深度学习-交叉熵损失
Posted timverion
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习-交叉熵损失相关的知识,希望对你有一定的参考价值。
SoftMax回归
对于MNIST中的每个图像都是零到九之间的手写数字。所以给定的图像只能有十个可能的东西。我们希望能够看到一个图像,并给出它是每个数字的概率。
例如,我们的模型可能会看到一个九分之一的图片,80%的人肯定它是一个九,但是给它一个5%的几率是八分之一(因为顶级循环),并有一点概率所有其他,因为它不是100%确定。
这是一个经典的情况,其中softmax回归是一种自然简单的模型。如果要将概率分配给几个不同的东西之一的对象,softmax是要做的事情,因为softmax给出了一个[0,1]之间的概率值加起来为1的列表。
稍后,当我们训练更复杂型号,最后一步将是一层softmax。
那么我们通常说的激活函数有很多,我们这个使用softmax函数.softmax模型可以用来给不同的对象分配概率。即使在之后,我们训练更加精细的模型时,最后一步也需要用softmax来分配概率。
这里的softmax可以看成是一个激励(activation)函数,把我们定义的线性函数的输出转换成我们想要的格式,也就是关于10个数字类的概率分布。
因此,给定一张图片,它对于每一个数字的吻合度可以被softmax函数转换成为一个概率值。
softmax回归有两个步骤:首先我们将我们的输入的证据加在某些类中,然后将该证据转换成概率。每个输出的概率,对应着独热编码中具体的类别。
下面是softmax的公式:
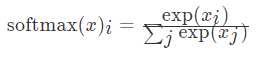
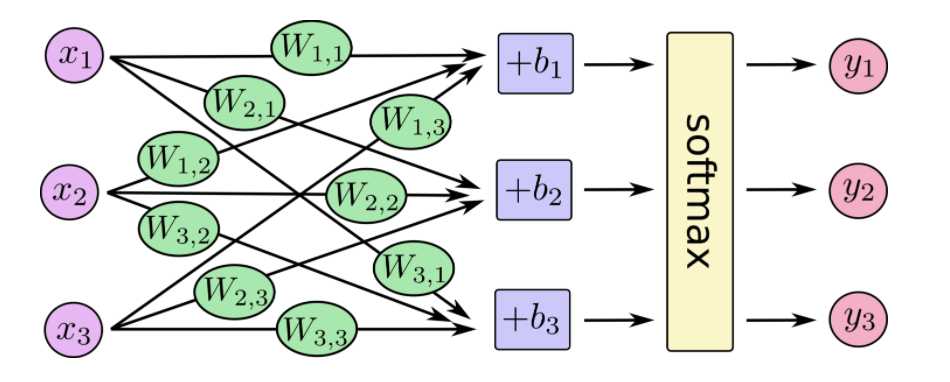
在神经网络中,整个过程如下:
也就是最后的softmax模型,用数学式子表示:
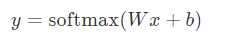
交叉熵损失
我们前面学习过了一种计算误差损失,预测值与标准值差的平方和。不过在这里我们不能再使用这个方式,我们的输出值是概率并且还有标签。那么就需要一种更好的方法形容这个分类过程的好坏。
这里就要用到交叉熵损失。确定模型损失的一个非常常见的非常好的功能称为“交叉熵”。交叉熵来源于对信息理论中的信息压缩代码的思考,但是从压缩到机器学习在很多领域都是一个重要的思想。它定义为
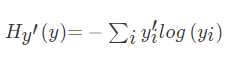
它表示的是目标标签值与经过权值求和过后的对应类别输出值
tf.nn.softmax_cross_entropy_with_logits
tf.nn.softmax_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, dim=-1, name=None)
计算logits与labels之间的softmax交叉熵损失,该函数已经包含了softmax功能,logits和labels必须有相同的形状[batch_size, num_classes]和相同的类型(float16, float32, or float64)。
- labels 独热编码过的标签值
- logits 没有log调用过的输入值
- 返回 交叉熵损失列表
tf.nn.softmax_cross_entropy_with_logits(labels=y_label, logits=y))
以上是关于深度学习-交叉熵损失的主要内容,如果未能解决你的问题,请参考以下文章