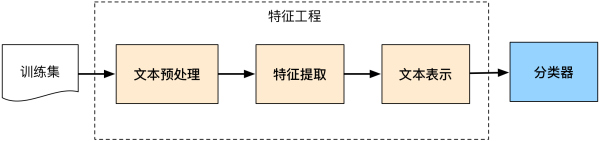
3.1.1 文本预处理:
文本预处理过程是在文本中提取关键词表示文本的过程,中文文本处理中主要包括文本分词和去停用词两个阶段。之所以进行分词,是因为很多研究表明特征粒度为词粒度远好于字粒度,其实很好理解,因为大部分分类算法不考虑词序信息。
中文分词技术:
1)基于字符串匹配的分词方法:
过程:这是一种基于词典的中文分词,核心是首先建立统一的词典表,当需要对一个句子进行分词时,首先将句子拆分成多个部分,将每一个部分与字典一一对应,如果该词语在词典中,分词成功,否则继续拆分匹配直到成功。
核心: 字典,切分规则和匹配顺序是核心。
分析:优点是速度快,时间复杂度可以保持在O(n),实现简单,效果尚可;但对歧义和未登录词处理效果不佳。
2)基于理解的分词方法:
基于理解的分词方法是通过让计算机模拟人对句子的理解,达到识别词的效果。其基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。它通常包括三个部分:分词子系统、句法语义子系统、总控部分。在总控部分的协调下,分词子系统可以获得有关词、句子等的句法和语义信息来对分词歧义进行判断,即它模拟了人对句子的理解过程。这种分词方法需要使用大量的语言知识和信息。由于汉语语言知识的笼统、复杂性,难以将各种语言信息组织成机器可直接读取的形式,因此目前基于理解的分词系统还处在试验阶段。
3)基于统计的分词方法:
过程:统计学认为分词是一个概率最大化问题,即拆分句子,基于语料库,统计相邻的字组成的词语出现的概率,相邻的词出现的次数多,就出现的概率大,按照概率值进行分词,所以一个完整的语料库很重要。
主要的统计模型有: N元文法模型(N-gram),隐马尔可夫模型(Hidden Markov Model ,HMM),最大熵模型(ME),条件随机场模型(Conditional Random Fields,CRF)等。
英文分词技术:
英文分词相比中文分词要简单得多,可以根据空格和标点符号来分词,然后对每一个单词进行词干还原和词形还原,去掉停用词和非英文内容
3.1.2 文本表示:
将文本转换成计算机可理解的方式。一篇文档表示成向量,整个语料库表示成矩阵

词袋法:
忽略其词序和语法,句法,将文本仅仅看做是一个词集合。若词集合共有NN个词,每个文本表示为一个NN维向量,元素为0/1,表示该文本是否包含对应的词。( 0, 0, 0, 0, .... , 1, ... 0, 0, 0, 0)
一般来说词库量至少都是百万级别,因此词袋模型有个两个最大的问题:高纬度、高稀疏性
n-gram词袋模型:
与词袋模型类似,考虑了局部的顺序信息,但是向量的维度过大,基本不采用。如果词集合大小为N,则bi-gram的单词总数为N2向量空间模型
向量空间模型:
以词袋模型为基础,向量空间模型通过特征选择降低维度,通过特征权重计算增加稠密性。
特征权重计算:
一般有布尔权重、TFIDF型权重、以及基于熵概念权重这几种方式,其中布尔权重是指若出现则为1,否则为0,也就是词袋模型;而TFIDF则是基于词频来进行定义权重;基于熵的则是将出现在同一文档的特征赋予较高的权重。
3.1.3 机器学习分类器
将文本表示为模型可以处理的向量数据后,就可以使用机器学习模型来进行处理,常用的模型有:
- 朴素贝叶斯
- KNN方法
- 决策树
- 支持向量机
- GBDT/XGBOOST
3.2深度学习方法
上文介绍了传统的文本分类做法,传统做法主要问题的文本表示是高纬度高稀疏的,特征表达能力很弱,而且神经网络很不擅长对此类数据的处理;此外需要人工进行特征工程,成本很高。应用深度学习解决大规模文本分类问题最重要的是解决文本表示,再利用CNN/RNN等网络结构自动获取特征表达能力,去掉繁杂的人工特征工程,端到端的解决问题。
3.2.1 FastText:
论文:Bag of Tricks for Efficient Text Classification
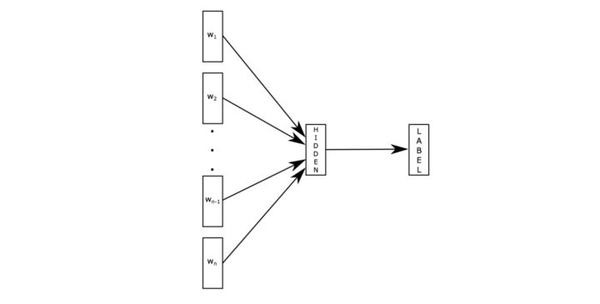
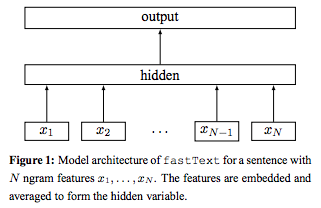
第一步:输入层
在word2vec中,它的输入就是单纯的把词袋向量化。但是在fasttext还加入了n-grams的思想。举个例子“我 喜欢 她“,如果只用这几个词的组合来反映这个句子,就是(”我”,”喜欢”,”她”),问题来了,句子“她 喜欢 我”的词的组合也是(”我”,”喜欢”,”她”),但这两个句子的意思完全不同,所以如果只用句子里的词来代表这个句子的意思,是不准确的,所以我们要加入n-grams,比如说取n=2,那么此时句子“我 喜欢 她“的词语组合就是(”我”,”喜欢”,”她”,”我喜欢”,”喜欢她”)这就和句子”她喜欢我”所得到的词语组合不同了,我们也能因此区分开这两个句子。
所以此时我们的输入就是(”我”,”喜欢”,”她”,”我喜欢”,”喜欢她”)向量化后的5个向量,词向量化参照。
第二步:中间层
其实这一步的思想更加朴素,就是将第一步中输入的向量相加再求平均,得到一个新的向量w,然后将这个向量输入到输出层。
第三步:输出层
采用了层次softmax的方法,思想实质上是将一个全局多分类的问题,转化成为了若干个二元分类问题,从而将计算复杂度从O(V)降到O(logV)。既根据label的频次建立哈夫曼树,每个label对应一个哈夫曼编码,每个哈夫曼树节点具有一个向量作为参数进行更新,预测的时候隐层输出与每个哈夫曼树节点向量做点乘,根据结果决定向左右哪个方向移动,最终落到某个label对应的节点上。
代码链接:https://github.com/liyibo/text-classification-demos
3.2.2 TextCNN:
论文:Convolutional Neural Networks for Sentence Classification
模型
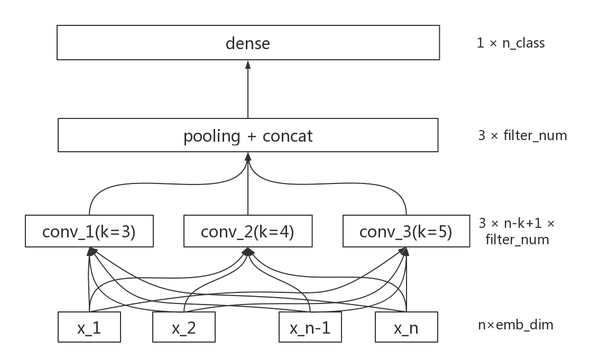
详细原理图:
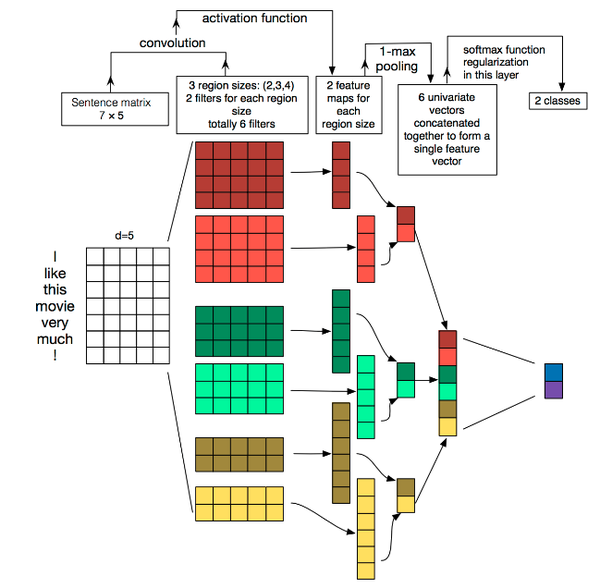
TextCNN详细过程:
- Embedding:第一层是图中最左边的7乘5的句子矩阵,每行是词向量,维度=5,这个可以类比为图像中的原始像素点。
- Convolution:然后经过 kernel_sizes=(2,3,4) 的一维卷积层,每个kernel_size 有两个输出 channel。
- MaxPolling:第三层是一个1-max pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示。
- FullConnection and Softmax:最后接一层全连接的softmax层,输出每个类别的概率。
注:考虑了卷积核具有局部感受野的特性
代码链接:https://github.com/liyibo/text-classification-demos
3.2.3 TextRNN:
论文:Recurrent Neural Network for Text Classification with Multi-Task Learning
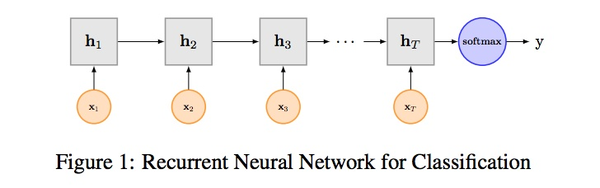
利用CNN进行文本分类,说到底还是利用卷积核寻找n-gram特征。卷积核的大小是超参。而RNN则可以处理时间序列,它通过前后时刻的输出链接保证了“记忆”的留存。但RNN循环机制过于简单,前后时刻的链接采用了最简单的f=activate(ws+b)。这样在梯度反向传播时出现了时间上的连乘操作,从而导致了梯度消失和梯度爆炸的问题。RNN的变种LSTM/GRU在一定程度上减缓了梯度消失和梯度爆炸问题,因此现在使用的其实要比RNN更多。
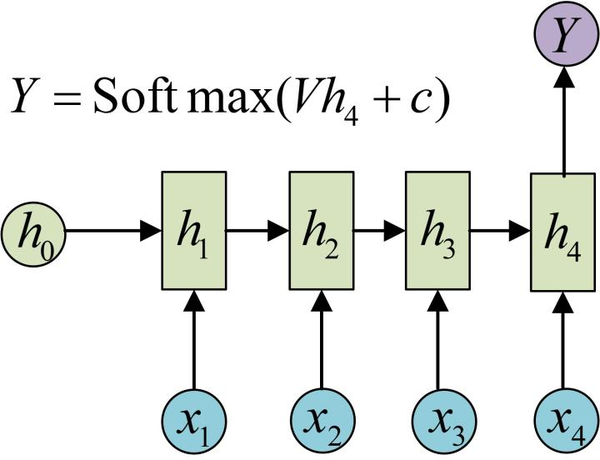
利用RNN做文本分类也比较好理解,其实就是一个N vs 1模型。对于英文,都是基于词的。对于中文,首先要确定是基于字的还是基于词的。如果是基于词,要先对句子进行分词。之后,每个字/词对应RNN的一个时刻,隐层输出作为下一时刻的输入。最后时刻的隐层输出h为整个句子的抽象特征,再接一个softmax进行分类。
详细的RNN的解释可以参考链接:https://zhuanlan.zhihu.com/p/28054589
代码链接:https://github.com/liyibo/text-classification-demos
3.2.4 RCNN
论文:Recurrent Convolutional Neural Networks for Text Classification
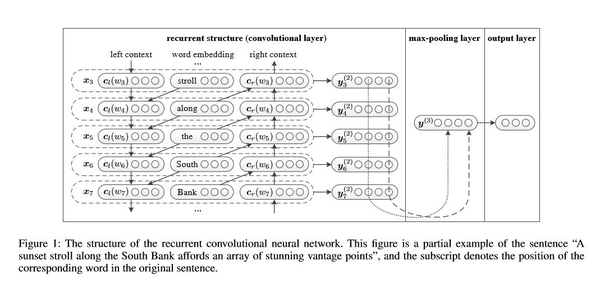
RCNN算法过程:
首先,采用双向LSTM学习word的上下文
c_left = tf.concat([tf.zeros(shape), output_fw[:, :-1]], axis=1, name="context_left")
c_right = tf.concat([output_bw[:, 1:], tf.zeros(shape)], axis=1, name="context_right")
word_representation = tf.concat([c_left, embedding_inputs, c_right], axis=2, name="last")
之后再接跟TextCNN相同卷积层,pooling层即可,在seq_length维度进行 max pooling,然后进行fc操作就可以进行分类了,可以将该网络看成是fasttext 的改进版本。
代码链接:https://github.com/liyibo/text-classification-demos
3.2.5 HAN
论文:Hierarchical Attention Network for Document Classification
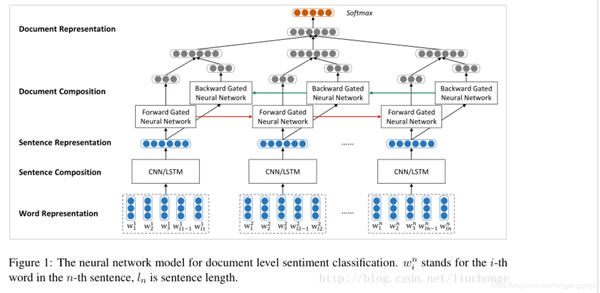
HAN为Hierarchical Attention Networks,将待分类文本,分为一定数量的句子,分别在word level和sentence level进行encoder和attention操作,从而实现对较长文本的分类。
本文是按照句子长度将文本分句的,实际操作中可按照标点符号等进行分句,理论上效果能好一点。
算法流程:
- word encoder:对词汇进行编码,建立词向量。接着用双向 GRU 从单词的两个方向汇总信息来获取单词的注释,因此将上下文信息合并到句子向量中。
- word attention:接着对句子向量使用 Attention 机制。将输入的lstm编码结果做一次非线性变换,可以看做是输入编码的hidden representation。将 hidden representation 与一个学习得到的 word level context vector 的相似性进行 softmax,得到每个单词在句子中的权重。对输入的lstm 编码进行加权求和,得到句子的向量表示
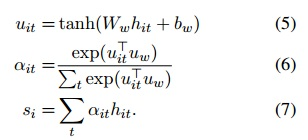
- sentence encoder:与上面一样,根据句子向量,使用双向 GRU 构建文档向量。
- sentence attention:对文档向量使用 Attention 机制。
- softmax:常规的输出分类结果。
3.2.6 DPCNN
论文:Deep Pyramid Convolutional Neural Networks for Text Categorization
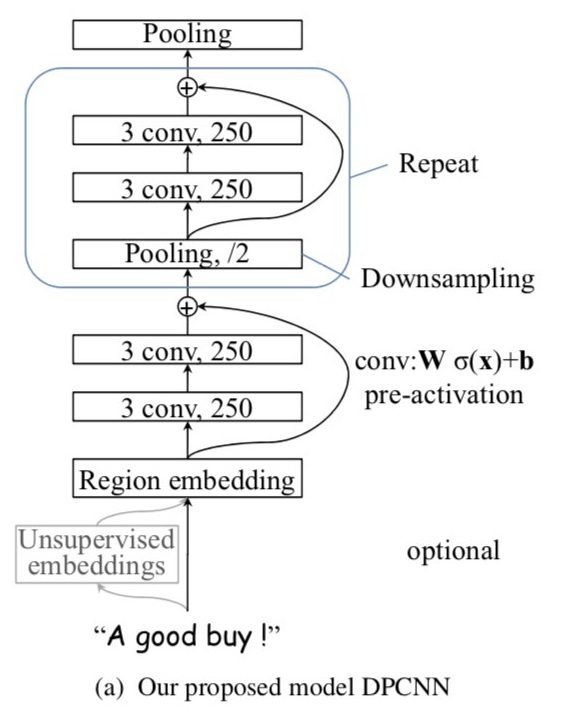
DPCNN主要的特色是引入了残差结构,增加了多尺度信息,并且增加了用于文本分类CNN的网络深度,以提取文本中远程关系特哼,并且并没有带来较高的复杂度。实验表明,其效果比普通CNN结构要好。
代码链接:https://github.com/liyibo/text-classification-demos
Bert:
论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
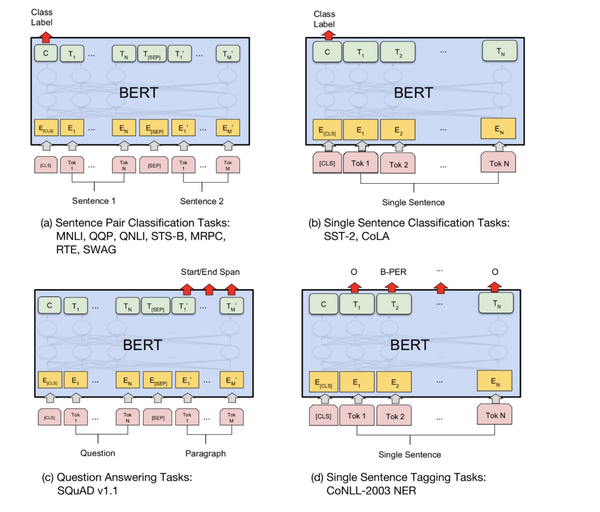
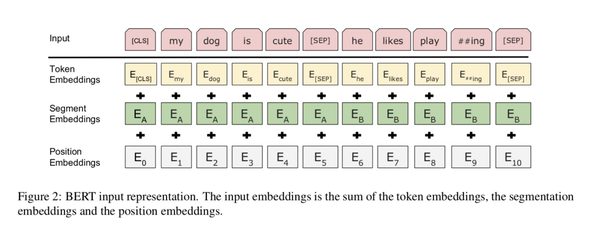
BERT是一种预训练语言表示的方法,他将NLP模型的建立分为了两个阶段:Pre-training和fine-tuning。Pre-training是为了在大量文本语料(维基百科)上训练了一个通用的“语言理解”模型,然后用这个模型去执行想做的NLP任务。Fine-training则是在具体的NLP任务上进行相应的微调学习。
Bert模型结构主要是采用了transformer的编码结构,其主要创新点在于其训练方式采用了1)它在训练双向语言模型时以减小的概率把少量的词替成了Mask或者另一个随机的词。感觉其目的在于使模型被迫增加对上下文的记忆。2)增加了一个预测下一句的loss,迫使模型学习到句子之间的关系。
输入表示:
论文的输入表示(input representation)能够在一个token序列中明确地表示单个文本句子或一对文本句子(例如, [Question, Answer])。对于给定token,其输入表示通过对相应的token、segment和position embeddings进行求和来构造。图2是输入表示的直观表示:
关键创新:预训练任务
任务1: Masked LM
为了训练一个深度双向表示(deep bidirectional representation),研究团队采用了一种简单的方法,即随机屏蔽(masking)部分输入token,然后只预测那些被屏蔽的token。
数据生成器将执行以下操作,而不是始终用[MASK]替换所选单词:
- 80%的时间:用[MASK]标记替换单词,例如,my dog is hairy → my dog is [MASK]
- 10%的时间:用一个随机的单词替换该单词,例如,my dog is hairy → my dog is apple
- 10%的时间:保持单词不变,例如,my dog is hairy → my dog is hairy. 这样做的目的是将表示偏向于实际观察到的单词。
任务2:下一句预测
在为了训练一个理解句子的模型关系,预先训练一个二进制化的下一句测任务,这一任务可以从任何单语语料库中生成。具体地说,当选择句子A和B作为预训练样本时,B有50%的可能是A的下一个句子,也有50%的可能是来自语料库的随机句子。
通过采用以上两种预训练方式,使得模型能够具有语义表征性质,在fine-tuning阶段就可以搭连一个NN结构完成文本分类任务。
代码链接:https://github.com/google-research/bert
3.2.7 Densely Connected CNN
论文:Densely Connected CNN with Multi-scale Feature Attention for Text Classification
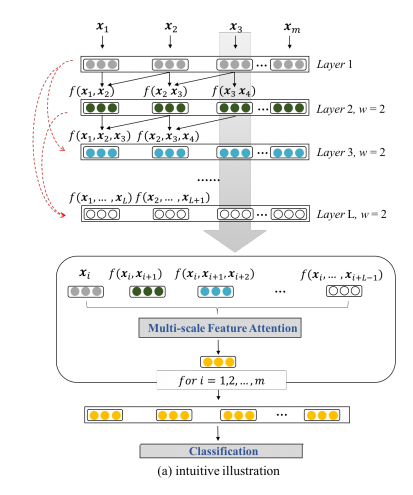
如果说DPCNN算法是借鉴了计算机视觉中ResNet模型中残差块的想法,那么Densely Connected CNN则是借鉴了DenseNet的密集型连接的做法。Densely Connected CNN主要采用short-cut操作将之前卷积提取出的feature加入到后续层的输入,增加了多尺度信息的提取,使得卷积器真正观测到的原始句子序列中的视野是越来越大的。其次,模型对不同尺度的feature采用了attention的做法,使得模型更好的利用feature信息。
代码链接:
https://github.com/wangshy31/Densely-Connected-CNN-withMultiscale-Feature-Attention.git
3.2.8 GNN:TextGCN
论文:Graph Convolutional Networks for Text Classification
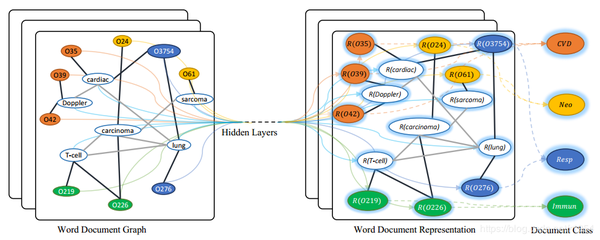
图中节点的数量是单词数量+文档数量,O开头的是文档节点,其他的是词节点。图中黑线的线代表文档-词的边,灰色的表示词-词的边。R(x)表示x的embedding表示。节点的不同颜色代表文档的不同类型。
本文提出的TextGCN的初始输入向量是词和文档全部用one-hot编码表示。文档-词的边基于词在文档中的出现信息,使TF-ID作为边的权重。词-词的连边基于词的全局词共现信息。词共现信息使用一个固定大小的滑动窗口在语料库中滑动统计词共现信息,然后使用点互信息(PMI)计算两个词节点连线的权重。

这里的A是图G的邻接矩阵,D是图G的度矩阵。W0和W1分别是GCN第一层和第二层可学习的卷积核权重,也是需要被训练学习的。X是输入特征矩阵,是与节点数相同的维度的对角方形矩阵,这意味着输入是图中每个节点的one-hot编码。最后将输出送到具有softmax函数的层,用于文本的分类。
代码链接:https://github.com/yao8839836/text_gcn
3.2.9 Capsule Networks:
论文:Investigating Capsule Networks with Dynamic Routing for Text Classification
Zhao等人提出了一种基于胶囊网络的文本分类模型,并改进了Sabour等人提出的动态路由,提出了三种稳定动态路由。模型如下所示:
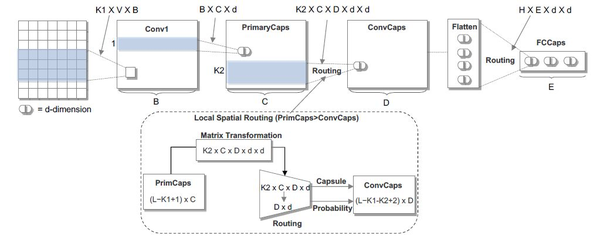
该模型首先利用标准的卷积网络,通过多个卷积滤波器提取句子的局部语义表征。然后将CNN的标量输出替换为向量输出胶囊,从而构建Primary Capsule层。接着输入到作者提出的改进的动态路由(共享机制的动态路由和非共享机制的动态路由),得到卷积胶囊层。最后将卷积胶囊层的胶囊压平,送入到全连接胶囊层,每个胶囊表示属于每个类别的概率。
代码链接:https://github.com/andyweizhao/capsule_text_classification.
3.2.10 Semi-supervised Text Classification
论文:Variational Pretraining for Semi-supervised Text Classification
此篇论文讲述,一般的半监督的文本分类模型基于大量数据和高昂计算力,导致他们在资源受限的环境下使用受限。于是,作者提出了一种基于预训练半监督的文本分类轻量型模型。
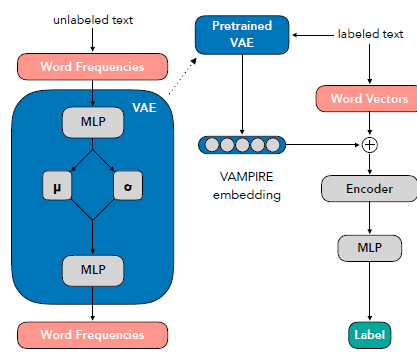
此模型称之为VAMPIRE,它将variational autoencoder与document modeling相结合。
算法流程:
- 将大量未标记文本提取出Word Frequencies,导入到上图右侧中的VAE模型中进行预训练,以获得重塑的Word Frequencies表示。模型内部使用了包括前向反馈模型和带有参数的、的softmax来进行pretrain。
- 将带有label的文本数据,分别通过已训练好的VAE模型与word vector模型来获得不同的词向量,之后进行编码送入到MLP中分类即可。
代码链接:http://github.com/allenai/vampire
3.2.11 XLNet:
论文:XLNet: Generalized Autoregressive Pretraining for Language Understanding
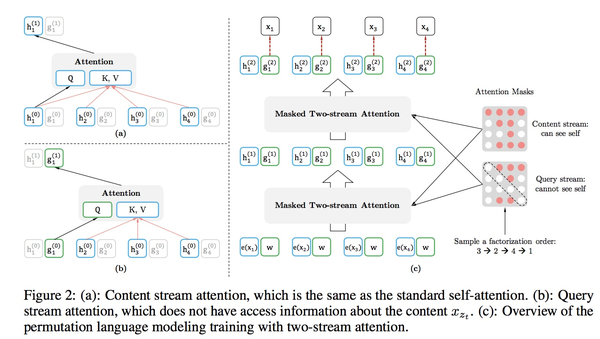
XLNet引入了自回归语言模型(根据上文内容预测下一个可能跟随的单词,就是常说的自左向右的语言模型任务)以及自编码语言模型(只能根据上文预测下一个单词,或者反过来,只能根据下文预测前面一个单词)的想法,能够同时利用上文和下文,所以信息利用充分。而BERT则是在第一个预训练阶段因为采取引入[Mask]标记来Mask掉部分单词的训练模式,而Fine-tuning阶段是看不到这种被强行加入的Mask标记的,所以两个阶段存在使用模式不一致的情形,这可能会带来一定的性能损失;另外一个是,Bert在第一个预训练阶段,假设句子中多个单词被Mask掉,这些被Mask掉的单词之间没有任何关系,是条件独立的,而有时候这些单词之间是有关系的。
明白了两者的差异后,我们就容易发现XLNet的思路也就比较简洁,一般来讲,自回归语言模型有个缺点,要么从左到右,要么从右到左,如果我们要根据上文,来预测某个单词Ti,那么它就没法看到下文的内容信息。怎么让模型具有从左向右的输入和预测模式,而且内部又引入了当前单词的上下文信息,则是XLNet主要的创新点。
具体的做法是,XLNet在第一阶段预训练时期,选择舍去mask操作,将顺序输入的句子进行随机排列组合。例如,句子输入顺序为:X1,X2,X3,X4,在transformer阶段采用了Attention掩码机制,将句子顺序变为X4,X2,X1, X3、X3,X2, X1, X4等等这样的序列,这样在X4,X2,X1, X3中,X1便可以看到X4,X2,的信息,在X3,X2, X1, X4序列中,X1便可以看到X3,X2的信息。
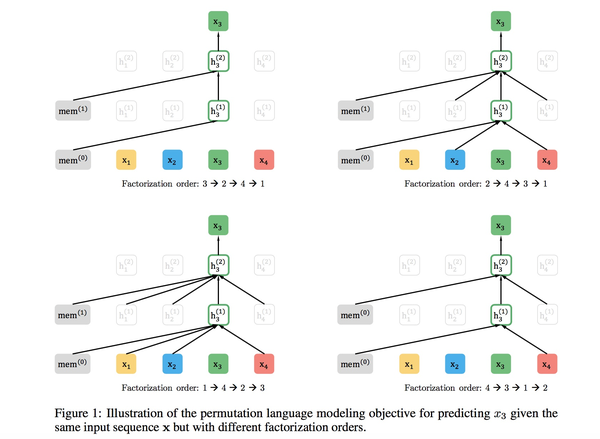
如上图所示,我们在预测X3时,右上角图所示中序列为X2, X4 ,X3,X1,因此在预测X3时,使用了X2, X4的信息,其他图以此类推。
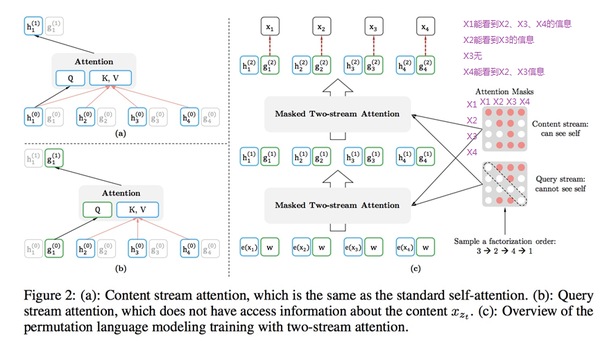
那么Attention掩码机制是什么意思呢?我们通过上图来进行解释,如果把白色看成掩盖,红色看作为能看到信息,那么在右侧的Attention矩阵中可以看出,我们一行一行对应来看,就能看到每个X看到的信息在Attention矩阵中已经表达出来,最后的顺序也就变成了X3X2X4X1。
[此部分为双流自注意力机制]然而,这些都还不够。这种预训练方法可能会带来歧义。在一个句子里,我们有可能针对不一样的目标词,产生出一模一样的context。还是用名句"山下一群鹅,嘘声赶落河",假设我们的分段长度为11,把整个句子(含标点)都包括进来了。这时针对"鹅"字,在众多的排列中,我们可以有一个自然的序列"山下一群"来预测它。同样针对"河"字,我们在众多排列中,也可以有一个排序过的序列"山下一群"来预测它。那么一模一样的序列(“山下一群”)竟然用来预测两个不同的字,这导致了"鹅"和"河"在此时共享一样的模型的预测结果。(参考triplemeng博客)。
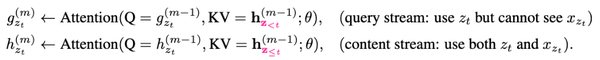
为了解决这个问题,一个简单的想法就是引入对位置的依赖,用一个新的函数 表示,通过加入不同的被预测词的位置,把上述情况区分开了
在模型中,同时利用g和h,所谓的双流即query stream和content stream,在fine-tuning阶段,可以完全忽略掉第一个公式,仅利用content stream就可以了。
其中:
query stream为:为预测token,只能利用它的位置信息即,但不利用。这里的称为query representation。
content stream为:在预测其他token时,需要编码信息来提供语境信息,所以这里需要content representation,。
代码链接:https://github.com/zihangdai/xlnet
3.2.12 Transformable Convolutional Neural Network
论文:Transformable Convolutional Neural Network for Text Classification
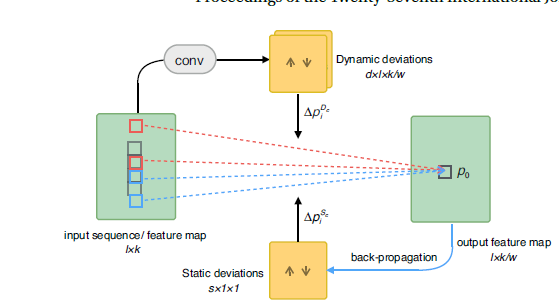
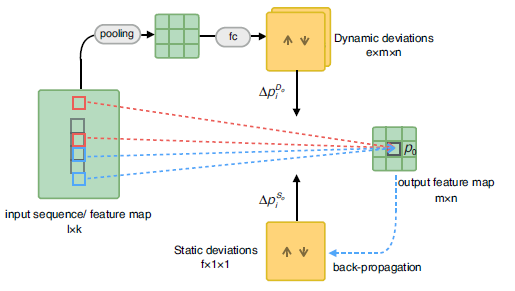
这篇论文主要创新点在于提出了Transformable Convolution 和Transformable Pooling两个处理方式,主要目的在于想通过以上两种方式来获取静态特征信息和动态特征信息。
对于Transformable Convolution(Transformable Pooling也是同样的道理),文章将filter(卷积核)中position(p)的集合称之为C,为了将一部分的position与当前状态的feature相关联,将另一部分与global信息关联,把C分为了两部分S和D,每一部分单独进行参数更新和计算。如上图右上角,D中信息是通过上层feature map卷积获得的动态信息,而S则是上图底部,通过反向传播更新获得的全局信息。最后将这两种信息通过以下公式进行综合计算。
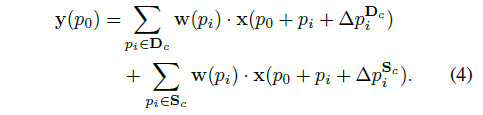
文章指出,直接采取卷积核在实际使用中不易处理,所以在计算方式上采用了一种mask的方式,使得矩阵相乘时得以实现分块计算。
代码链接:无
3.2.13 A Generative Explanation Framework for Text Classification
论文:Towards Explainable NLP: A Generative Explanation Framework for Text Classification
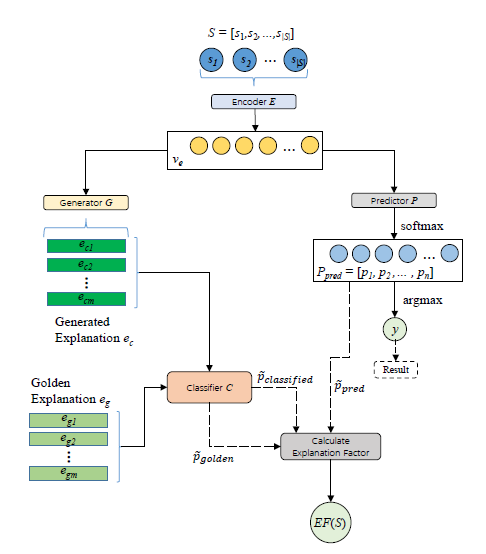
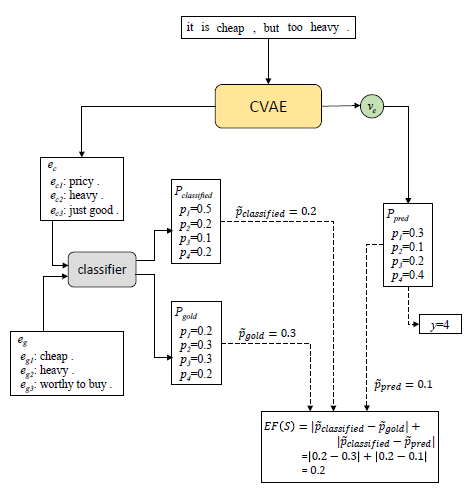
一般来讲,分类模型只会给出一个类别概率分布,无法给出解释性指标,来表明分类是否可信,所以Generative Explanation Framework的想法是:给出一个商品A,它具有quality, practicality, price三个属性,若模型给出商品A为good,并且能够指出分类理由是基于商品A的[quality:HIGH,practicality:HIGH,price:LOW]性质,我们就认为这样的做法具有可解释性。
因此,该方法数据样本具有三个part:一个商品的描述文本、三个简评、一个总体分数。此框架想通过使用描述文本数据训练一个分类模型得到分类的类别y以及Ppred,之后再利用上图左侧classifier C得到的Pgold ,Pclassified分数,将三个P放入到度量公式EF(s)中得到分类的置信度。
代码链接:无
以上是关于文本分类:survey的主要内容,如果未能解决你的问题,请参考以下文章