TensorFlow 验证码识别
Posted lxl616
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TensorFlow 验证码识别相关的知识,希望对你有一定的参考价值。
TensorFlow 验证码识别
• 准备模型开发环境
第三方依赖包

Pillow (PIL Fork)
PIL(Python Imaging Library) 为 Python 解释器添加了图像处理功能。但是,在 2009 年发布
1.1.7 版本后,社区便停止更新和维护。
Pillow 是由 Alex Clark 及社区贡献者 一起开发和维护的一款分叉自 PIL 的图像工具库。
至今,社区依然非常活跃,Pillow 仍在快速迭代。
Pillow提供广泛的文件格式支持,高效的内部表示和相当强大的图像处理功能。
核心图像库旨在快速访问以几种基本像素格式存储的数据, 它应该为一般的图像处理工
具提供坚实的基础。
captcha
Catpcha 是一个生成图像和音频验证码的开源工具库。
from captcha.image import ImageCaptcha from captcha.audio import AudioCaptcha
image = ImageCaptcha(fonts=[‘/path/A.ttf‘, ‘/path/B.ttf’]) data = image.generate(‘1234’) image.write(‘1234‘, ‘out.png’)
audio = AudioCaptcha(voicedir=‘/path/to/voices’) data = audio.generate(‘1234’) audio.write(‘1234‘, ‘out.wav’)
pydot
pydot 是用纯 Python 实现的 GraphViz 接口,支持使用 GraphViz 解析和存储 DOT语言
(graph description language)。其主要依赖 pyparsing 和 GraphViz 这两个工具库。
pyparsing:仅用于加载DOT文件,在 pydot 安装期间自动安装。
GraphViz:将图形渲染为PDF,PNG,SVG等格式文件,需独立安装。
flask
flask 是一个基于 Werkzeug 和 jinja2 开发的 Python Web 应用程序框架,遵从 BSD 开源协
议。它以一种简约的方式实现了框架核心,又保留了扩展性。
• 生成验证码数据集
验证码(CAPTCHA)简介
全自动区分计算机和人类的公开图灵测试(英语:Completely Automated Public Turing test
to tell Computers and Humans Apart,简称CAPTCHA),俗称验证码,是一种区分用户是
计算机或人的公共全自动程序。在CAPTCHA测试中,作为服务器的计算机会自动生成一
个问题由用户来解答。这个问题可以由计算机生成并评判,但是必须只有人类才能解答。
由于计算机无法解答CAPTCHA的问题,所以回答出问题的用户就可以被认为是人类。
一种常用的CAPTCHA测试是让用户输入一个扭曲变形的图片上所显示的文字或数字,扭
曲变形是为了避免被光学字符识别(OCR, Optical Character Recognition)之类的计算机程
序自动识别出图片上的文数字而失去效果。由于这个测试是由计算机来考人类,而不是
标准图灵测试中那样由人类来考计算机,人们有时称CAPTCHA是一种反向图灵测试。
验证码(CAPTCHA)破解
一些曾经或者正在使用中的验证码系统已被破解。
这包括Yahoo验证码的一个早期版本 EZ-Gimpy,PayPal使用的验证码,LiveJournal、
phpBB使用的验证码,很多金融机构(主要是银行)使用的网银验证码以及很多其他网站
使用的验证码。
俄罗斯的一个黑客组织使用一个自动识别软件在2006年破解了Yahoo的CAPTCHA。准确
率大概是15%,但是攻击者可以每天尝试10万次,相对来说成本很低。而在2008年,
Google的CAPTCHA也被俄罗斯黑客所破解。攻击者使用两台不同的计算机来调整破解进
程,可能是用第二台计算机学习第一台对CAPTCHA的破解,或者是对成效进行监视。
验证码(CAPTCHA)演进

验证码(CAPTCHA)生成
使用 Pillow(PIL Fork) 和 captcha 库生成验证码图像:
PIL.Image.open(fp, mode=‘r’) - 打开和识别输入的图像(文件)
captcha.image.ImageCaptcha(width, height,) – 创建 ImageCaptcha 实例
captcha.image.ImageCaptcha.write(‘1234’, ‘out.png’) – 生成验证码并保存
captcha.image.ImageCaptcha.generate(‘1234’) – 生成验证码图像

代码实现:
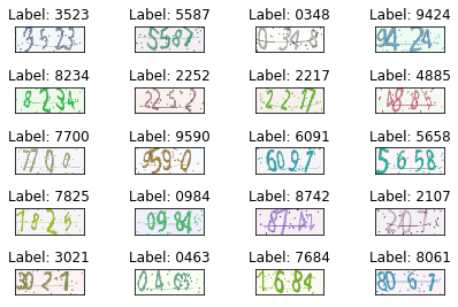
创建验证码数据集 引入第三方包 from captcha.image import ImageCaptcha import random import numpy as np import tensorflow.gfile as gfile import matplotlib.pyplot as plt import PIL.Image as Image 定义常量和字符集 NUMBER = [‘0‘, ‘1‘, ‘2‘, ‘3‘, ‘4‘, ‘5‘, ‘6‘, ‘7‘, ‘8‘, ‘9‘] LOWERCASE = [‘a‘, ‘b‘, ‘c‘, ‘d‘, ‘e‘, ‘f‘, ‘g‘, ‘h‘, ‘i‘, ‘j‘, ‘k‘, ‘l‘, ‘m‘, ‘n‘, ‘o‘, ‘p‘, ‘q‘, ‘r‘, ‘s‘, ‘t‘, ‘u‘, ‘v‘, ‘w‘, ‘x‘, ‘y‘, ‘z‘] UPPERCASE = [‘A‘, ‘B‘, ‘C‘, ‘D‘, ‘E‘, ‘F‘, ‘G‘, ‘H‘, ‘I‘, ‘J‘, ‘K‘, ‘L‘, ‘M‘, ‘N‘, ‘O‘, ‘P‘, ‘Q‘, ‘R‘, ‘S‘, ‘T‘, ‘U‘, ‘V‘, ‘W‘, ‘X‘, ‘Y‘, ‘Z‘] CAPTCHA_CHARSET = NUMBER # 验证码字符集 CAPTCHA_LEN = 4 # 验证码长度 CAPTCHA_HEIGHT = 60 # 验证码高度 CAPTCHA_WIDTH = 160 # 验证码宽度 TRAIN_DATASET_SIZE = 5000 # 验证码数据集大小 TEST_DATASET_SIZE = 1000 TRAIN_DATA_DIR = ‘./train-data/‘ # 验证码数据集目录 TEST_DATA_DIR = ‘./test-data/‘ 生成随机字符的方法 def gen_random_text(charset=CAPTCHA_CHARSET, length=CAPTCHA_LEN): text = [random.choice(charset) for _ in range(length)] return ‘‘.join(text) 创建并保存验证码数据集的方法 def create_captcha_dataset(size=100, data_dir=‘./data/‘, height=60, width=160, image_format=‘.png‘): # 如果保存验证码图像,先清空 data_dir 目录 if gfile.Exists(data_dir): gfile.DeleteRecursively(data_dir) gfile.MakeDirs(data_dir) # 创建 ImageCaptcha 实例 captcha captcha = ImageCaptcha(width=width, height=height) for _ in range(size): # 生成随机的验证码字符 text = gen_random_text(CAPTCHA_CHARSET, CAPTCHA_LEN) captcha.write(text, data_dir + text + image_format) return None 创建并保存训练集 create_captcha_dataset(TRAIN_DATASET_SIZE, TRAIN_DATA_DIR) 创建并保存测试集 create_captcha_dataset(TEST_DATASET_SIZE, TEST_DATA_DIR) 生成并返回验证码数据集的方法 def gen_captcha_dataset(size=100, height=60, width=160, image_format=‘.png‘): # 创建 ImageCaptcha 实例 captcha captcha = ImageCaptcha(width=width, height=height) # 创建图像和文本数组 images, texts = [None]*size, [None]*size for i in range(size): # 生成随机的验证码字符 texts[i] = gen_random_text(CAPTCHA_CHARSET, CAPTCHA_LEN) # 使用 PIL.Image.open() 识别新生成的验证码图像 # 然后,将图像转换为形如(CAPTCHA_WIDTH, CAPTCHA_HEIGHT, 3) 的 Numpy 数组 images[i] = np.array(Image.open(captcha.generate(texts[i]))) return images, texts 生成 100 张验证码图像和字符 images, texts = gen_captcha_dataset() plt.figure() for i in range(20): plt.subplot(5,4,i+1) # 绘制前20个验证码,以5行4列子图形式展示 plt.tight_layout() # 自动适配子图尺寸 plt.imshow(images[i]) plt.title("Label: ".format(texts[i])) # 设置标签为子图标题 plt.xticks([]) # 删除x轴标记 plt.yticks([]) # 删除y轴标记 plt.show()
• 输入与输出数据处理
输入数据处理
图像处理:RGB图 -> 灰度图 -> 规范化数据

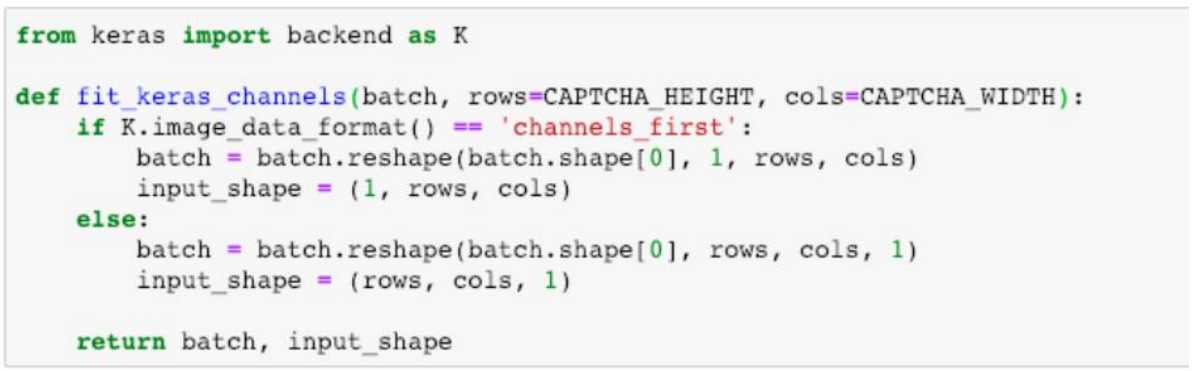
输入数据处理
适配 Keras 图像数据格式:“channels_frist” 或 “channels_last”
输出数据处理
One-hot 编码:验证码转向量

解码:模型输出向量转验证码

• 模型结构设计
分类问题

图像分类模型 AlexNet
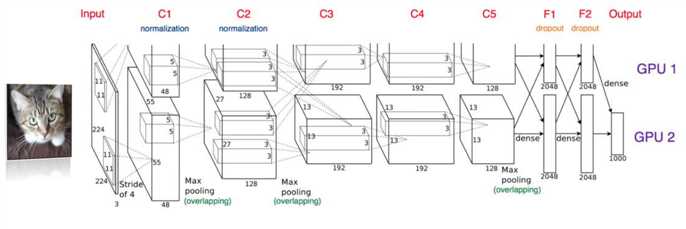
使用卷积进行特征提取


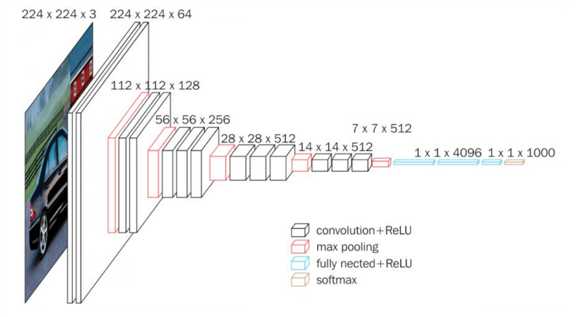
图像分类模型 VGG-16
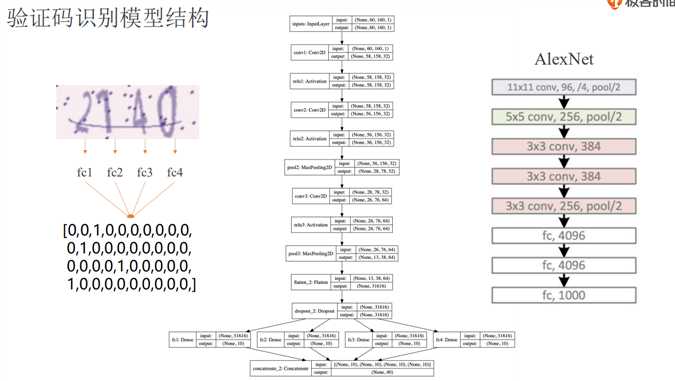
验证码识别模型结构
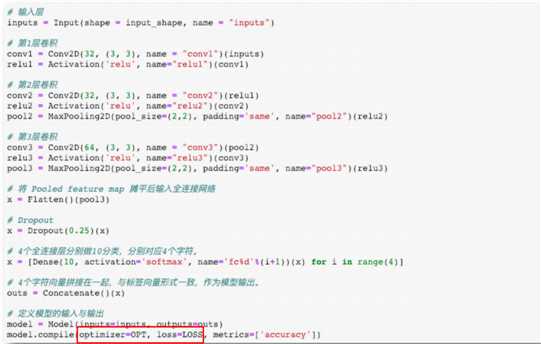
验证码识别模型实现
• 模型损失函数设计
交叉熵(Cross-Entropy, CE)
我们使用交叉熵作为该模型的损失函数。
虽然 Categorical / Binary CE 是更常用的损失函数,不过他们都是 CE 的变体。
CE 定义如下:
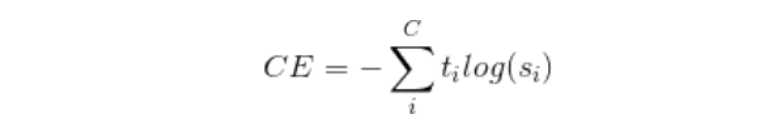
对于二分类问题 (C‘=2) ,CE 定义如下:
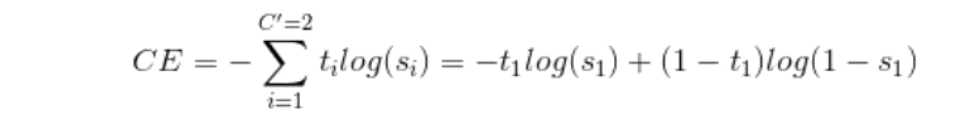
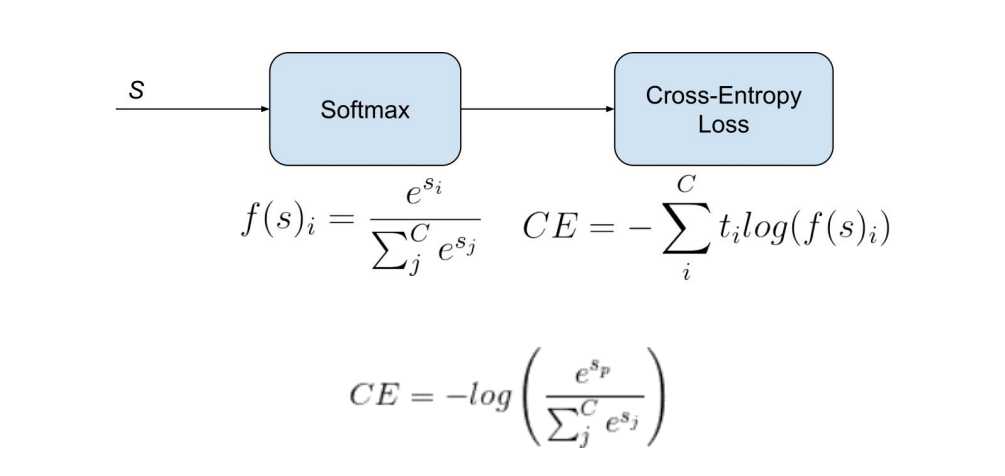
Categorical CE Loss(Softmax Loss)
常用于输出为 One-hot 向量的多类别分类(Multi-Class Classification)模型。
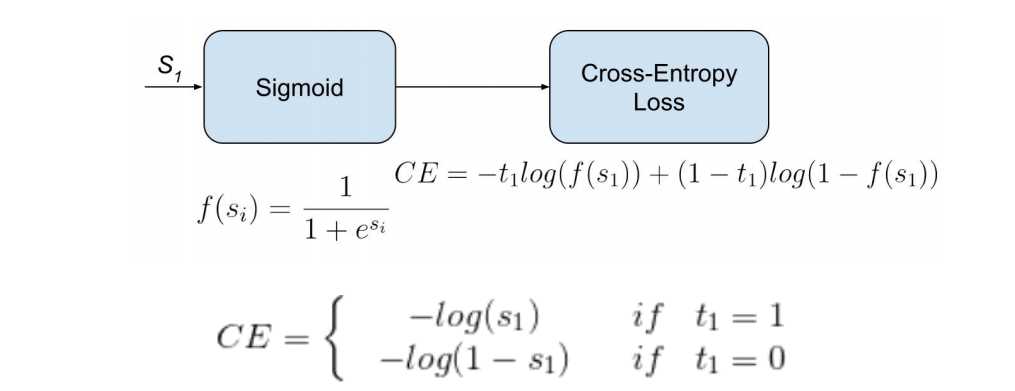
Binary CE Loss(Sigmoid CE Loss)
与 Softmax Loss 不同,Binary CE Loss 对于每个向量分量(class)都是独立
的,这意味着每个向量分量计算的损失不受其他分量的影响。
因此,它常被用于多标签分类(Multi-label classification)模型。
• 模型训练过程分析
模型训练过程
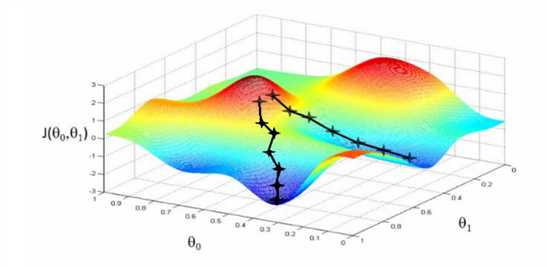
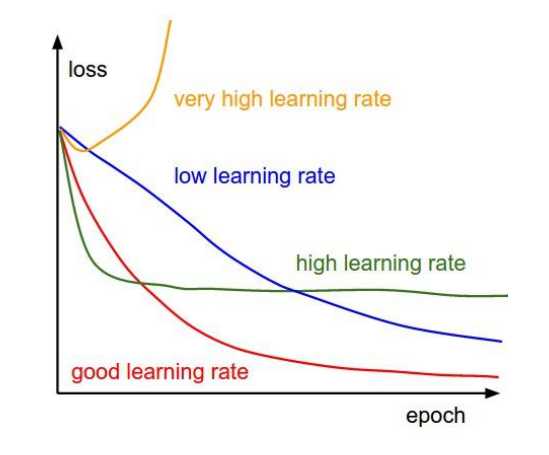
学习率(Learning rate)
学习率与损失值变化(模型收敛速度)直接相关。
何时加大学习率
• 训练初期,损失值一直没什么波动
何时减小学习率
• 训练初期,损失值直接爆炸或者 NAN
• 损失值先开始速降,后平稳多时
• 训练后期,损失值反复上下波动
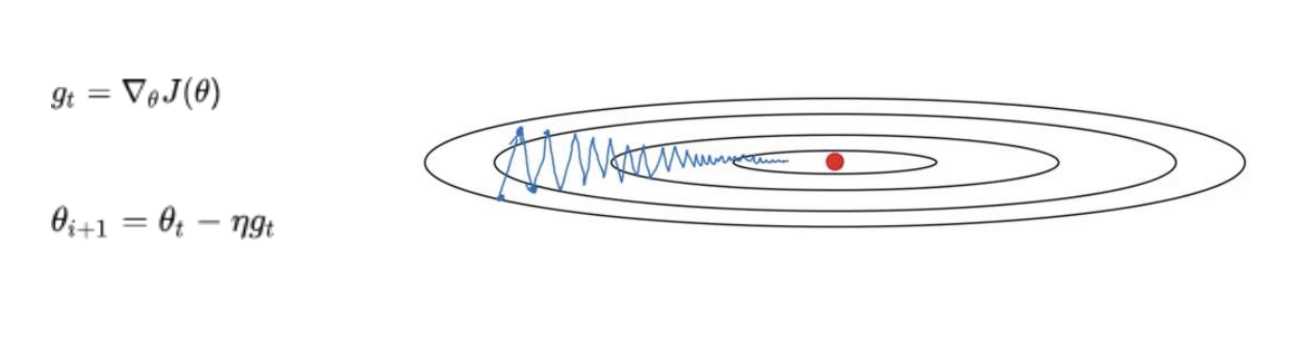
优化器介绍:SGD(Stochastic Gradient Descent)
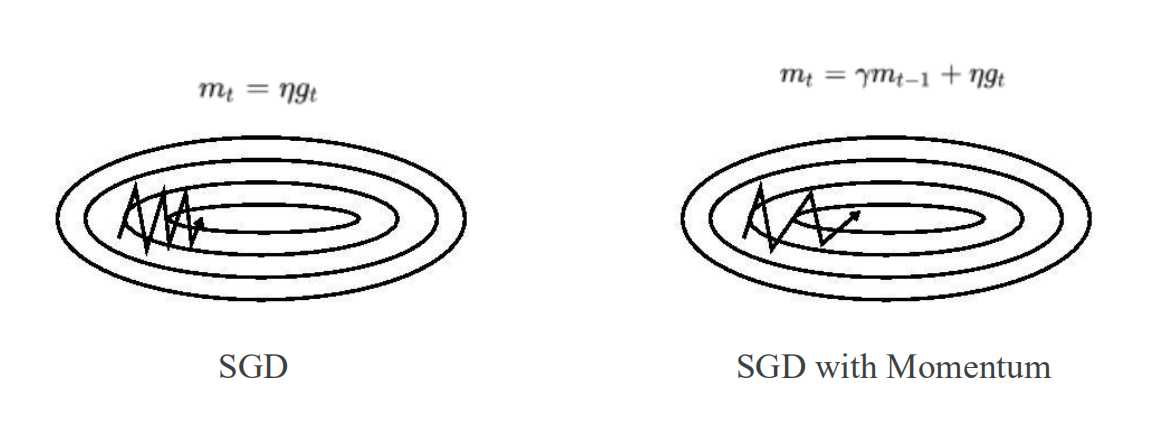
优化器介绍:SGD-M(Momentum)
SGD 在遇到沟壑时容易陷入震荡。为此,可以为其引入动量(Momentum),加速 SGD
在正确方向的下降并抑制震荡。
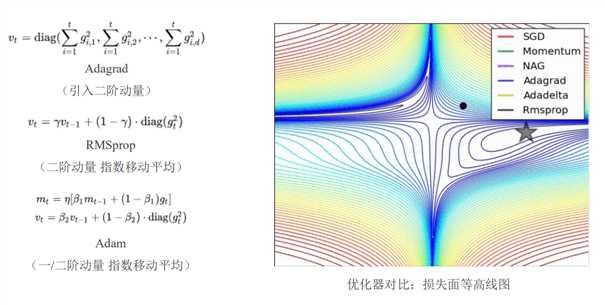
优化器介绍:Adagrad – RMSprop – Adam
优化器对比:鞍点
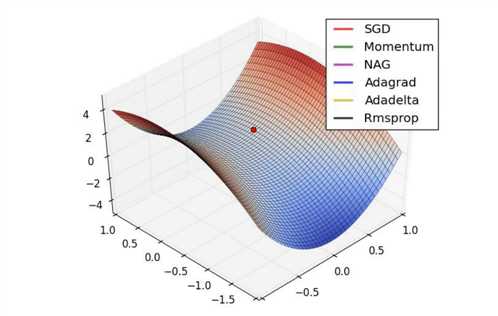
优化器对比: 验证码识别模型
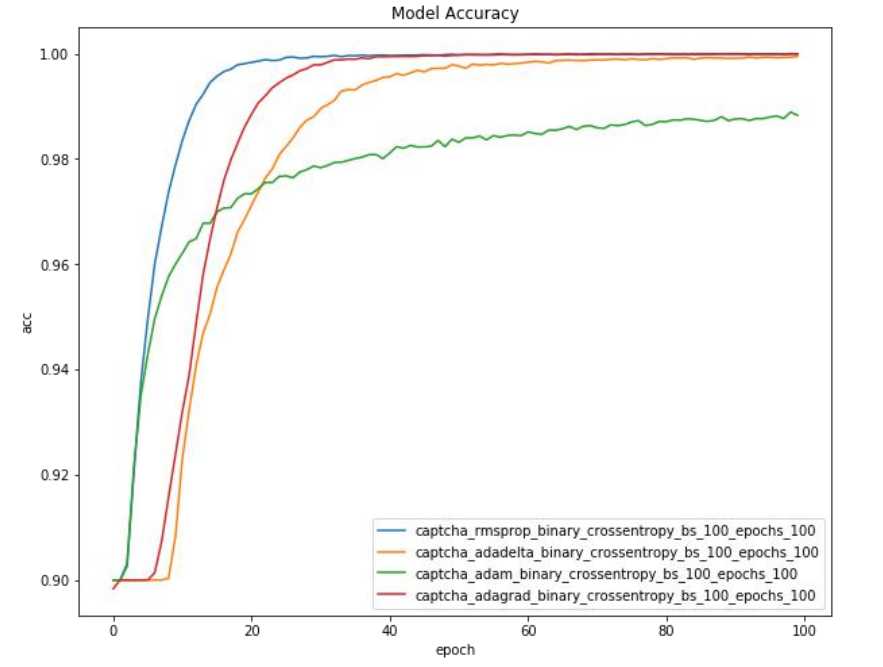
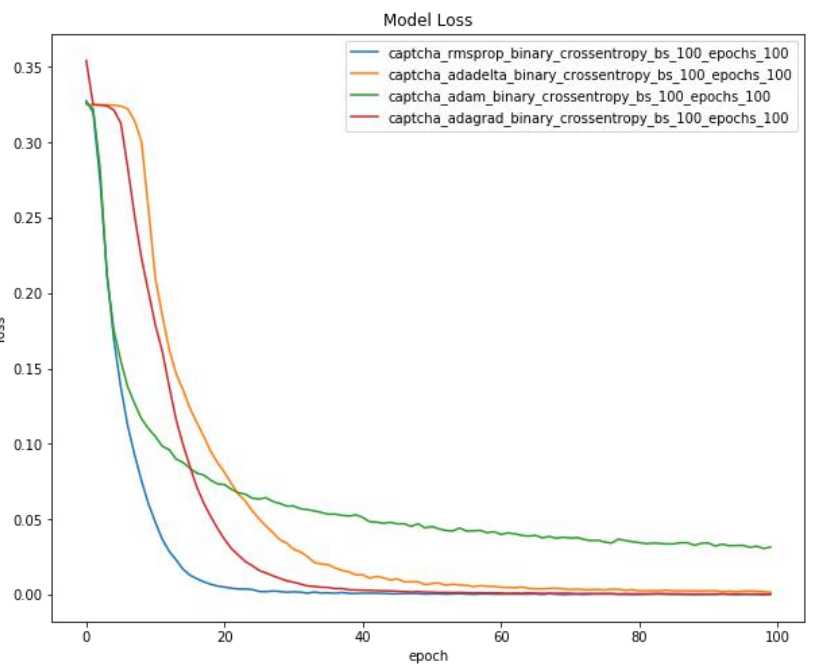
• 模型部署与效果演示
数据-模型-服务流水线
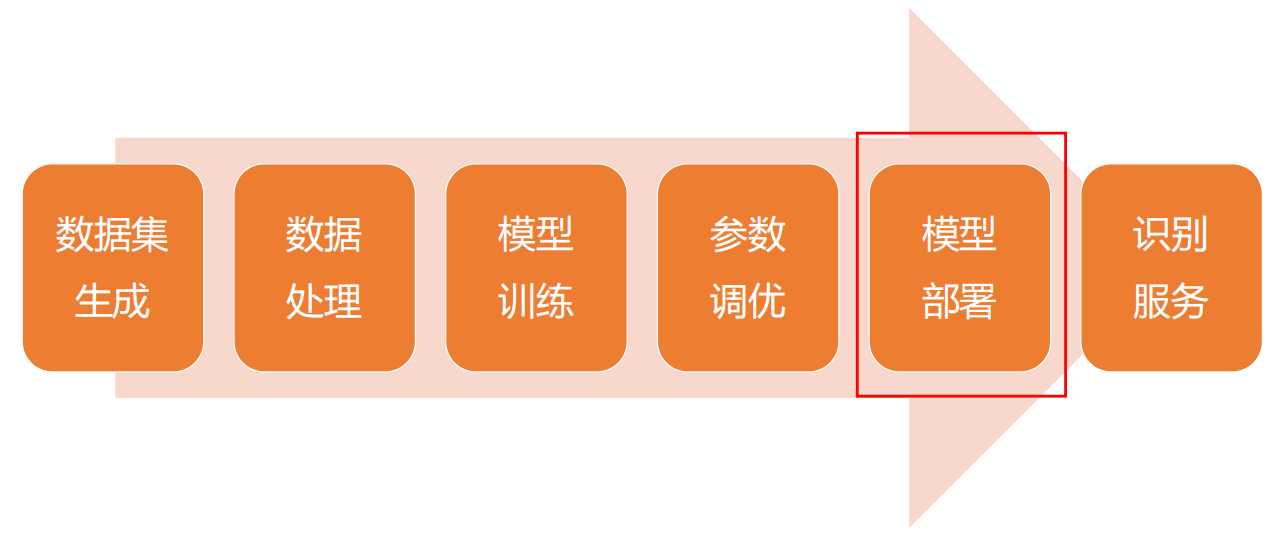
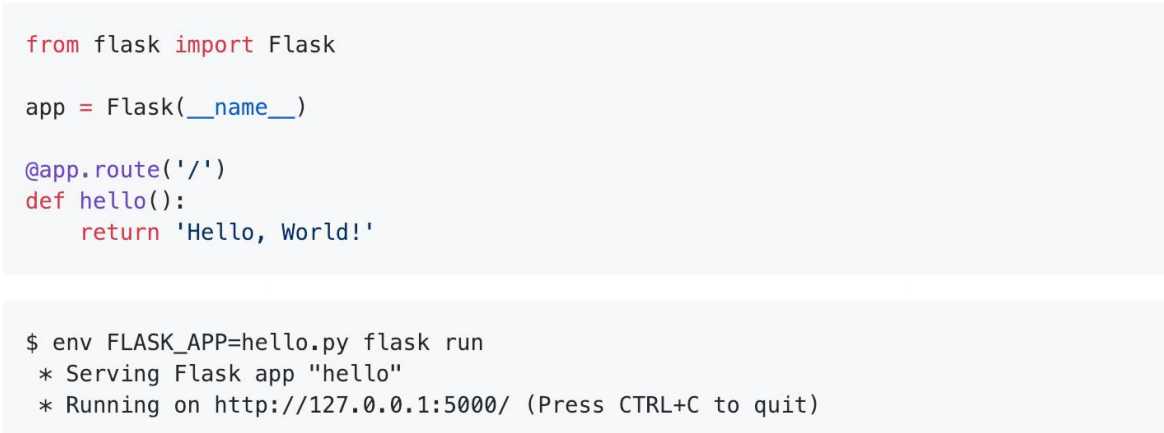
使用 Flask 快速搭建 验证码识别服务
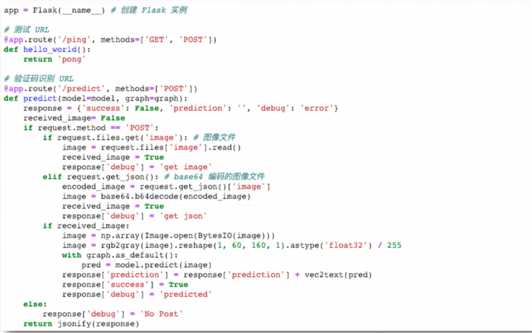
使用 Flask 启动 验证码识别服务
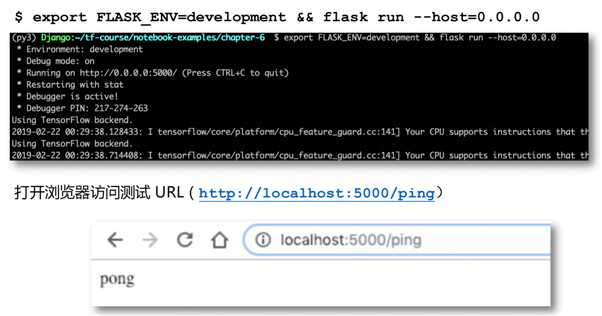
访问 验证码识别服务
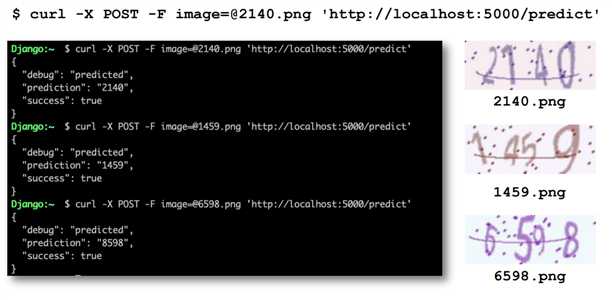
以上是关于TensorFlow 验证码识别的主要内容,如果未能解决你的问题,请参考以下文章