tensorflow框架学习—— 一个简单的神经网络示例
Posted dwithy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了tensorflow框架学习—— 一个简单的神经网络示例相关的知识,希望对你有一定的参考价值。
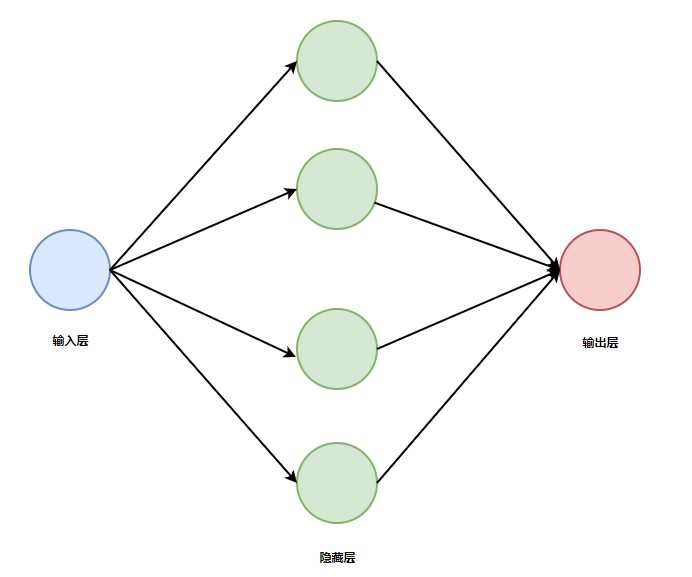
一、神经网络结构
定义一个简单的回归神经网络结构:
- 数据集为(xi,yi),数据的特征数为1,所以x的维度为1。
- 输入层1个神经元。
- 隐藏层数为1,4个神经元。
- 输出层1个神经元。
- 隐藏层的激活函数为f(x)=x,输出层的激活函数为ReLU
结构图如下:
二、代码示例
相关函数说明:
- tf.random_normal :用于生成正太分布随机数矩阵的tensor,tensorFlow有很多随机数函数,可以查找官方文档获得。
- tf.zeros :用于生成0矩阵的tensor,tf.ones可以用来获得单位矩阵。
- tf.nn.relu :tensorflow定义的用来实现ReLU激活函数的方法。
- tf.reduce_sum :求和函数,通过axis来控制在哪个方向上求和,axis=[0]表示按行求和,axis=[1]表示按列求和。
- tf.train.GradientDescentOptimizer(learning_rate).minimize(loss) :梯度下降优化函数,learning_rate表示学习率,minimize表示最小化,loss是优化的损失函数。tensorFlow有很多优化函数,可以查找官方文档获得。
代码:
import tensorflow as tf import numpy as np # 创建数据训练数据集, x_data = np.random.rand(1000).reshape(1000, 1) noise = np.random.normal(0, 0.1, [1000, 1]) # 制作噪音 y_data = 2 * x_data + 1 + noise # 创建占位符用于minibatch的梯度下降训练,建议数据类型使用tf.float32、tf.float64等浮点型数据 x_in = tf.placeholder(tf.float32, [None, 1]) y_in = tf.placeholder(tf.float32, [None, 1]) # 定义一个添加层的函数 def add_layer(input_, in_size, out_size, activation_funtion=None): ‘‘‘ :param input_: 输入的tensor :param in_size: 输入的维度,即上一层的神经元个数 :param out_size: 输出的维度,即当前层的神经元个数即当前层的 :param activation_funtion: 激活函数 :return: 返回一个tensor ‘‘‘ weight = tf.Variable(tf.random_normal([in_size, out_size])) # 权重,随机的in_size*out_size大小的权重矩阵 biase = tf.Variable(tf.zeros([1, out_size]) + 0.01) # 偏置,1*out_size大小的0.01矩阵,不用0矩阵避免计算出错 if not activation_funtion: # 根据是否有激活函数决定输出 output = tf.matmul(input_, weight) + biase else: output = activation_funtion(tf.matmul(input_, weight) + biase) return output # 定义隐藏层,输入为原始数据,特征为1,所以输入为1个神经元,输出为4个神经元 layer1 = add_layer(x_in, 1, 4) # 定义输出层,输入为layer1返回的tensor,输入为4个神经元,输出为1个神经元,激活函数为ReLU predict = add_layer(layer1, 4, 1, tf.nn.relu) # 定义损失函数 loss = tf.reduce_mean(tf.reduce_sum(tf.square(y_in - predict), axis=[1])) # tf.reduce_sum的axis=[1]表示按列求和 # 定义训练的优化方式为梯度下降 train = tf.train.GradientDescentOptimizer(0.1).minimize(loss) # 学习率为0.1 init = tf.global_variables_initializer() with tf.Session() as sess: sess.run(init) # 训练1000次 for step in range(1000): # 执行训练,因为有占位符所以要传入字典,占位符的好处是可以用来做minibatch训练,这里数据量小,直接传入全部数据来训练 sess.run(train, feed_dict=x_in: x_data, y_in: y_data) # 每50步输出一次loss if step % 49 == 0: print(sess.run(loss, feed_dict=x_in: x_data, y_in: y_data))
以上是关于tensorflow框架学习—— 一个简单的神经网络示例的主要内容,如果未能解决你的问题,请参考以下文章