InnoDB存储引擎的高级特性大盘点
Posted jackion5
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了InnoDB存储引擎的高级特性大盘点相关的知识,希望对你有一定的参考价值。
InnoDB作为mysql数据库最常用的存储引擎,自然包含了其独有的很多特性。如相比于memory、MyISAM引擎,InnoDB支持行级锁、事务等都是比较重要的特性。
本文将盘点下InnoDB处理事务和行级锁之外的高级特性
一、自适应哈希
innodb建立索引时,只可以建立B+tree索引,是不可以建立hash索引的,而hash索引相对于B+tree索引,虽然无法实现排序、范围检索的效果,但是在等值检索的时候,毫无疑问要比B+tree索引的效率要高很多。
所以innodb就在B+tree索引的基础之上,又添加了自适应hash索引,只不过这个索引无法通过手动创建,是通过innodb存储引擎在运行时自己创建的,对于用户来说是透明的。
Innodb 会监控堆表上二级索引的查找,如果发现某个二级索引频繁访问,那么就认为这个二级索引是热点数据,就会针对这个二级索引建立hash索引,下一次再检索时就可以直接通过hash索引检索。
innodb认为最近连续三次被访问的二级索引是热点数据,就会自动创建hash索引
hash索引的优缺点都很明显:
优点是:等值查询的时候检索效率要比B+tree检索效率高很多;不需要人为维护,innodb自行维护
缺点是:会占用一部分innodb的缓冲池;只适合等值查询,不支持范围查询;极端情况下才有效,如果不是连续读相同索引就无效
二、插入缓存(insert buffer)
插入缓存是针对于非聚簇索引而言的,因为聚簇索引一般都是有顺序的,所以在执行批量插入时,第一条语句插入完成之后,后面的数据所在的页基本上都和第一条的数据在同一页,或者是相邻的页,根据数据库预读的特性。
所以进行批量插入的时候只需要加载1次页就可以完成多条数据的插入操作。但是对于非聚簇索引索引基本上都是无序的,离散的。所以每次插入的时候就需要离散地访问非聚簇索引页,显然就降低了插入的性能。
所以Innodb为了解决这个问题就新增了插入缓存功能,对于非聚簇索引的插入或更新,不是直接更新到索引页,而是先判断更新的非聚簇索引是否存在缓冲池中,如果在就直接插入缓冲池;如果不存在就先放入缓冲池中。
然后再以一定的频率将缓冲池中的缓存和非聚簇索引页的数据进行合并操作。由于在一个索引页,所以通常可以将多个插入操作合并成一个操作,减少了非聚簇索引页的IO操作。
插入缓存的条件:
1、索引必须是非聚簇索引(聚簇索引是有序的,不需要缓存)
2、索引不是唯一的 (唯一的情况就失去了意义,只能达到延迟的效果,并不能减少IO次数)
插入缓存的缺点就是需要占用一部分缓冲池的空间,可以通过配置IBUF_POOL_SIZE_PRE_MAX_SIZE 进行配置,如值为3,则最大只能使用1/3的缓冲池空间
三、二次写 (double write)
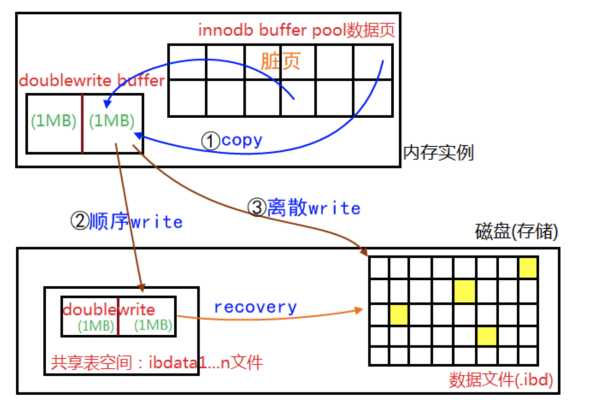
double write 主要是为了提升innodb的可靠性,确保数据不会丢失。
主要分成两个部分组成:一部分是内存中的double write buffer,大小为2M;一部分是磁盘上共享表空间(ibdata)中连续的2个区,也就是128页,大小也是2M
1、当触发数据缓冲池中的脏页刷新时,并不是直接写入磁盘文件,而是先拷贝到double write buffer中
2、接着从double write buffer中分两次写入磁盘共享表空间中(连续存储、顺序写效率高)每次写1M
3、当第二步完成之后,再将double write buffer中的脏页数据写入实际的各个表空间文件(离散写);脏页数据持久化完成之后就可以标记double write区的数据可以被覆盖了。
为什么需要double write:
1、关于IO的最小单位,order是8K,mysql是一页也就是16K;文件系统的IO的最小单位是4K,也有的是1K;磁盘IO的最小单位是512字节
2、当需要将脏页16K的数据写入到磁盘文件时,假设每次是4k,那么就需要进行四次物理写的操作才能刷盘完成。
3、如果在执行了2次物理写之后,系统出现故障,就会导致磁盘中已经被写入了一个不完整的数据页(数据页被破坏)
4、系统恢复时,redo log只能加上旧、校验完整的数据页恢复一个脏块,不能修复坏掉的数据页,从而会造成数据不一致问题(redo log记录的是对页的物理修改)
double write的崩溃恢复
如果操作系统将页写入磁盘的过程中宕机,恢复的时候可以从共享表空间的double write文件中找到该页的最近的副本,将其复制到表空间文件,再通过redo log 就可以完成恢复操作。
那么为什么log的写不需要通过double write呢?因为log的写入的单位是512个字节,所以就不会存在数据损坏的问题。
那么为什么不直接从double write 写入 data page呢?
因为double write也是文件,而data page又是离散的,从double write中读取数据写入data page 显然没有从缓存中直接写入data page要快;
四、缓冲池(innodb buffer pool)
innodb在内存中维护了多个缓冲池, 用来缓存近期访问的数据和索引。缓冲池的主要配置如下:
innodb_buffer_pool_size:缓冲池大小,建议设置成系统总内存的70%~80%
innodb_buffer_pool_instance:缓冲池的个数,建议设置成CPU核数
innodb_flush_log_at_trx_commit:缓冲池中的数据如何刷盘,设置为1,数据不丢失;设置为2,最多丢失1秒钟,但是性能较高(mysql服务挂了不丢失数据,机器宕机才会丢失数据)
缓冲池的内存管理:
缓冲池内部通过List管理数据,采用LRU算法(最近不被访问)淘汰数据,当缓冲池慢了,会删除掉最近没有被访问的数据;而插入缓冲池的时候,也不算插入List的头部或尾部,而是插入list的中间
因为头部是热点数据、尾部是即将淘汰的数据,采用保险策略将新的数据插入中间比较合理。List中存储的以页为单位的,所以插入和删除都是以 页 为单位的。
LRU算法将整个List的5/8作为new list;剩下的3/8作为old list;old list就是潜在的会被淘汰的数据;如果old list中的数据被访问到了,就会插入到new list到头部
innodb的所以操作几乎都是在缓冲池中实现,将磁盘中的数据加载到缓冲池中,然后再进行下一步操作,更新的时候也是直接更新缓冲池中的数据,然后再按一定频率刷新到磁盘。
缓冲池还有一个功能就是预读功能,预读功能是当innodb执行了一次IO操作加载了一页或多页之后,会预计下一次需要加载到页面数据,而提前将数据加载到缓冲池,就可以避免下一次再进行IO操作
预读操作分两种预读算法:线性预读 和 随机预读
线性预读:则会按page的顺序进行预读,预读page的个数可以通过配置设置
随机预读:当某一块(extent)中的某一页或某几页被加载了之后,会将这个extent中的所有page都加载到缓冲池
以上是关于InnoDB存储引擎的高级特性大盘点的主要内容,如果未能解决你的问题,请参考以下文章