scrapy xpath / css
Posted phper8
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了scrapy xpath / css相关的知识,希望对你有一定的参考价值。
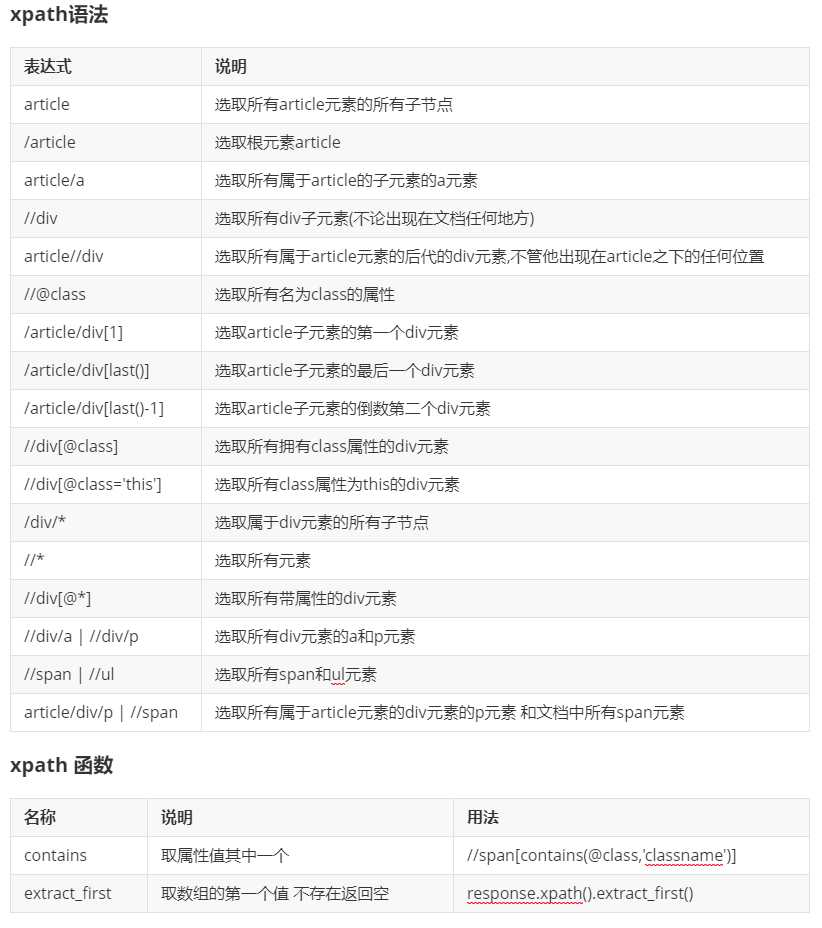
title = response.xpath(‘//h2[@class="margin-top-0"]/a/text()‘) read_num = response.xpath(‘//div[@class="col-md-12"]/p[@class="text-muted"]/small/text()‘).extract()[3].strip().replace(‘阅读(‘, ‘‘).replace(‘)‘, ‘‘) commen_num = response.xpath(‘//div[@class="col-md-12"]/p[@class="text-muted"]/small/text()‘).extract()[4].strip().replace(‘评论(‘, ‘‘).replace(‘)‘, ‘‘) add_time = response.xpath(‘//div[@class="col-md-12"]/p[@class="text-muted"]/small/text()‘).extract()[5].strip() content = response.xpath(‘//div[@class="content"]//*‘).extract()[0] tag_list = response.xpath(‘//a[@class="text-muted"]/text()‘).extract() tag_str = ‘$$‘.join(tag_list)
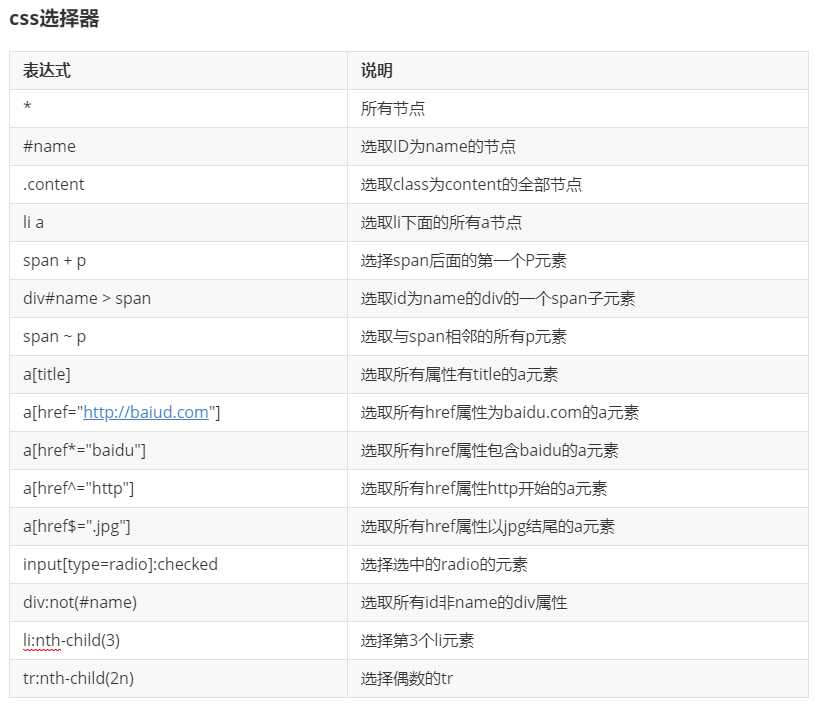
title = response.css(".margin-top-0 a::text").get() read_num = response.css("p.text-muted small::text").getall()[3].strip().replace(‘阅读(‘, ‘‘).replace(‘)‘, ‘‘) commen_num = response.css("p.text-muted small::text").getall()[4].strip().replace(‘评论(‘, ‘‘).replace(‘)‘, ‘‘) add_time = response.css("p.text-muted small::text").getall()[5].strip() content = response.css(".content *").getall() tag_list = response.css("a.text-muted::text").getall() tag_str = ‘$$‘.join(tag_list)
以上是关于scrapy xpath / css的主要内容,如果未能解决你的问题,请参考以下文章