Python学习日记 编码基础
Posted fantac
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python学习日记 编码基础相关的知识,希望对你有一定的参考价值。
初始编码
ASCII最开始为7位,一共128字符。最后确定8位,一共256个字符,最左边的为拓展位,为以后的开发做准备。
ASCII码的最左边的一位为0。
基本换算:8位(bit) = 1字节(byte)
1024byte = 1 KB
1024KB = 1MB
1024MB = 1GB
1024GB = 1TB
电脑的传输还有存储实际上都是以二进制的形式进行的。
Unicode:美国最初是使用ASCII编码,后来为了解决全球化的文字问题,创建了万国码(Unicode)
开端:
一个中文最初给两个字节(16位)来表示,后来发现中文就将近十万字,不够,所以之后Unicode用4个字节(32位)来表示一个中文。
一个英文给四个字节(32位)来表示。
升级后:
UTF-8:
一个中文用3个字节(24位)表示
一个英文用1个字节(8位)表示
一个欧洲文字用2个字节(16位)表示
国内使用编码:
GBK:
一个中文用2个字节(16位)表示
一个英文用1个字节(8位)表示
(1)各个编码之间的二进制是不能互相是别的,会产生乱码
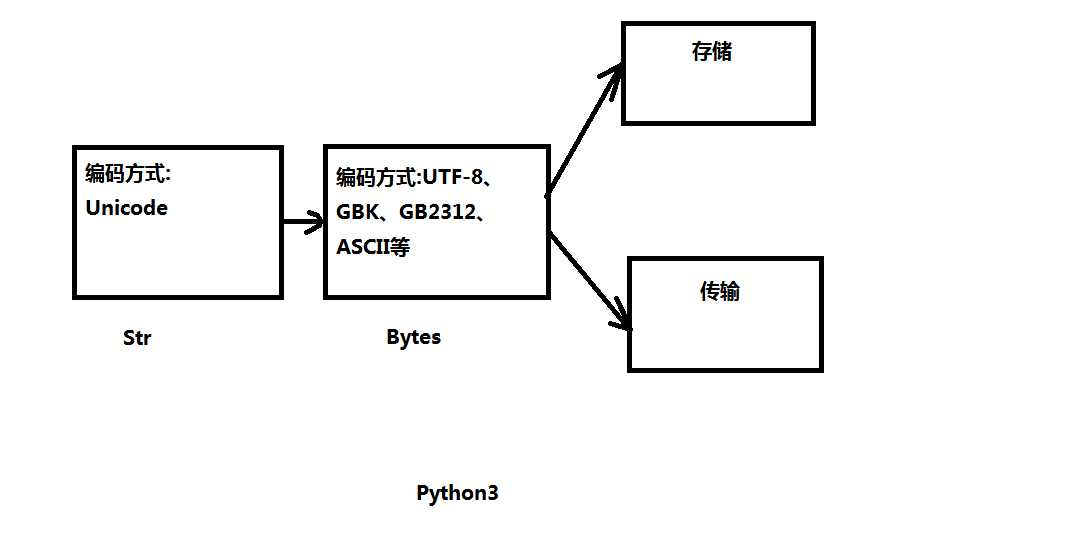
(2)Unicode 的字符要用4个字节(32位)来表示,占用了太多内存。因此文件的储存、传输不能是Unicode类型,只能是UTF-8、UTF-16、GBK、GB2312、ASCII等类型
UTF-8和GBK的转变要借助Unicode
(3)在Python3中str在内存中是用Unicode存储的
而bytes类型是以(UTF-8、GB2312等编码)
对于英文:
str的表现形式:
s = ‘abc‘
str的编码方式:
以Unicode的01010101形式
bytes的表现形式:
b_s = b‘abc‘
bytes的编码方式:
以UTF-8、GBK等的01010101形式
对于中文:
str的表现形式:
s = ‘中国‘
str的编码方式:
以Unicode的01010101形式
bytes的表现形式:
以UTF-8的b‘\\xe4\\xb8\\xad\\xe5\\x9b\\xbd‘形式
bytes的编码方式:
以UTF-8、GBK等的01010101形式
编码(将str->bytes):
中文:
s1= ‘中国‘ s2 = s1.encode(‘utf-8‘) print(s2) #b‘\\xe4\\xb8\\xad\\xe5\\x9b\\xbd‘ s2 = s1.encode(‘gbk‘) print(s2) #b‘\\xd6\\xd0\\xb9\\xfa‘
英文:
s1 = ‘abc‘ s2 = s1.encode(‘utf-8‘) print(s2) #b‘abc‘ s2 = s1.encode(‘gbk‘) print(s2) #b‘abc‘
解码(将bytes->str):
b = b‘\\xe4\\xb8\\xad\\xe5\\x9b\\xbd‘ s = b.decode(‘utf-8‘) print(s) #中国
b = b‘abc‘ s = b.decode(‘utf-8‘) print(s) #abc
其他:
1.Python2和Python3的区别:
Python2 Python3
<1>.print 可以加括号,也可以不加括号
print(‘abc‘) print(‘abc‘)
print ‘abc‘
<2>.xrange()生成器 range()
range()
<3>.raw_input() input()
2.
= 是赋值
is 是比较内存地址
== 比较值是否相等
id(内容)
3.小数据池
在Python中数字和字符串存在着小数据池,它的作用是在一个数据范围内节省内存空间,共用一个内存地址
list、dict、set、tuple没有小数据池这一概念
int:
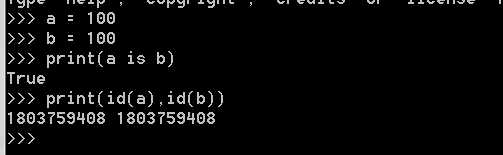
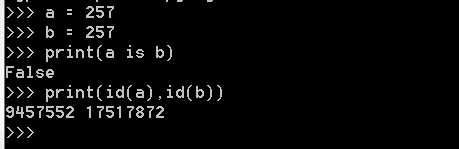
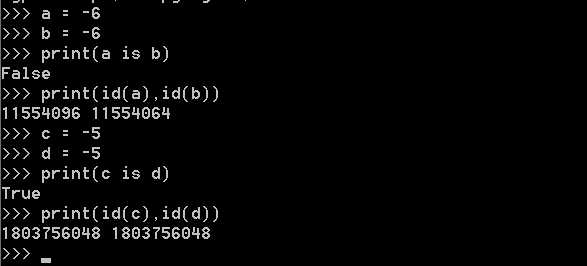
只要数值在范围(-5 - 256),它们都共用一个相同的内存地址
例1:
例2:
例3:
str:
<1>.当字符串长度为0或1时默认使用小数据池,当长度大于1时且没有含有特殊字符(包括加减乘除)时也将使用小数据池
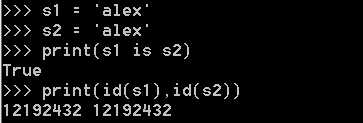
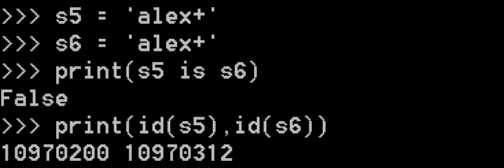
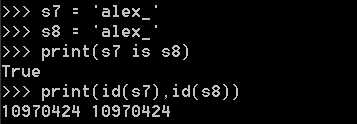
<2>.一个字符串长度小于等于20用的还是同一个内存地址,长度大于20以后用的是2个内存地址
当乘数为1时:
仅含字符串、数字、下划线,默认使用小数据池:
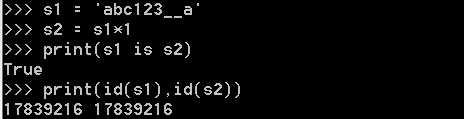
含其他字符,长度<=1时,默认使用小数据池
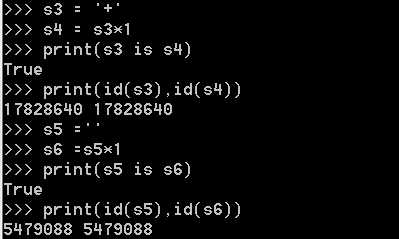
含其他字符,长度>1时,默认使用小数据池
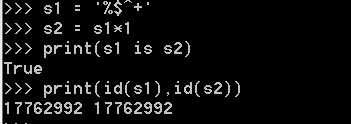
当乘数大于1时:
字符长度小于等于20将使用小数据池
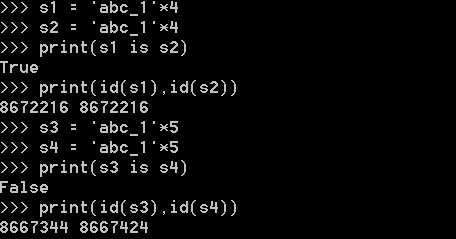
以上是关于Python学习日记 编码基础的主要内容,如果未能解决你的问题,请参考以下文章