OpenStack总体架构概览&OpenStack核心组件介绍
Posted wn1m
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OpenStack总体架构概览&OpenStack核心组件介绍相关的知识,希望对你有一定的参考价值。
下面个是51CTO上一位朋友发布的O版OpenStack核心组件说明,总结的非常到位,所以我就不再造轮子了.~,~
https://down.51cto.com/data/2448945
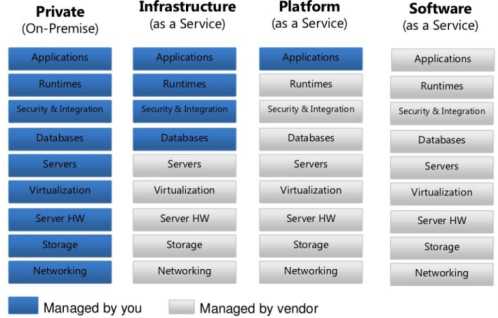
私有云
公有云
混合云
IaaS(基础架构即服务):OpenStack,CloudStack
PaaS(平台即服务):Docker,Openshift
SaaS(服务即服务):主要面对终端用户,可通过一个浏览器就可以实现使用任何应用,而无需安装。
DBaaS(Database as a Service)
FWaaS(Firewall as a Service)
异步队列服务:接收创建、启动、删除等等任务的队列,当同时要启动200个VM实例时,我只需将启动VM的请求放到异步队列中后,
我就开始干其它事情了。
OpenStack的组件:
OpenStack的API风格为:RESTful,它可以兼容AWS(亚马逊云)、S3;即Openstack可直接调用AWS或S3上的应用,
也可以直接在AWS、S3上调用OpenStack的应用;可非常方便的组件混合云。
核心组件:
1. 服务名:Compute(代码名:Nova) :它主要用来管理VM实例的完整生命周期,启动、资源分配、关闭、销毁、运行中SSH密钥注入、SSH连接的提供等,均由它来提供。
2.服务名:Networking(代码名:Neutron):早期由Nova,即Compute来提供,从F版(Folsom release)开始独立出来,用于提供网络连接服务,它采用插件设计,支持众多流行的网络管理插件.
3.Storage :分两个组件,一个为Block存储(Cinder), 另一个为对象存储(Swift)
对象存储:类似于VMware的磁盘文件,但VMware的磁盘文件并非是对象存储,对象存储是自身包含自身的元数据,即便将它放到一个没有文件系统的磁盘上,它也能自我管理。OpenStack采用Swift这个重量级的分布式存储系统,是因为开发该系统的公司是OpenStack的早期发起人之一,并且该公司还将自己的分布式存储系统贡献给OpenStack作为其对象存储系统,该系统就是Swift。
Object Storage: 代码名:Swift,它是通过RESTful接口来存储和检索非结构化的数据对象,它是一个高容错可伸缩的存储架构。
Block Storage:代码名:Cinder,早期由Nova,即Compute组件来提供,从F版开始独立出来,它主要为VM提供持久的块存储的组件。
4. Identify,代码名: Keystore ,它为除自身外的其它所有组件提供了一个认证和授权的服务及端点编录服务,即类似与目录服务的功能,可通过它检索所有组件的访问路径。
5. Image,代码名:Glance,它是作为Swift的前端,用来提供存储对象元数据检索的,简单说:即VM启动前需要知道磁盘镜像文件存在哪,它就需要访问Image服务来检索,Image服务上存储了所有Swift的存储位置信息,它会告诉VMclient到哪去下载镜像,然后,VMclient再自己去找。
6. Dashboard(用户交互界面)(Horizon) :它是一个与OpenStack个组件交互的基于Web的访问接口。
7. Telemetry,代码名:Ceilometer, 监控和计量VM,计量:即根据用户使用VM的资源来收费,如:你使用了多少RAM、CPU、网络带宽、磁盘空间等等。
8. Orachestration:代码名:Heat, 基于模板格式或AWS的CloudFormation模板格式来实现快速将多个资源联动起来,完成统一服务功能.简单理解:基于模板来实现系统管理.
9. Database: 代码名:Trove, 用来提供DBaaS的组件。
10.Data processing: 代码名:Sahara(沙哈拉), 用于在OpenStack中实现Hadoop的按需可伸缩的管理。
OpenStack各组件间的交互图
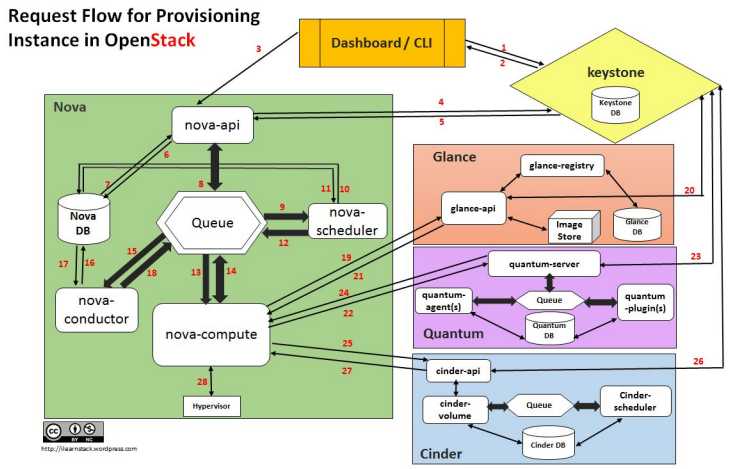
各组件间交互的简略描述:
1.通过Dashboard/CLI(OpenStack命令行接口)/自己开发的创建VM的界面,要启动VM,需先到Keystore认证并登录,接着用获得的Token,来访问Nova-API.
2.Nova-API它是接收用户请求的调用接口,它需要监听在一个套接字上,来通过TCP/IP协议来访问.当Dashboard/CLI发过来请求后,Nova-API会先验证它的Token是否合法,若合法则接收请求。接着向Nova-DB(mysql)请求查询该VM,Nova-DB从已创建的VM中查询,若有要启动的VM则获取该VM的信息(如:实例名/RAM大小/CPU/磁盘等信息),并将这些信息返回给Nova-API。
3.当Nova-API获得的VM的信息后,Nova-API会将该VM信息组织成Hypervisor或Nova-compute上借助Hypervisor来操作VM的特定请求包,并发送给Hypervisor或Nova-compute,由它来负责操作VM, Nova-API和Nova-compute的交互是异步的,它们中间隔着一个队列.;
【注: Nova-API它仅是用来接收VM操作请求,验证是否有权限操作VM,并获取VM信息交给Hypervisor来完成VM的实际管理操作.】
4.Nova-API将特定请求包丢入队列后,Nova-Scheduler会获得这些请求,并为该请求调度选择运行节点,完成后,Nova-scheduler会将该调度信息再次丢入队列中,同时向Nova-DB发送VM已启动的更新信息,Nova-DB更新完该VM的状态后,会通知Nova-scheduler.
5.Nova-compute可以看成是具体的一个物理实体机,它会从队列中获取Nova-scheduler发出的调度信息,并判断是否是自己的任务,若是则获取该启动VM的任务,并生成VM的已在启动中的状态信息,在丢入队列中。
6.当Nova-conductor发现Nova-compute丢入队列中的VM状态更新信息后,它会读取该信息,并将该信息发给Nova-DB来更新该VM的状态,当Nova-DB更新完成后,Nova-DB会通知Nova-conductor,接着Nova-conductor会将该信息丢入队列,当Nova-compute检测到Nova-conductor丢入的更新成功的信息后,Nova-compute便开始进行接下来的VM启动步骤。
7.当知道VM更新信息已经完成后,Nova-compute开始向glance-API请求启动该VM的磁盘镜像,这时glance-API会先从通过glance-registry来查询glance-DB看是否存在该VM的磁盘信息,若有则glance-registry会将该磁盘镜像信息返回给glance-API,然后,glance-API会先到Keystore验证该Nova-compute提供的Token是否合法,若合法,则通过该VM磁盘镜像信息到Image Store中去下载该VM启动的磁盘镜像文件,并返回给Nova-compute。
8.quantum-server: 它是负责为VM创建网络基础设施的,如:构建虚拟网桥,虚拟路由器并添加相应转发规则,甚至是NAT; quantum-server是一个非常繁忙的系统,因为它需要为每个VM创建网络基础设施,但quantum-server并不直接为VM创建网络基础设施,而是将请求丢入到quantum子系统内部的队列中。
9.相应的quantum-plugin会从quantum子系统内部的队列中读取构建网络设施的信息,并通过查询Quantum-DB来判断那些部分在真正运行VM的Nova-compute上创建(如:创建网桥就需要在本地创建.),那些在quantum上创建,若需要在运行VM的节点上创建,则quantum-plugin会将这些信息丢入内部队列中,Nova-compute上运行的quantum-agent会从quantum内部队列中获得这些信息,并在本地创建相应的网络基础设施,完成后,quantum-agent会将完成信息发送给Quantum-DB来更新该网络基础设施的状态信息。【注:quantum-server也会在收到Nova-compute的请求到Keystore上去验证是否有合法。】最后,quantum-server会通告Nova-compute网络已经构建完成。
10.Nova-compute会从获得的启动VM的信息中看是否需要加载它曾经关联过的Block设备,若有则向cinder-API发起请求,cinder-API会先将请求信息发给cinder-volume,由它来查询Cinder-DB看是否存在Nova-compute请求的Block设备,若有则cinder-volume会通知cinder-API,cinder-API在向Keystore发起验证请求,验证通过后,cinder-api会直接将Block设备信息返回给nova-compute,若这是一个创建Block的请求,则cinder-volume会将Block信息丢入cinder内部队列中,由cinder-scheduler从cinder-DB中获取后端存储的信息,并根据要创建Volume的大小,VolumeType,所需具有的特性等信息,从后端存储主机中选出一个最匹配的,并将结果写入cinder队列中,cinder-volume通过该信息在存储节点上调用相应的存储驱动创建volume,创建完成后将这些信息写入cinder-db中,最后cinder-volume告诉cinder-api,cinder-api在返回信息给nove-compute.
Controller Node + Network Node + Compute Node 这种三节点OpenStack架构是OpenStack的最小结构。
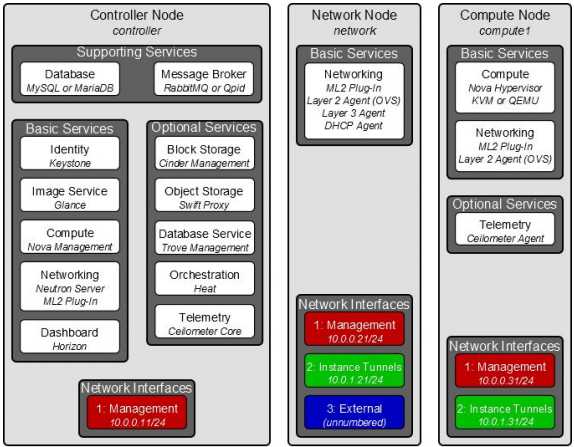
Controller Node:
基础服务:
1.Identity(认证)服务。即Keystore
2.Image Service.
3.compute的Nova Management。
4.Networking: Neutron server, ML2 Plug-in.
5.Dashboard :图形管理界面
支持服务:
1.Database MySQL or MariaDB
2.Message Broker: RabbitMQ or Qpid,它是用来为基础服务和数据库连接提供缓存区的。
它至少需要一个网卡接口,来作为管理接口。
1.需要注意: 若需要向外网提供公有云服务,则应该还需要改Controller Node提供一个外网访问网卡.
以便外部可调用Cinder提供的Block Storage或Object Storage,以及Image Service.
Network Node:
需要提供基础的Networking服务,该服务包含:
ML2 Plug-in(第二层插件),
Layer2 Agent(第二层代理:OVS): OVS是用来构建桥、VLAN、VxLAN、GRE、与Network Node节点通信均有它来完成。
Layer3 Agent(第三层代理):创建NAT NS并构建NAT规则,iptables过滤规则、路由转发规则等
DHCP Agent:用来提供DHCP服务,为VM提供动态地址分配管理。
它需要提供三个网卡接口:
1.Management 接口。
2.与实例构建隧道的接口.
3.与外网连接的接口。
Compute Node:
它是运行VM的基本节点。它可以有非常多。
它需要运行的基础服务:
1.Compute(计算服务):Nova Hypervisor; KVM or QEMU
2.Networking: ML2 Plug-in, Layer2 Agent(OVS)
它需要两个网卡接口:
1. Management接口
2.构建Tunnel的接口。
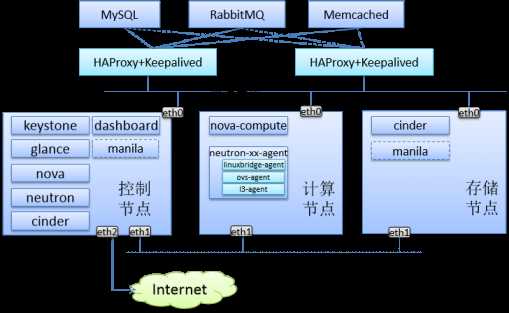
控制节点需要哪些必要组件?
对于控制节点来说,最主要的组件有 nova(nova-api, nova-sheduler,nova-conductor等),neutron-server(neutron的二层,三层,元数据代理),Glance(镜像服务),keystone(认证服务),通常也都会部署cinder服务,因此控制节点一般这些基础服务端进程是需要运行在控制节点的,但有时也需要使用想manila,heat这些服务,也需要在控制节点部署,但heat我研究不多,我的实践中,nova,neutron,glance,keystone,cinder是必须要配置的,像我们启动一台VM,首先就要访问nova-api,由nova-api来访问keystone验证用户提供的凭据,身份验证通过后,才会将请求做进一步处理,比如说要创建VM,nova-api就会将请求发给nova-sheduler,而它会查询nova数据库,获取当前所有计算节点上资源的使用情况,并根据调度算法,选出一个最佳的计算节点,并将创建VM的请求发送到对应的消息队列的管道中,这样所有订阅了这个管道的计算节点上的nova-compute就都能收到,并解析请求,若是自己的任务,就会在自己的节点上启动创建VM的任务,当然这个过程涉及到了前面提到的所有组件,比如它会先访问glance获取创建VM的镜像,随后访问neurton创建必须的网络,最后还会访问cinder获取VM所需要挂载的云盘信息等等,最后还要通知nova-conductor将VM的启动状态写入nova数据库中,当然这启动之初就会先告知nova-conductor,这样我们在前端Dashboard上才能看到VM的启动状态到那一步了,所以状态报告是每个阶段都需要有的. 另外像neutron,它通常会在用户创建网络时,如二层网络,或虚拟路由器等,会由neutron-server通过消息队列通知各个计算节点上的neutron-代理来完成计算节点上基础虚拟网桥的创建。
另外我在实践中发现,像消息队列服务,通常使用rabbitmq,缓存及Session保持常用memcached,数据库通常用Mariadb,并且这三个服务最好分别部署,一般部署测试环境时,会将它们单独放到一台主机上来部署,前面用HAProxy或nginx+Keepalived,这样部署会尽可能降低消息队列,缓存及数据库的压力,降低瓶颈,不会出现mysql挂了,所有服务都不能正常工作,mysql做双主会多些,但使用时,还按照主从方式用.
计算节点通常需要哪些组件?
对于计算节点来说,通常需要运行nova-compute,这是最基本的,因为控制节点上nova-api验证用户完用户身份后,就以创建VM为例来说,它会将创建VM的任务交给nova-scheduler,由它来从查询nova数据库获取每个计算节点的信息,比如内存,磁盘,CPU等信息,找一个资源最富裕的计算节点,并通过消息队列,通知给订阅了该消息通道的nova-compute,nova-compute就需要在当前计算节点与底层的hapyervsior通信,不过基本是跟libvirtd通信,因为libvirtd已经统一了底层绝大部分haypervsior,在Linux上通常做IaaS层面的私有云,首选通常是KVM+Qume,不过若硬件不支持虚拟化,就只能使用Qume这种模拟器了,不过对于服务器来说这是不可能的。能创建VM,但也必须让用户能访问它才行,所以,neutron的代理是必须要安装的,neutron就是通过如linuxbridge-agent,ovs-agent这些计算节点上的网络代理来实现接受neutron-server通过消息队列发来的创建虚拟网络的指令,这样计算节点上就可以创建二层网桥,并自动将虚拟网线的一端安装到VM中,另一段连接到网桥上,当然若使用安全组,VM和虚拟网络之间就还需要一个网络名称空间来做安全策略,这样就可以能让VM连接的隧道网络上了,通常不会直接让VM连接的公网桥上的,而是通过tunnel network连接到Neutron-server端,在通过NAT来让VM上网的,但对于VM的远程管理,就比较复杂了,这一块主要涉及到nova的几个主要组件计算节点上的nova-compute,控制节点上的nova-consoleauth,nova-novncproxy,nova-api他们之间经过复杂交换,生成token,转换URL为公网可访问的URL,最后返回给用户的浏览器,最终用户才得以看到VM的管理控制台,这期间是不涉及neutron网络组件的。
以上是关于OpenStack总体架构概览&OpenStack核心组件介绍的主要内容,如果未能解决你的问题,请参考以下文章