SRGAN 学习心得
Posted zgqcn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SRGAN 学习心得相关的知识,希望对你有一定的参考价值。
一、理论
关于SRGAN的的论文中文翻译网上一大堆,可以直接读网络模型(大概了解),关于loss的理解,然后就能跑代码
loss = mse + 对抗损失 + 感知损失 : https://blog.csdn.net/DuinoDu/article/details/78819344
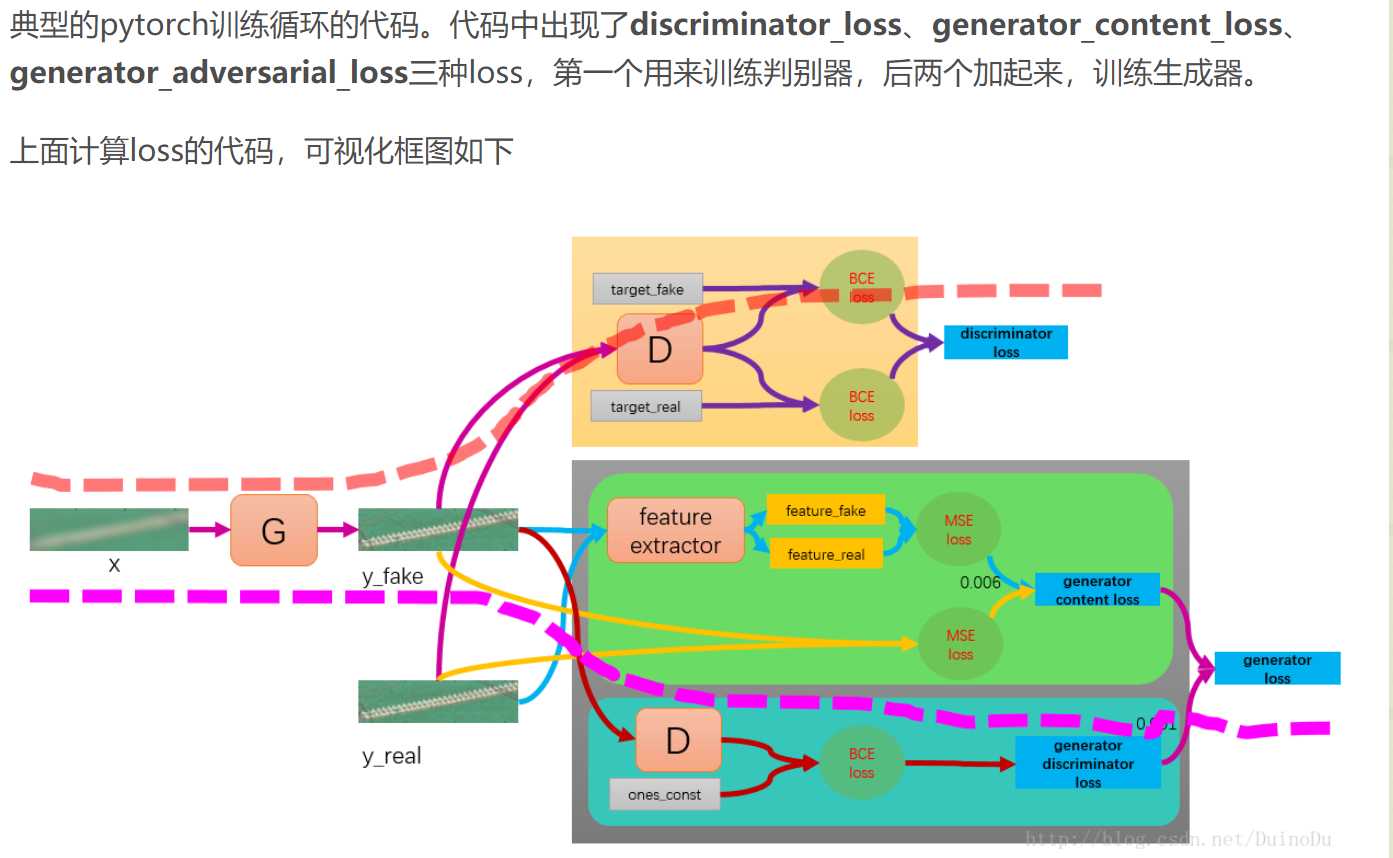
二、代码及其理解
(1)文件结构
(2)train.py


import argparse import os from math import log10 import pandas as pd import torch.optim as optim import torch.utils.data import torchvision.utils as utils from torch.autograd import Variable from torch.utils.data import DataLoader from tqdm import tqdm import pytorch_ssim from data_utils import TrainDatasetFromFolder, ValDatasetFromFolder, display_transform from loss import GeneratorLoss from model import Generator, Discriminator parser = argparse.ArgumentParser(description=‘Train Super Resolution Models‘) parser.add_argument(‘--crop_size‘, default=88, type=int, help=‘training images crop size‘) parser.add_argument(‘--upscale_factor‘, default=4, type=int, choices=[2, 4, 8], help=‘super resolution upscale factor‘) parser.add_argument(‘--num_epochs‘, default=100, type=int, help=‘train epoch number‘) opt = parser.parse_args() CROP_SIZE = opt.crop_size UPSCALE_FACTOR = opt.upscale_factor NUM_EPOCHS = opt.num_epochs if __name__ == ‘__main__‘: # 加载数据集 train_set = TrainDatasetFromFolder(‘/content/drive/My Drive/app/RBB/train‘, crop_size=CROP_SIZE, upscale_factor=UPSCALE_FACTOR) val_set = ValDatasetFromFolder(‘/content/drive/My Drive/app/RBB/test‘, upscale_factor=UPSCALE_FACTOR) train_loader = DataLoader(dataset=train_set, num_workers=4, batch_size=64, shuffle=True) val_loader = DataLoader(dataset=val_set, num_workers=4, batch_size=1, shuffle=False) # 加载网络模型 netG = Generator(UPSCALE_FACTOR) print(‘# generator parameters:‘, sum(param.numel() for param in netG.parameters())) netD = Discriminator() print(‘# discriminator parameters:‘, sum(param.numel() for param in netD.parameters())) # 加载loss函数 generator_criterion = GeneratorLoss() # 判断GPU加速 if torch.cuda.is_available(): netG.cuda() netD.cuda() generator_criterion.cuda() # 定义Adam优化器 optimizerG = optim.Adam(netG.parameters()) optimizerD = optim.Adam(netD.parameters()) # 定义结果保存的字典,值为列表 results = ‘d_loss‘: [], ‘g_loss‘: [], ‘d_score‘: [], ‘g_score‘: [], ‘psnr‘: [], ‘ssim‘: [] for epoch in range(1, NUM_EPOCHS + 1): train_bar = tqdm(train_loader) # 生成进度条>>>>>>>> # 定义字典统计相关超参数 running_results = ‘batch_sizes‘: 0, ‘d_loss‘: 0, ‘g_loss‘: 0, ‘d_score‘: 0, ‘g_score‘: 0 netG.train() netD.train() for data, target in train_bar: g_update_first = True batch_size = data.size(0) running_results[‘batch_sizes‘] += batch_size ############################ # data/z:由target下采样的低分辨率图像 --> G --> fake_img --> D --> fake_out(label) # target/real_img:高分辨率图像(原图) --> D --> real_out(label) ############################ # (1) 更新判别网络: maximize -1+D(z)-D(G(z)) # 判别网络的输出是数值,即是一个概率 ########################### real_img = Variable(target) # torch数据类型的标签图像real_img if torch.cuda.is_available(): real_img = real_img.cuda() z = Variable(data) # torch数据类型的输入图像z if torch.cuda.is_available(): z = z.cuda() fake_img = netG(z) # 生成网络的的输出图像fake_img netD.zero_grad() # 判别网络的梯度归零 real_out = netD(real_img).mean() # 判别网络对于标签图像的输出的均值real_out fake_out = netD(fake_img).mean() # 判别网络对于fake_img的输出的均值fake_out d_loss = 1 - real_out + fake_out # d_loss = - [D(z)-1-D(G(z))],所以最小化d_loss,则后一项的最大化 d_loss.backward(retain_graph=True) # 反向传播 optimizerD.step() # 梯度优化 ############################ # (2) 更新生成网络: minimize 1-D(G(z)) + Perception Loss + Image Loss + TV Loss ########################### netG.zero_grad() # 生成网络梯度归零 g_loss = generator_criterion(fake_out, fake_img, real_img) # loss g_loss.backward() # 反向传播 optimizerG.step() # 梯度优化 fake_img = netG(z) # 生成网络的的输出图像fake_img fake_out = netD(fake_img).mean() # 判别网络对于fake_img的输出的均值fake_out g_loss = generator_criterion(fake_out, fake_img, real_img) # 生成网络loss计算 running_results[‘g_loss‘] += g_loss.item() * batch_size d_loss = 1 - real_out + fake_out # 判别网络loss计算 running_results[‘d_loss‘] += d_loss.item() * batch_size running_results[‘d_score‘] += real_out.item() * batch_size running_results[‘g_score‘] += fake_out.item() * batch_size train_bar.set_description(desc=‘[%d/%d] Loss_D: %.4f Loss_G: %.4f D(x): %.4f D(G(z)): %.4f‘ % ( epoch, NUM_EPOCHS, running_results[‘d_loss‘] / running_results[‘batch_sizes‘], running_results[‘g_loss‘] / running_results[‘batch_sizes‘], running_results[‘d_score‘] / running_results[‘batch_sizes‘], running_results[‘g_score‘] / running_results[‘batch_sizes‘])) # 模型评估 netG.eval() out_path = ‘training_results/SRF_‘ + str(UPSCALE_FACTOR) + ‘/‘ if not os.path.exists(out_path): # 路径不存在则建立 os.makedirs(out_path) val_bar = tqdm(val_loader) # 加载验证集 valing_results = ‘mse‘: 0, ‘ssims‘: 0, ‘psnr‘: 0, ‘ssim‘: 0, ‘batch_sizes‘: 0 val_images = [] for val_lr, val_hr_restore, val_hr in val_bar: batch_size = val_lr.size(0) valing_results[‘batch_sizes‘] += batch_size with torch.no_grad(): lr = Variable(val_lr) hr = Variable(val_hr) if torch.cuda.is_available(): lr = lr.cuda() hr = hr.cuda() sr = netG(lr) batch_mse = ((sr - hr) ** 2).data.mean() valing_results[‘mse‘] += batch_mse * batch_size batch_ssim = pytorch_ssim.ssim(sr, hr).item() valing_results[‘ssims‘] += batch_ssim * batch_size valing_results[‘psnr‘] = 10 * log10(1 / (valing_results[‘mse‘] / valing_results[‘batch_sizes‘])) valing_results[‘ssim‘] = valing_results[‘ssims‘] / valing_results[‘batch_sizes‘] val_bar.set_description( desc=‘[converting LR images to SR images] PSNR: %.4f dB SSIM: %.4f‘ % ( valing_results[‘psnr‘], valing_results[‘ssim‘])) # save model parameters torch.save(netG.state_dict(), ‘/content/drive/My Drive/app/SRGAN_master/epochs_RBB/RBB_netG_epoch_%d_%d.pth‘ % (UPSCALE_FACTOR, epoch)) # torch.save(netD.state_dict(), ‘/content/drive/My Drive/app/SRGAN_master/epochs/RBB_netD_epoch_%d_%d.pth‘ % (UPSCALE_FACTOR, epoch)) # save loss\\scores\\psnr\\ssim results[‘d_loss‘].append(running_results[‘d_loss‘] / running_results[‘batch_sizes‘]) results[‘g_loss‘].append(running_results[‘g_loss‘] / running_results[‘batch_sizes‘]) results[‘d_score‘].append(running_results[‘d_score‘] / running_results[‘batch_sizes‘]) results[‘g_score‘].append(running_results[‘g_score‘] / running_results[‘batch_sizes‘]) results[‘psnr‘].append(valing_results[‘psnr‘]) results[‘ssim‘].append(valing_results[‘ssim‘]) if epoch % 10 == 0 and epoch != 0: out_path = ‘/content/drive/My Drive/app/SRGAN_master/statistics/‘ data_frame = pd.DataFrame( data=‘Loss_D‘: results[‘d_loss‘], ‘Loss_G‘: results[‘g_loss‘], ‘Score_D‘: results[‘d_score‘], ‘Score_G‘: results[‘g_score‘], ‘PSNR‘: results[‘psnr‘], ‘SSIM‘: results[‘ssim‘], index=range(1, epoch + 1)) data_frame.to_csv(out_path + ‘srf_‘ + str(UPSCALE_FACTOR) + ‘_train_results.csv‘, index_label=‘Epoch‘)
(3)data_utils.py
from os import listdir from os.path import join from PIL import Image from torch.utils.data.dataset import Dataset from torchvision.transforms import Compose, RandomCrop, ToTensor, ToPILImage, CenterCrop, Resize def is_image_file(filename): return any(filename.endswith(extension) for extension in [‘.png‘, ‘.jpg‘, ‘.jpeg‘, ‘.PNG‘, ‘.JPG‘, ‘.JPEG‘, ‘.tif‘]) def calculate_valid_crop_size(crop_size, upscale_factor): return crop_size - (crop_size % upscale_factor) def train_hr_transform(crop_size): return Compose([ RandomCrop(crop_size), ToTensor(), ]) def train_lr_transform(crop_size, upscale_factor): return Compose([ ToPILImage(), Resize(crop_size // upscale_factor, interpolation=Image.BICUBIC), ToTensor() ]) def display_transform(): return Compose([ ToPILImage(), Resize(400), CenterCrop(400), ToTensor() ]) class TrainDatasetFromFolder(Dataset): def __init__(self, dataset_dir, crop_size, upscale_factor): super(TrainDatasetFromFolder, self).__init__() self.image_filenames = [join(dataset_dir, x) for x in listdir(dataset_dir) if is_image_file(x)] crop_size = calculate_valid_crop_size(crop_size, upscale_factor) self.hr_transform = train_hr_transform(crop_size) self.lr_transform = train_lr_transform(crop_size, upscale_factor) def __getitem__(self, index): hr_image = self.hr_transform(Image.open(self.image_filenames[index])) lr_image = self.lr_transform(hr_image) return lr_image, hr_image def __len__(self): return len(self.image_filenames) class ValDatasetFromFolder(Dataset): def __init__(self, dataset_dir, upscale_factor): super(ValDatasetFromFolder, self).__init__() self.image_filenames = [join(dataset_dir, x) for x in listdir(dataset_dir) if is_image_file(x)] self.upscale_factor = upscale_factor def __getitem__(self, index): hr_image = Image.open(self.image_filenames[index]) w, h = hr_image.size crop_size = calculate_valid_crop_size(min(w, h), self.upscale_factor) lr_scale = Resize(crop_size // self.upscale_factor, interpolation=Image.BICUBIC) hr_scale = Resize(crop_size, interpolation=Image.BICUBIC) hr_image = CenterCrop(crop_size)(hr_image) lr_image = lr_scale(hr_image) hr_restore_img = hr_scale(lr_image) return ToTensor()(lr_image), ToTensor()(hr_restore_img), ToTensor()(hr_image) def __len__(self): return len(self.image_filenames) class TestDatasetFromFolder(Dataset): def __init__(self, dataset_dir, upscale_factor): super(TestDatasetFromFolder, self).__init__() self.lr_path = dataset_dir + ‘/SRF_‘ + str(upscale_factor) + ‘/data/‘ self.hr_path = dataset_dir + ‘/SRF_‘ + str(upscale_factor) + ‘/target/‘ self.upscale_factor = upscale_factor self.lr_filenames = [join(self.lr_path, x) for x in listdir(self.lr_path) if is_image_file(x)] self.hr_filenames = [join(self.hr_path, x) for x in listdir(self.hr_path) if is_image_file(x)] def __getitem__(self, index): image_name = self.lr_filenames[index].split(‘/‘)[-1] lr_image = Image.open(self.lr_filenames[index]) w, h = lr_image.size hr_image = Image.open(self.hr_filenames[index]) hr_scale = Resize((self.upscale_factor * h, self.upscale_factor * w), interpolation=Image.BICUBIC) hr_restore_img = hr_scale(lr_image) return image_name, ToTensor()(lr_image), ToTensor()(hr_restore_img), ToTensor()(hr_image) def __len__(self): return len(self.lr_filenames)
(4)loss.py
import torch from torch import nn from torchvision.models.vgg import vgg16 class GeneratorLoss(nn.Module): def __init__(self): super(GeneratorLoss, self).__init__() vgg = vgg16(pretrained=True) loss_network = nn.Sequential(*list(vgg.features)[:31]).eval() for param in loss_network.parameters(): param.requires_grad = False self.loss_network = loss_network self.mse_loss = nn.MSELoss() self.tv_loss = TVLoss() def forward(self, out_labels, out_images, target_images): # Adversarial Loss adversarial_loss = torch.mean(1 - out_labels) # Perception Loss perception_loss = self.mse_loss(self.loss_network(out_images), self.loss_network(target_images)) # Image Loss image_loss = self.mse_loss(out_images, target_images) # TV Loss tv_loss = self.tv_loss(out_images) return image_loss + 0.001 * adversarial_loss + 0.006 * perception_loss + 2e-8 * tv_loss class TVLoss(nn.Module): def __init__(self, tv_loss_weight=1): super(TVLoss, self).__init__() self.tv_loss_weight = tv_loss_weight def forward(self, x): batch_size = x.size()[0] h_x = x.size()[2] w_x = x.size()[3] count_h = self.tensor_size(x[:, :, 1:, :]) count_w = self.tensor_size(x[:, :, :, 1:]) h_tv = torch.pow((x[:, :, 1:, :] - x[:, :, :h_x - 1, :]), 2).sum() w_tv = torch.pow((x[:, :, :, 1:] - x[:, :, :, :w_x - 1]), 2).sum() return self.tv_loss_weight * 2 * (h_tv / count_h + w_tv / count_w) / batch_size @staticmethod def tensor_size(t): return t.size()[1] * t.size()[2] * t.size()[3] if __name__ == "__main__": g_loss = GeneratorLoss() print(g_loss)
(5)model.py
import math import torch # import torch.nn.functional as F from torch import nn class Generator(nn.Module): def __init__(self, scale_factor): upsample_block_num = int(math.log(scale_factor, 2)) super(Generator, self).__init__() self.block1 = nn.Sequential( nn.Conv2d(3, 64, kernel_size=9, padding=4), nn.PReLU() ) self.block2 = ResidualBlock(64) self.block3 = ResidualBlock(64) self.block4 = ResidualBlock(64) self.block5 = ResidualBlock(64) self.block6 = ResidualBlock(64) self.block7 = nn.Sequential( nn.Conv2d(64, 64, kernel_size=3, padding=1), nn.BatchNorm2d(64) ) block8 = [UpsampleBLock(64, 2) for _ in range(upsample_block_num)] block8.append(nn.Conv2d(64, 3, kernel_size=9, padding=4)) self.block8 = nn.Sequential(*block8) def forward(self, x): block1 = self.block1(x) block2 = self.block2(block1) block3 = self.block3(block2) block4 = self.block4(block3) block5 = self.block5(block4) block6 = self.block6(block5) block7 = self.block7(block6) block8 = self.block8(block1 + block7) return (torch.tanh(block8) + 1) / 2 class Discriminator(nn.Module): def __init__(self): super(Discriminator, self).__init__() self.net = nn.Sequential( nn.Conv2d(3, 64, kernel_size=3, padding=1), nn.LeakyReLU(0.2), nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1), nn.BatchNorm2d(64), nn.LeakyReLU(0.2), nn.Conv2d(64, 128, kernel_size=3, padding=1), nn.BatchNorm2d(128), nn.LeakyReLU(0.2), nn.Conv2d(128, 128, kernel_size=3, stride=2, padding=1), nn.BatchNorm2d(128), nn.LeakyReLU(0.2), nn.Conv2d(128, 256, kernel_size=3, padding=1), nn.BatchNorm2d(256), nn.LeakyReLU(0.2), nn.Conv2d(256, 256, kernel_size=3, stride=2, padding=1), nn.BatchNorm2d(256), nn.LeakyReLU(0.2), nn.Conv2d(256, 512, kernel_size=3, padding=1), nn.BatchNorm2d(512), nn.LeakyReLU(0.2), nn.Conv2d(512, 512, kernel_size=3, stride=2, padding=1), nn.BatchNorm2d(512), nn.LeakyReLU(0.2), nn.AdaptiveAvgPool2d(1), nn.Conv2d(512, 1024, kernel_size=1), nn.LeakyReLU(0.2), nn.Conv2d(1024, 1, kernel_size=1) ) def forward(self, x): batch_size = x.size(0) return torch.sigmoid(self.net(x).view(batch_size)) class ResidualBlock(nn.Module): def __init__(self, channels): super(ResidualBlock, self).__init__() self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1) self.bn1 = nn.BatchNorm2d(channels) self.prelu = nn.PReLU() self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1) self.bn2 = nn.BatchNorm2d(channels) def forward(self, x): residual = self.conv1(x) residual = self.bn1(residual) residual = self.prelu(residual) residual = self.conv2(residual) residual = self.bn2(residual) return x + residual class UpsampleBLock(nn.Module): def __init__(self, in_channels, up_scale): super(UpsampleBLock, self).__init__() self.conv = nn.Conv2d(in_channels, in_channels * up_scale ** 2, kernel_size=3, padding=1) self.pixel_shuffle = nn.PixelShuffle(up_scale) self.prelu = nn.PReLU() def forward(self, x): x = self.conv(x) x = self.pixel_shuffle(x) x = self.prelu(x) return x
(6)test_image.py
import argparse import time import torch from PIL import Image from torch.autograd import Variable from torchvision.transforms import ToTensor, ToPILImage from model import Generator parser = argparse.ArgumentParser(description=‘Test Single Image‘) parser.add_argument(‘--upscale_factor‘, default=4, type=int, help=‘super resolution upscale factor‘) parser.add_argument(‘--test_mode‘, default=‘GPU‘, type=str, choices=[‘GPU‘, ‘CPU‘], help=‘using GPU or CPU‘) parser.add_argument(‘--image_name‘, type=str, help=‘test low resolution image name‘) parser.add_argument(‘--model_name‘, default=‘netG_epoch_2_100.pth‘, type=str, help=‘generator model epoch name‘) opt = parser.parse_args() UPSCALE_FACTOR = opt.upscale_factor TEST_MODE = True if opt.test_mode == ‘GPU‘ else False IMAGE_NAME = opt.image_name MODEL_NAME = opt.model_name model = Generator(UPSCALE_FACTOR).eval() if TEST_MODE: model.cuda() model.load_state_dict(torch.load(‘/content/drive/My Drive/app/SRGAN_master/‘ + MODEL_NAME)) else: model.load_state_dict(torch.load(‘/content/drive/My Drive/app/SRGAN_master/‘ + MODEL_NAME, map_location=lambda storage, loc: storage)) image = Image.open(IMAGE_NAME) with torch.no_grad(): image = Variable(ToTensor()(image)).unsqueeze(0) if TEST_MODE: image = image.cuda() start = time.clock() out = model(image) elapsed = (time.clock() - start) print(‘cost‘ + str(elapsed) + ‘s‘) out_img = ToPILImage()(out[0].data.cpu()) out_img.save(‘/content/drive/My Drive/app/SRGAN_master/result/_out_srf_2.tif‘)
以上是关于SRGAN 学习心得的主要内容,如果未能解决你的问题,请参考以下文章