Machine Learning—支持向量机(SVM)
Posted lf6688
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Machine Learning—支持向量机(SVM)相关的知识,希望对你有一定的参考价值。
支持向量机是数据挖掘中的一项新技术,是借助于最优化方法来解决机器学习问题的新工具,它在解决小样本、非线性以及高维度模式识别中表现出许多优势,并能够推广应用到函数拟合等其他机器学习问题中。支持向量机是一类按监督学习方式对数据进行二元分类的广义线性分类器,其目的就是通过对学习样本来求解最大间隔的超平面。给定训练样本集
![]()
分类学习最基本的想法就是基于训练集D在样本空间中找到一个划分超平面,将不同的类别分开。但是能将训练样本分开的划分超平面可能有很多,我们应该找哪个呢?
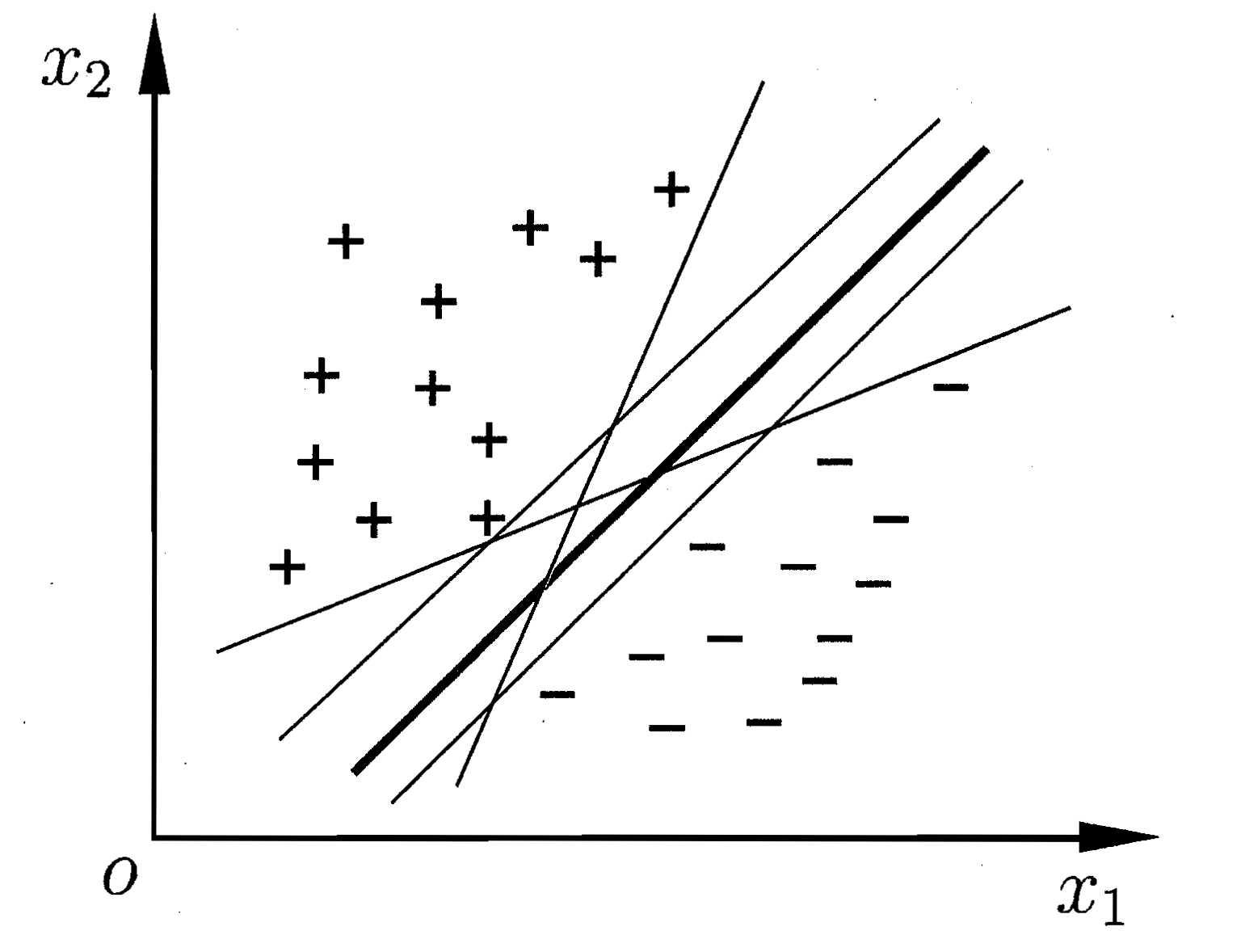 图1
图1
如图1,直观上看,应该去找位于两样本正中间的划分超平面,因为该划分超平面对训练样本局部扰动的“容忍”性最好。
在样本空间中,令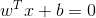 表示划分超平面,其中
表示划分超平面,其中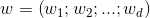 为法向量,决定了超平面的方向;b为位移项,决定了超平面与原点之间的距离。这样超平面就可被法向量w和位移项b确定,将其记为
为法向量,决定了超平面的方向;b为位移项,决定了超平面与原点之间的距离。这样超平面就可被法向量w和位移项b确定,将其记为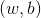 。样本空间中任一点x到超平面
。样本空间中任一点x到超平面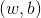 的距离可写为
的距离可写为
![]() 假设超平面
假设超平面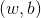 能将训练样本正确分类,即对于
能将训练样本正确分类,即对于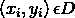 ,若
,若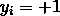 ,则有
,则有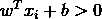 ;若
;若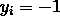 ,则有
,则有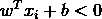 。令
。令
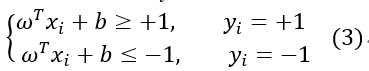
如图2所示,距离超平面最近的几个训练样本点使(3)式等号成立,它们被称为“支持向量”,两个异类支持向量到超平面的距离之和为![]() ,它被称为“间隔”。要找到具有“最大间隔”的划分超平面,也就是要找到满足(3)式中约束的参数w,b,使得
,它被称为“间隔”。要找到具有“最大间隔”的划分超平面,也就是要找到满足(3)式中约束的参数w,b,使得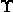 最大,即
最大,即 ![]() s.t.
s.t. 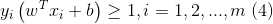 显然,为了最大化间隔,仅需最大化
显然,为了最大化间隔,仅需最大化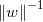 ,这等价于最小化
,这等价于最小化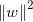 ,于是,上式可重写为
,于是,上式可重写为![]() s.t.
s.t. 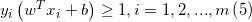 这就是支持向量机的基本型。可以通过求解(5)式来得到最大间隔划分超平面所对应的模型
这就是支持向量机的基本型。可以通过求解(5)式来得到最大间隔划分超平面所对应的模型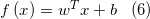 其中w,b是模型参数。
其中w,b是模型参数。
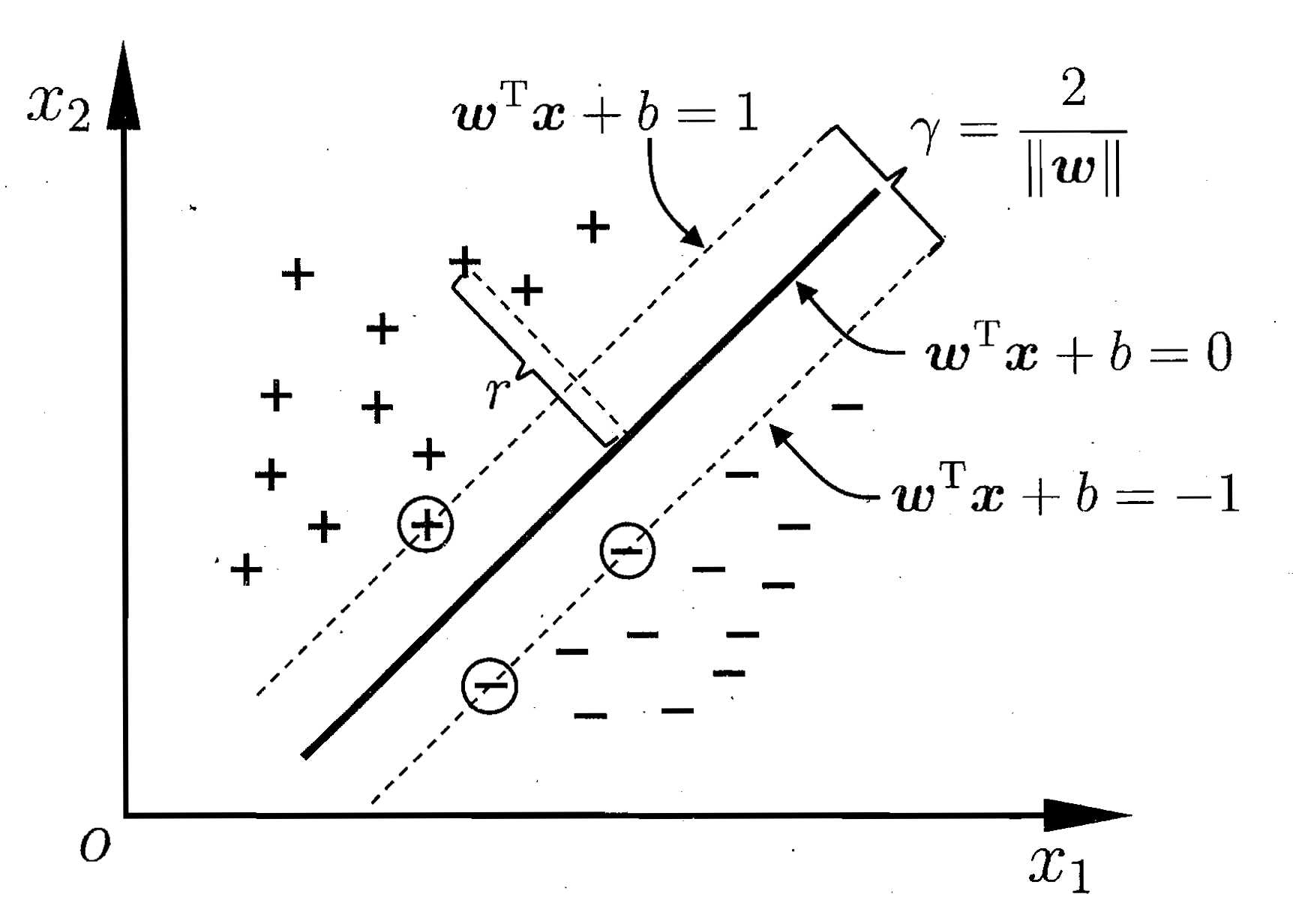 图2
图2
上面我们所讨论的都是假设训练样本是线性可分的,即存在一个划分超平面能将训练样本正确分类,然而现实中可能并不存在这样的超平面。如图3所示,对于这样的问题,可将原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分(如图4)。
 图3
图3
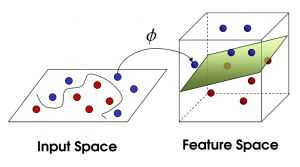 图4
图4
令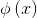 表示将x映射后的特征向量,于是,在特征空间中划分超平面所对应的模型可表示为
表示将x映射后的特征向量,于是,在特征空间中划分超平面所对应的模型可表示为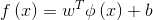 ,类似(5)式有
,类似(5)式有![]() s.t.
s.t. 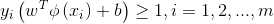 ,其对偶问题是
,其对偶问题是![]() (7)求解式(7)涉及到计算
(7)求解式(7)涉及到计算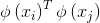 ,这是样本xi与xj映射到特征空间之后的内积。由于特征空间维数可能很高,甚至可能是无穷维,因此直接计算
,这是样本xi与xj映射到特征空间之后的内积。由于特征空间维数可能很高,甚至可能是无穷维,因此直接计算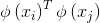 通常是困难的。为了避开这个障碍,可以设想这样一个函数:
通常是困难的。为了避开这个障碍,可以设想这样一个函数: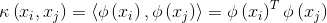 (8)即xi与xj在特征空间的内积等于它们在原始样本空间中通过函数
(8)即xi与xj在特征空间的内积等于它们在原始样本空间中通过函数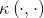 计算的结果。有了这样的函数,我们就不必直接去计算高维甚至无穷维特征空间中的内积,也就是说,在线性不可分的情况下,支持向量机首先在低维空间中完成计算,然后通过核函数将输入空间映射到高维特征空间,最终在高维特征空间中构造出最优分离超平面,从而把平面上本身不好分的非线性数据分开,于是(7)式可重写为
计算的结果。有了这样的函数,我们就不必直接去计算高维甚至无穷维特征空间中的内积,也就是说,在线性不可分的情况下,支持向量机首先在低维空间中完成计算,然后通过核函数将输入空间映射到高维特征空间,最终在高维特征空间中构造出最优分离超平面,从而把平面上本身不好分的非线性数据分开,于是(7)式可重写为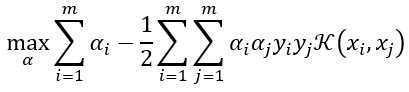
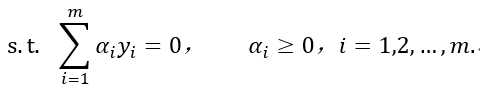 (9)求解后即可得到
(9)求解后即可得到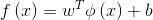
![]()
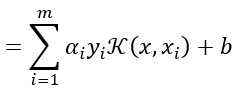 (10)这里的函数
(10)这里的函数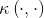 就是“核函数”。式(10)显示出模型最优解可通过训练样本的核函数展开,这一展式亦称“支持向量展式”。
就是“核函数”。式(10)显示出模型最优解可通过训练样本的核函数展开,这一展式亦称“支持向量展式”。
显然,若已知合适映射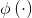 的具体形式,则可写出核函数
的具体形式,则可写出核函数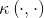 ,但在现实任务中我们通常不知道
,但在现实任务中我们通常不知道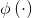 是什么形式,那么,合适的核函数是否一定存在的?什么样的函数能做核函数呢?我们有下面的定理:
是什么形式,那么,合适的核函数是否一定存在的?什么样的函数能做核函数呢?我们有下面的定理:


下表是几种常用的核函数。
表1 常用核函数

在上面的讨论中,我们一直假定训练样本在样本空间或特征空间中是线性可分的,即存在一个超平面能将不同类的样本完全划分开。 然而,在现实任务中往往很难确定合适的核函数使得训练样本在特征空间中线性可分;退一步说,即使恰好找到了某个核函数使训练集在特征空间中线性可分,也很难断定这个貌似线性可分的结果不是由于过拟合所造成的。
缓解该问题的一个办法是允许支持向量机在一些样本上出错。为此,就引入了“软间隔”的概念,如图5所示
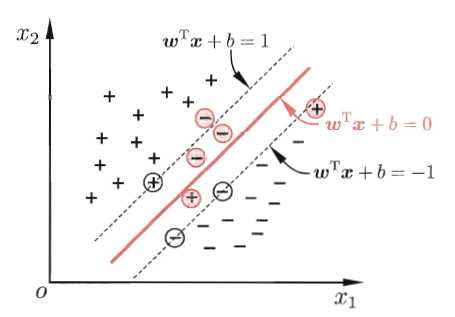
图5 软间隔示意图.红色圈出了一些不满足约束的样本.
具体来说,前面介绍的支持向量机形式是要求所有样本均满足约束(3),即所有样本都必须划分正确,这称为“硬间隔”,而软间隔则是允许某些样本不满足约束: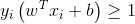 (11)当然,在最大间隔化的同时,不满足约束的样本应尽可能少。于是,优化目标写为:
(11)当然,在最大间隔化的同时,不满足约束的样本应尽可能少。于是,优化目标写为: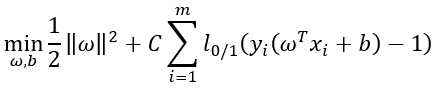 (12)其中C>0是一个常数,
(12)其中C>0是一个常数,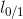 是“0/1损失函数”:
是“0/1损失函数”:![]() (13)显然,当C为无穷大时,式(12)迫使所有样本均满足约束(11),于是式(12)等价于(5);当C取有限值时,式(12)允许一些样本不满足约束。
(13)显然,当C为无穷大时,式(12)迫使所有样本均满足约束(11),于是式(12)等价于(5);当C取有限值时,式(12)允许一些样本不满足约束。
对偶问题
支持向量机有三宝:间隔、对偶、核技巧(核函数)。对于支持向量机我们想要找到一个划分超平面将样本正确分类,那么要找到具有最大间隔的划分超平面,就是要找到满足(3)式中约束的w,b使得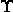 最大,即
最大,即![]() s.t.
s.t. 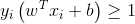 i = 1,2,...,m,为了后面计算的方便,我们将它等价地写为
i = 1,2,...,m,为了后面计算的方便,我们将它等价地写为![]() s.t.
s.t. 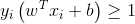 i = 1,2,..,m,这是原始带约束的问题,求解这个式子计算比较复杂,所以我们用它的对偶问题来解决,具体来说就是对上式的每条约束添加拉格朗日乘子
i = 1,2,..,m,这是原始带约束的问题,求解这个式子计算比较复杂,所以我们用它的对偶问题来解决,具体来说就是对上式的每条约束添加拉格朗日乘子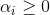 ,则该问题的拉格朗日函数可写为:
,则该问题的拉格朗日函数可写为: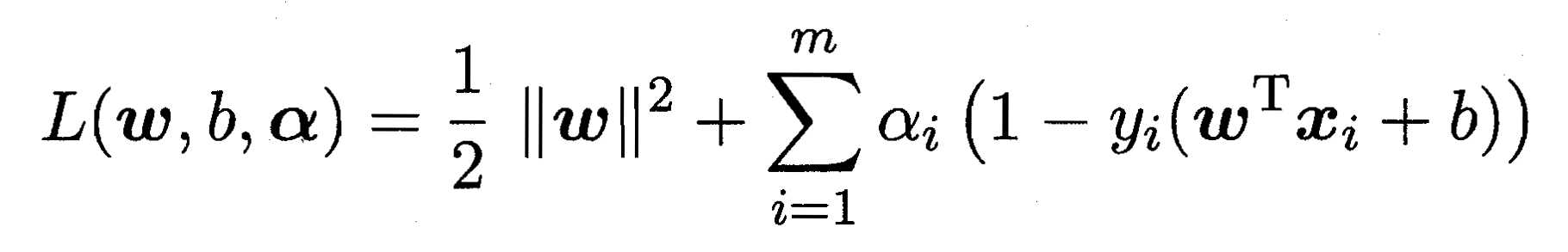 ,这样引入拉格朗日乘子的无约束问题为:
,这样引入拉格朗日乘子的无约束问题为:![]() ,它的对偶问题为:
,它的对偶问题为:![]() ,我们分别对w和b求偏导,
,我们分别对w和b求偏导,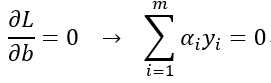 ,代入得:
,代入得:
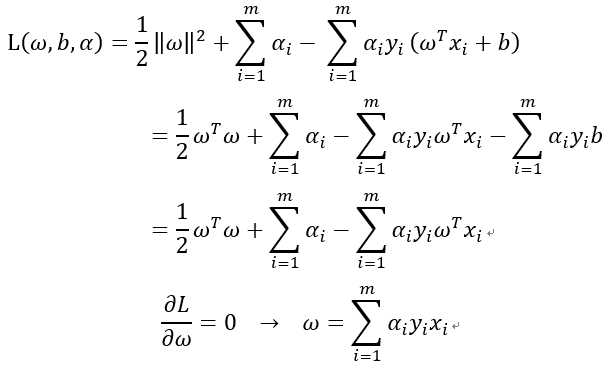
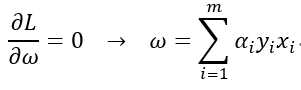 ,代入得:
,代入得:
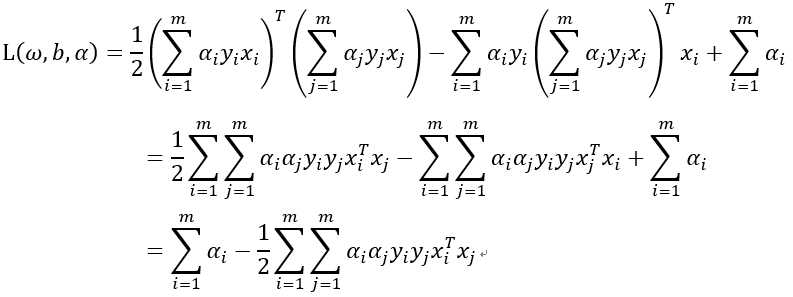
因此最后得对偶问题为: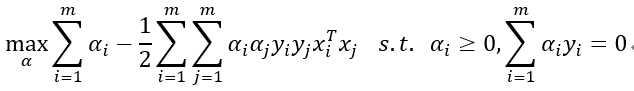 ,我们求出
,我们求出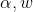 和b后可得到模型:
和b后可得到模型: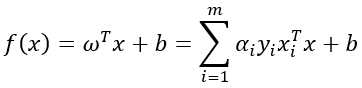 ,这里面有一个KKT条件,上述对偶问题需要满足此条件才可以互相转化:
,这里面有一个KKT条件,上述对偶问题需要满足此条件才可以互相转化: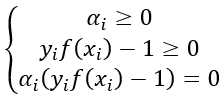 ,于是,对任意训练样本
,于是,对任意训练样本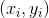 ,总有
,总有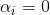 或
或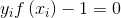 。若
。若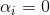 ,则该样本将不会在模型(上式)的求和中出现,也就不会对
,则该样本将不会在模型(上式)的求和中出现,也就不会对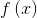 有任何影响;若
有任何影响;若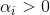 ,则必有
,则必有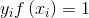 ,所对应的样本点位于最大间隔边界上,是一个支持向量。这显示出支持向量机的一个重要性质:训练完成后,大部分的训练样本都不需要保留,最终模型仅与支持向量有关。
,所对应的样本点位于最大间隔边界上,是一个支持向量。这显示出支持向量机的一个重要性质:训练完成后,大部分的训练样本都不需要保留,最终模型仅与支持向量有关。
SVM应用案例
表2是R软件中支持向量机建模所用的软件包及数据集。
表2

下图是用SVM进行分类的过程
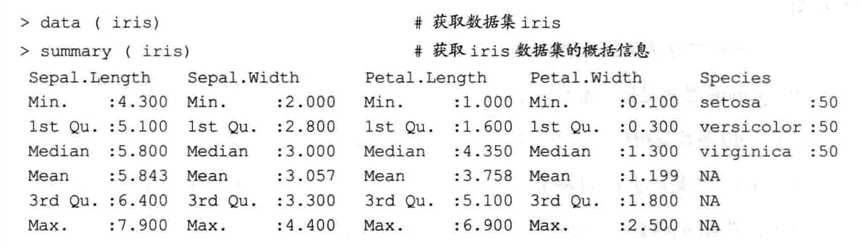







获取R软件中自带iris数据后,我们能够看到它共包含150个样本以及4个样本特征,结果标签共有三个类别均有50个样本。
然后进行建模,X为特征变量,Y为结果变量建立SVM模型,然后是结果分析,分为三类。最后是预测,从150个样本中随机挑选8个预测结果进行展示,然后查看预测精度,发现模型将所有属于setosa类型的花全部预测正确;将属于versicolor类型的花中的48朵预测正确,但将另外两朵预测为virginica类型;同理,模型将属于 virdinica类型的花中的48朵预测正确,但也将另外两朵预测为versicolor类型。之后我们可以调整权重来优化建模。
以上是关于Machine Learning—支持向量机(SVM)的主要内容,如果未能解决你的问题,请参考以下文章