tf.keras入门1——使用sequential model建立一个VGGlike模型
Posted ssozhno-1
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了tf.keras入门1——使用sequential model建立一个VGGlike模型相关的知识,希望对你有一定的参考价值。
建立一个简单的模型
sequential model
sequential model是一个线性堆叠layers的模型。你既可以通过使用List加入layers的方法初始化,也可以通过.add方法添加layers。
为了建立一个简单的模型,这里以一个全连接层的多层感知机为例:
import tensorflow as tf from tensorflow import keras from keras import layers model = Sequential([ layers.Dense(32, activation=‘relu‘), layers.Dense(64, activation=‘relu‘), layers.Dense(10, activation=‘softmax‘), ])
OR
import tensorflow as tf from tensorflow import keras from keras import layers #instance a Sequential model model = tf.keras.Sequential() # Adds a densely-connected layer with 64 units to the model: model.add(layers.Dense(64, activation=‘relu‘)) # Add another: model.add(layers.Dense(64, activation=‘relu‘)) # Add a softmax layer with 10 output units: model.add(layers.Dense(10, activation=‘softmax‘))
Specifying the input shape
模型需要知道他应该期望的输入shape。出于这个原因,sequential model中第一层(也只有第一层,因为后面的层可以进行自动判断形状)需要接收有关其输入shape的信息。具体方法如下:
- 在第一层参数中添加input_shape=(64,),这个input_shape是一个元组,如果不填写(或=None)表示任何正整数都可以,在input_shape中不包括batch的维度。
- 而在2D layers中,比如Dense可以通过参数input_dim支持输入shape。而在某些3D temporal layers则通过参数input_dim和input_length来支持。
- 如果你需要为输入指定固定的批处理大小,则可以将batch_size参数传给layer。如果你想传递batch_size=32,而input_shape=(6,8)传给layers,则每一层期望的输入为(32,8,6)
- 更多关于全连接层的相关参数可以查看
tf.keras.layers.Dense,包括kernel_regularizer即L1L2正则化,activation激活函数等等。
比如下面这个例子两种形式都是一样的效果:
import tensorflow as tf from tensorflow import keras from keras import layers model = Sequential() model.add(layers.Dense(32,input_shape=(784,))) # the same as: # model = Sequential() # model.add(layers.Dense(32,input_dim=784))
Compilation
在训练模型之前,我们需要配置学习过程,这是通过compile方法(是tf.keras.Model类的方法)完成的。参数如下:
compile( optimizer, loss=None, metrics=None, loss_weights=None, sample_weight_mode=None, weighted_metrics=None, target_tensors=None, distribute=None, **kwargs )
其中最重要的三个参数:
An optimizer:他可以是现有的优化器(比如rmsprop,adagrad)的字符串标识符,也可以是Optimizer 类的实例化。
A loss function:这个是模型试图最小化的目标,他可以是现有的损失函数的字符串标识符(比如categorical_crossentropy, mse),也可以是自定义的目标函数。详见:losses
A list of metrics:对于任何分类问题,您需要将其设置为metrics = [‘accuracy‘]。要为多输出模型的不同输出指定不同的度量,您还可以传递字典,例如metrics = ‘output_a‘:‘accuracy‘,‘output_b‘:[‘accuracy‘,‘mse‘]。 您还可以传递指标列表的列表(len = len(输出)),例如metrics = [[‘accuracy‘],[‘accuracy‘,‘mse‘]]或metrics = [‘accuracy‘,[‘precision) ‘,‘mse‘]]。metrics可以是现有度量的字符串标识符或自定义度量函数。
简单例子如下:
# For a multi-class classification problem model.compile(optimizer=‘rmsprop‘, loss=‘categorical_crossentropy‘, metrics=[‘accuracy‘]) # For a binary classification problem model.compile(optimizer=‘rmsprop‘, loss=‘binary_crossentropy‘, metrics=[‘accuracy‘]) # For a mean squared error regression problem model.compile(optimizer=‘rmsprop‘, loss=‘mse‘) # For custom metrics import tensorflow as tf from tensorflow,keras import backend as K def mean_pred(y_true, y_pred): return K.mean(y_pred) model.compile(optimizer=‘rmsprop‘, loss=‘binary_crossentropy‘, metrics=[‘accuracy‘, mean_pred])
Training
Keras模型在Numpy输入数据和标签整列上进行训练,对于训练模型,通常使用fit函数。
fit( x=None, y=None, batch_size=None, epochs=1, verbose=1, callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0, steps_per_epoch=None, validation_steps=None, validation_freq=1, max_queue_size=10, workers=1, use_multiprocessing=False, **kwargs )
其中输入参数
x:输入数据,他可以是一个numpy 数组,也可以是tensorflow的tensor(或者 a list of tensor),可以是一个tf.data类,也可以是一个generator等等。
y:目标数据,x一样也可以是numpy或tensor,他应该和x具有一致性。
batch_size:整数或者None。代表样本进行一次梯度下降的数量。如果没写,默认是32。
epoch:整数。
callback:keras.callbacks.Callback的实例化的list。see:tf.keras.callbacks
validation_split:0到1之间的浮点数。
返回:
一个history对象,他的history.history属性是一个记录了连续的训练损失值,metrics以及验证损失值和度量损失值。
Raises:
RuntimeError: If the model was never compiled.
ValueError: In case of mismatch between the provided input data and what th
最后我们写一个关于Faster RCNN 中前面Backbone是VGG的例子:


import numpy as np import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers # 生成虚假的数据 # 注意:1.np.random.random后面是两个括号。 # 学习如何使用tf随机100*100像素的3通道图像,100个 x_train = np.random.random((100,100,100,3)) y_train = keras.utils.to_categorical(np.random.randint(10,size=(100,1)),num_classes=0) x_test = np.random.random((20,100,100,3)) y_test = keras.utils.to_categorical(np.random.randint(10,size=(20,1)),num_classes=10) # 建立一个sequential模型。使用Faster RCNN 的VGG网络。 model = keras.Sequential() # input: 100x100 images with 3 channels -> (100, 100, 3) tensors. # this applies 64 convolution filters of size 3x3 each. # 输入的第一层需要输入input_shape,但是因为是在构建模型,所以不需要输入input,即不用feed数据的占位符。 # Conv2D的参数是:channel_out,kernel_size,stride=1,activation,padding=‘valid‘,data_format=‘channels_last‘(NHWC) # MaxPool2D的参数是:pool_size,strides=None, padding=‘valid‘, data_format=None # 其中strides=None即,strides=pool_size model.add(layers.Conv2D(64,(3,3),activation=‘relu‘,padding=‘same‘,input_shape=(100,100,3),name=‘conv1_1‘)) model.add(layers.Conv2D(64,(3,3),activation=‘relu‘,padding=‘same‘,name=‘conv1_2‘)) model.add(layers.MaxPool2D(pool_size=(2,2),name=‘pool1‘)) # ----------------------------------- model.add(layers.Conv2D(128,(3,3),activation=‘relu‘,padding=‘same‘,name=‘conv2_1‘)) model.add(layers.Conv2D(128,(3,3),activation=‘relu‘,padding=‘same‘,name=‘conv2_2‘)) model.add(layers.MaxPool2D(pool_size=(2,2),name=‘pool2‘)) # ----------------------------------- model.add(layers.Conv2D(256,(3,3),activation=‘relu‘,padding=‘same‘,name=‘conv3_1‘)) model.add(layers.Conv2D(256,(3,3),activation=‘relu‘,padding=‘same‘,name=‘conv3_2‘)) model.add(layers.Conv2D(256,(3,3),activation=‘relu‘,padding=‘same‘,name=‘conv3_3‘)) model.add(layers.MaxPool2D(pool_size=(2,2),name=‘pool3‘)) # ----------------------------------- model.add(layers.Conv2D(512,(3,3),activation=‘relu‘,padding=‘same‘,name=‘conv4_1‘)) model.add(layers.Conv2D(512,(3,3),activation=‘relu‘,padding=‘same‘,name=‘conv4_2‘)) model.add(layers.Conv2D(512,(3,3),activation=‘relu‘,padding=‘same‘,name=‘conv4_3‘)) model.add(layers.MaxPool2D(pool_size=(2,2),name=‘pool4‘)) # ----------------------------------- model.add(layers.Conv2D(512,(3,3),activation=‘relu‘,padding=‘same‘,name=‘conv5_1‘)) model.add(layers.Conv2D(512,(3,3),activation=‘relu‘,padding=‘same‘,name=‘conv5_2‘)) model.add(layers.Conv2D(512,(3,3),activation=‘relu‘,padding=‘same‘,name=‘conv5_3‘)) # ----------------------------------- model.add(layers.Flatten(name=‘flatten6‘)) model.add(layers.Dense(256, activation=‘relu‘,name=‘fc6‘)) model.add(layers.Dropout(0.5,name=‘dropout6‘)) model.add(layers.Dense(10, activation=‘softmax‘,name=‘fc7‘)) # 设置SGD参数lr learing rate, decay 衰减, momentum 动量? nesterov sgd = keras.optimizers.SGD(lr=0.001,decay=1e-6,momentum=0.9,nesterov=True) # 编译模型 model.compile(loss=‘categorical_crossentropy‘, optimizer=sgd) model.summary() model.fit(x_train, y_train, batch_size=32, epochs=10) score = model.evaluate(x_test, y_test, batch_size=32)
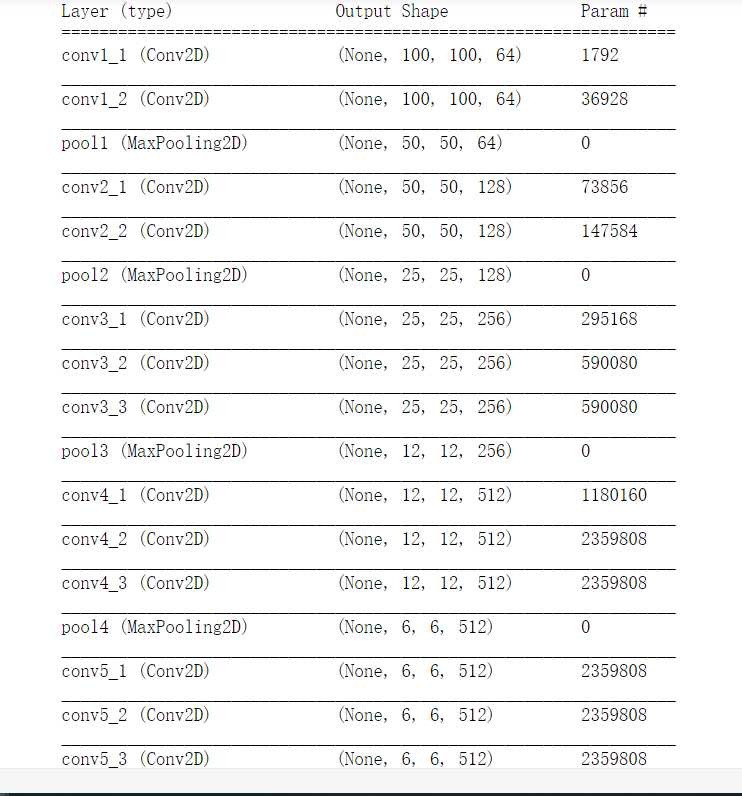
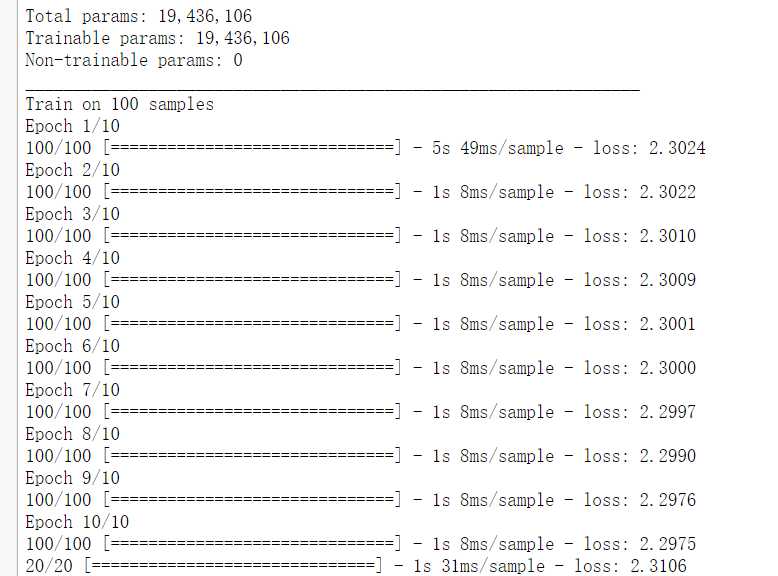
参考:https://keras.io/getting-started/sequential-model-guide/
https://tensorflow.google.cn/beta/guide/keras/overview
以上是关于tf.keras入门1——使用sequential model建立一个VGGlike模型的主要内容,如果未能解决你的问题,请参考以下文章