Open Images V4 下载自己需要的类别
Posted tay007
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Open Images V4 下载自己需要的类别相关的知识,希望对你有一定的参考价值。
OpenImage V4数据集描述
1)这个v4数据集主要有两种用途:
对象检测及分类,意思是说可以用这个数据集训练出对象检测模型,用于识别图像中的对象类别及位置边框。
视觉关系检测,比如你用这个v4数据集训练好一个模型,然后给模型一张图,模型会告诉你“女人在弹吉它”。
2)根据上面说的两个用途,google已经贴心的为你把这个数据集分成两份(共9,011,219张图,这两种数据集的图片不是互斥的,它们有相同的图片),每份又分成了训练集,验证集,测试集。
3)所有作用于对象检测及分类的图片主要特性是有边界框,一张图中可能有多个边界框
我们试着从官网的Boxes这一行下载一个下来,是个csv文件,我们暂称它为边界框表
其中各个字段如下所
ImageID:边界框id,可以理解成一个外键,具体的描述在另一个文件里。
Source:表示边界框是如何制作的:
freeform并且xclick是手动绘制的边界框。
activemil是使用该方法的增强版生成的边界框。在IoU> 0.7时,这些经过人为验证是准确的。
LabelName:此框属于的对象类的MID。
Confidence:虚拟值,始终为1。
XMin,XMax,YMin,YMax:框的坐标,在标准化图像坐标。XMin在[0,1]中,其中0是最左边的像素,1是图像中最右边的像素。Y坐标从顶部像素(0)到底部像素(1)。
这些属性具有以下定义:
IsOccluded:表示该对象被图像中的另一个对象遮挡。
IsTruncated:表示对象超出图像的边界。
IsGroupOf:表示边界框跨越一组对象(例如,花坛或一群人)。我们要求注释者使用这个标签来处理5个以上的实例,这些实例会严重遮挡对方,并且会触及身体。
IsDepiction:指示对象是描述(例如,对象的卡通或图画,而不是真实的物理实例)。
IsInside:表示从对象内部拍摄的照片(例如,汽车内部或建筑物内部)
从Image labels行下载一个文件后,可以看到是标签类别,一幅图上有几个对象,就给你打几个标签,我们暂称它为分类标签表,可做图像分类用。
Source:表示注释的创建方式:verification 是由Google内部注释人员验证的标签。crowdsource-verification是由Crowdsource应用程序验证的标签。machine是机器生成的标签。
Confidence:经人工验证出现在图像中的标签的置信度= 1(正标签)。经过人工验证的图像中缺失的标签的置信度= 0(负标签)。机器生成的标签具有部分置信度,通常> = 0.5。信心越高,标签成为假阳性的机会就越小。
从Image IDs行下载文件后,可以看到是图像的相关信息,它包含图片网址,OpenImages ID,轮换信息,标题,作者和许可证信息,我们暂称它为图片表,可以看得出来,几乎所有的图像都来自flickr网站。每个图像都有一个唯一的64位ID分配。在CSV文件中,它们显示为零填充的十六进制整数,例如000060e3121c7305。
数据与目标网站上显示的数据相同。OriginalSize 是原始图像的下载大小。OriginalMD5是base64编码二进制MD5,如所描述这里。Thumbnail300KURL是约300K像素(?640x480)的缩略图的可选网址。它提供了为了方便下载数据而没有更方便的方式来获取图像。如果丢失,OriginalURL必须使用(如果需要,然后调整大小相同的大小)。这些缩略图会随时生成,其内容甚至解析度可能每天都会有所不同。Rotation是,图像应逆时针转动,以匹配Flickr用户预期的方向(多少度0,90,180,270)。nan意味着这些信不可用。查看此公告以获取有关此问题的更多信息。我们可以按照这个地址,自已一个一个去下,或者去第一行那边下完整的包都是可以的。
第五行Metadata是元数据,就是分类实际名称,我们暂称它为标签表。
可以将MID格式的类名转换为简短描述,
请注意逗号和引号等字符的存在。该文件遵循标准的CSV转义规则。
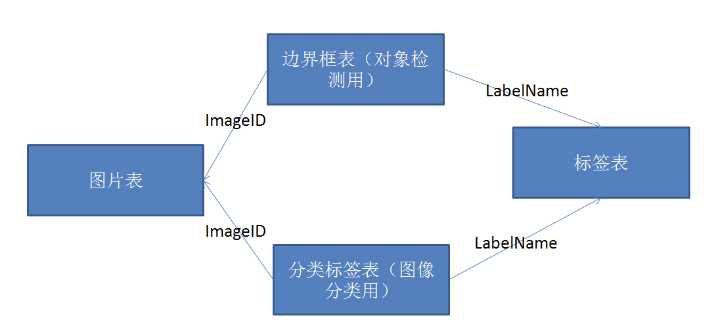
可以分析得出,它们形成了一个数据库表关系,是简单的外键关系,图片表描述图片信息,最重要是下载地址,边界框表主要描述一张图有几个边框,它与图片表通过外键ImageID关联,同时每个边框具体属于哪个分类,又要通过LabelName外键和标签表关联。
参考资源:https://blog.csdn.net/wulala789/article/details/80646618
但是到官网下载的时候要一次性下载所有的部分,不仅文件很大,而且下载的也不大快,更重要的是自己训练要用到的类别并不多。正当我手足无措时,刚好就在github上看到了相关的issues(https://github.com/cvdfoundation/open-images-dataset/issues/8)。
我采用的是里面介绍到的工具箱的方法(https://github.com/EscVM/OIDv4_ToolKit),实际操作起来也挺顺利的。
接下来是使用工具箱的一些笔记,在Readme里面我们能通过
python main.py -h
看到工具箱的一些官方帮助介绍(我谷歌翻译的):
用法:main.py [-h] [--Dataset/path/to/OID/csv/] [-y] [ - 类列表[类列表...]] [--type_csv‘train‘或‘validation‘或‘test‘或‘all‘] [--sub 子人验证图像的子集或机器生成的h或m)] [--image_IsOccluded 1或0] [ - image_IsTruncated 1或0] [--image_IsGroupOf 1或0] [ - image_IsDepiction 1或0] [--image_IsInside 1或0] [--multiclasses 0(默认值或1) [--n_threads [默认20]] [--noLabels] [--limit integer number] <command>‘downloader‘,‘visualizer‘或‘ill_downloader‘。 Open Image Dataset Downloader
打开图像数据集下载程序 位置参数: <command>‘downloader‘,‘visualizer‘或‘ill_downloader‘。 ‘downloader‘,‘visualizer‘或‘ill_downloader‘。 可选参数: -h, --help 显示此帮助消息并退出 --Dataset /path/to/OID/csv/ OID数据集文件夹的目录 -y, --yes 是和是可以下载丢失的文件 - 类列表[类列表...] 所需类的“字符串”序列 --type_csv‘train‘或‘validation‘或‘test‘或‘all‘ 从什么csv搜索图像 --sub 人工验证图像或机器生成的子集(h或m) 从人类验证的数据集或从 机器生成一个。 --image_IsOccluded 1或0 图像的可选特征。表示 对象被图像中的另一个对象遮挡。 --image_IsTruncated 1或0 图像的可选特征。表示 对象超出图像的边界。 --image_IsGroupOf 1或0 图像的可选特征。表示 盒子跨越一组物体(分钟5)。 --image_IsDepiction 1或0 图像的可选特征。表示 对象是一个描述。 --image_IsInside 1或0 图像的可选特征。表示a 从对象内部拍摄的照片。 --multiclasses 0(默认值)或1 分别(0)或一起下载不同的类 (1) --n_threads [默认20] 要使用的线程数 --noLabels 没有标签创作 --limit integer number 要下载的图像数量的可选限制
以上是关于Open Images V4 下载自己需要的类别的主要内容,如果未能解决你的问题,请参考以下文章