mapreduce 基础内容
Posted tudousiya
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mapreduce 基础内容相关的知识,希望对你有一定的参考价值。
MapReduce:分布式计算框架,用来分解大数据量的处理
Map阶段对数据集上的独立元素进行指定的操作,生成键值对形成中间结果,Reduce阶段对中间结果中相同的键的所有值进行规约,以得到最终的结果。
优点:
1)易于编程:简单的实现一些接口
2)可扩展性当计算资源不足时,通过增加机器可以扩展他的计算能力
3)高容错性:当一台机器挂了,会把机器上的计算任务转移到另外的一个节点上
缺点:不适合实时的统计处理(流式计算),MapReduce处理的数据是静态的。例如:处理历史数据,(因为每次的运算结果都是到磁盘,如果再次处理要先进行读磁盘)
我们先认识以下几类:
1)Mapper:是一个泛型类型,有四个形参,分别是map函数的输入键、输入值、输出键、输出值。泛型类型的形参只能是引用类型,不能是原始类型(如int、double、char)输出类型为(key-Value pair)
2)Shuffle:数据的迁移Map到Reduce阶段。
3)Combine:(局部统计:针对的是一个map的统计,最小化对数据的迁移)。
4)Partitioner:是分区处理器他把key的hash拿到值对3取模,如果值为0放到第一个Reducer,如果值为1放入第二个Reducer,如果值为2放入第三个Reducer,不管每个mapper输送过来的key,只要key相同就会进入同一个Reducer。
5)Reduce:进行的一个全局统计接受每一个Map的统计,按照所有的key值拿过来进行统计。
MapReduce基本原理
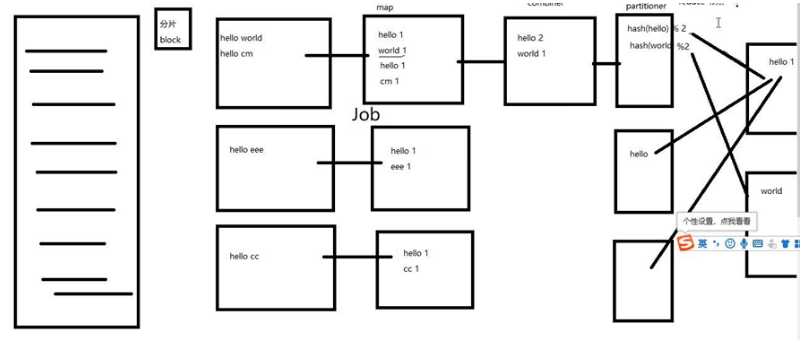
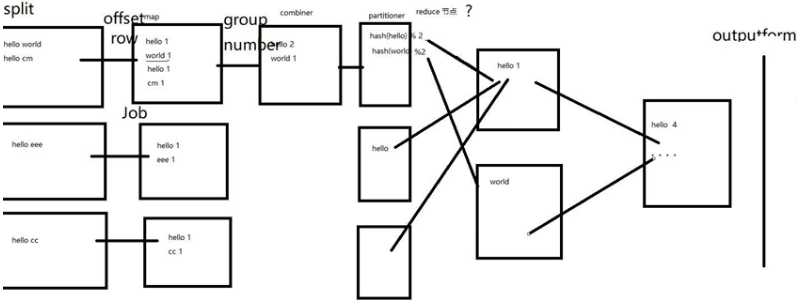
1)map:读取的数据进入到环状缓冲区(100m)
读到80%,会将缓冲区的文件传入磁盘,当缓冲区写到磁盘的时候会进行分区,排序,combin会进行分区排序,而溢出的文件会生成溢出文件,最后会将这些文件统计进行排序分区,等待reduce前来取走
2)reduce:根据hash计算好的map去取值,然后合并文件,按照内部的k/v进行归并排序,再根据key进行分组。
以上是关于mapreduce 基础内容的主要内容,如果未能解决你的问题,请参考以下文章