批量比较两个txt文件的内容
Posted stt-ac
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了批量比较两个txt文件的内容相关的知识,希望对你有一定的参考价值。
为了方便测试人员的测试,我们把检测到的数据保存在txt文件中,然后批量比较得出错误和遗漏的数据
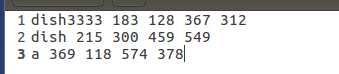
txt 文件格式为下图所示,第一个值为类别,后四个为左上右下角坐标
‘‘‘ @author: Shang Tongtong @license: (C) Copyright 2019-present, SeetaTech, Co.,Ltd. @contact: tongtong.shang@seetatech.com @file: txt_test.py @time: 19-7-19 上午10:49 @desc: 测试两张图片txt文件的类别是否一致以及框的iou ‘‘‘ import os import numpy as np def get_op(txt_path): #把txt文件内容放到数组 f = open(txt_path) boxes = [] for linesp in f.readlines(): boxes.append(linesp.split(‘\\n‘)[0]) return boxes def compute_iou(groud_truth, detect): """ computing IoU :param groud_truth: (y0, x0, y1, x1), which reflects (top, left, bottom, right) :param detect: (y0, x0, y1, x1) :return: scala value of IoU """ # computing area of each rectangles S_groud_truth = (groud_truth[2] - groud_truth[0]) * (groud_truth[3] - groud_truth[1]) S_detect = (detect[2] - detect[0]) * (detect[3] - detect[1]) # computing the sum_area sum_area = S_groud_truth + S_detect # find the each edge of intersect rectangle left_line = max(groud_truth[1], detect[1]) right_line = min(groud_truth[3], detect[3]) top_line = max(groud_truth[0], detect[0]) bottom_line = min(groud_truth[2], detect[2]) # judge if there is an intersect if left_line >= right_line or top_line >= bottom_line: return 0 else: intersect = (right_line - left_line) * (bottom_line - top_line) return intersect / (sum_area - intersect) def compare(gt_txt, de_txt): fn = 0 fp = 0 gt_count = len(open(gt_txt).readlines()) #txt文件的行数 de_count = len(open(de_txt).readlines()) if de_count < gt_count: fn += 1 print(‘ ‘+‘omit!!!!!!‘) for i in range(de_count): all_iou = [] for j in range(gt_count): de_box = (get_op(de_txt)[i]).split()[1:5] de_box = list(map(int, de_box)) #数组中的字符串转为整型 gt_box = (get_op(gt_txt)[j]).split()[1:5] gt_box = list(map(int, gt_box)) iou = compute_iou(gt_box, de_box) all_iou.append(iou) j += 1 num = np.argmax(np.max(all_iou)) #获得数组中最大值的下标 de_name = (get_op(de_txt)[i]).split()[0] gt_name = (get_op(gt_txt)[i]).split()[num] #if (get_op(de_txt)[i])[0] != (get_op(gt_txt)[i])[num]: if de_name != gt_name: fp += 1 print(‘ ‘+‘error!!!!!!!!‘ + gt_name + ‘ is incorrectly predicted ‘ + de_name) i += 1 return fn, fp def walk_dir(*paths): x_list = [] for path in paths: for (root, dirs, files) in os.walk(path): files = sorted(files) for item in files: x_list.append(item) return x_list if __name__ == ‘__main__‘: g_truth = r‘/home/stt/桌面/s/txt/‘ detect = r‘/home/stt/桌面/s/txt2/‘ fn = 0 fp = 0 gt_list = walk_dir(g_truth) for gt in gt_list: gt_txt = os.path.join(g_truth, gt) de_txt = os.path.join(detect, gt) print(‘ is being detected‘.format(gt)) a = compare(gt_txt, de_txt) fn += a[0] fp += a[1] print(‘The sum of fn is ,and the sum of fp is ‘.format(fn, fp))
以上是关于批量比较两个txt文件的内容的主要内容,如果未能解决你的问题,请参考以下文章