Node实战-----爬取网页图片
Posted jiguiyan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Node实战-----爬取网页图片相关的知识,希望对你有一定的参考价值。
在本篇博文中我将实现一个完整的实例:主要使用Node.js爬取一个网页,需要通过第三方模块cheerio.js分析这个网页的内容,最后将这个网页的图片保存个在本地。
一、项目目录与思路
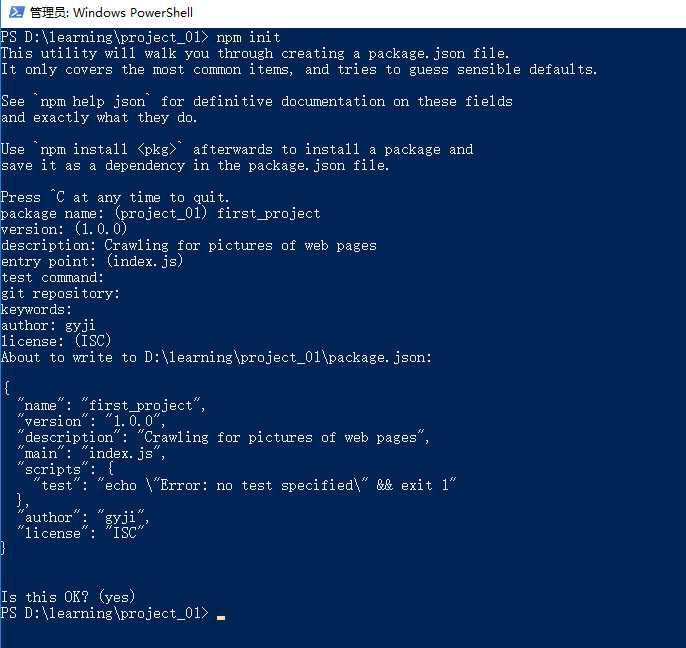
新建一个项目名为:project_01,输入命令在控制台,使其生成package.json文件:
命令:
npm init
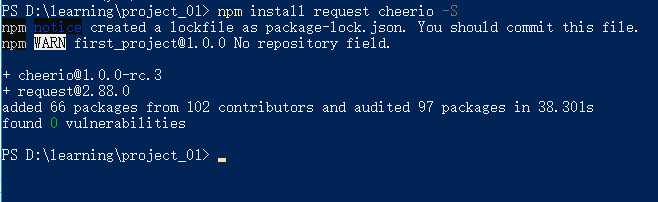
在控制台输入npm install命令下载需要的模块,在本项目中需要的request和cheerio模块,将使用命令进行下载到本地:
命令:
npm install request cheerio -S
此时项目的文件夹的目录为:
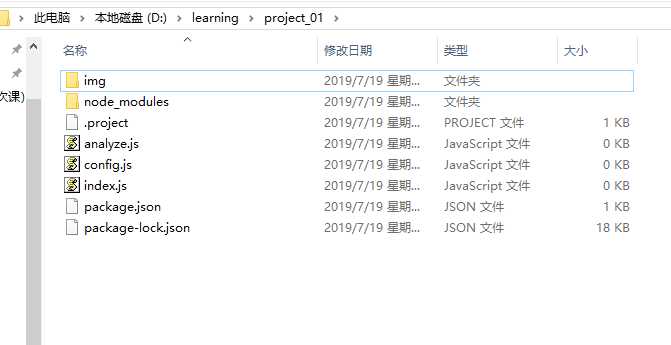
- img文件夹用来存储图片文件
- node_modules文件夹是模块默认的保存位置
- index.js文件是整个项目的入口文件。
- config.js文件是配置文件,用来存放网页地址和图片文件夹的路径,这样做的目的是使整个项目的可拓展性增强。
- analyze.js文件用来存储分析DOM的方法。
- package.json文件是包的描述文件。
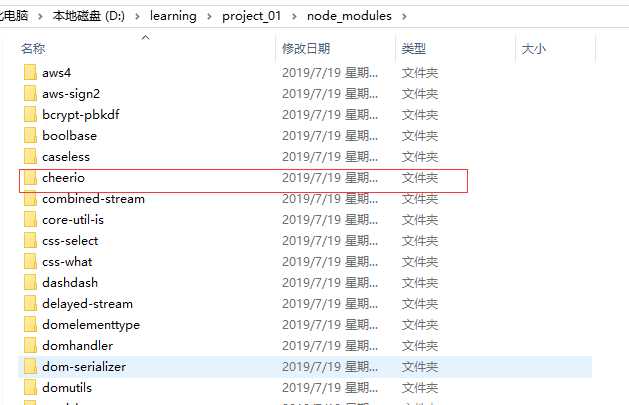
打开node_modules文件夹可以看到相应的模块:
整体的思路:通过第三方模块request的请求网页地址,从而得到整个网页的DOM结构,根据DOM结构利用cheerio模块分析出图片文件的地址,再次请求这个地址,再次请求这个地址,最后将得到的图片数据存储在本地。
二、 配置网页地址及图片存放的文件夹
配置内容:config.js中,在文件中通过exports导出这些配置内容,从而使其它文件可以使用
以爬码农网为例
代码:
config.js
const url=‘http://www.codeceo.com/‘;//填写自己请求的具体的网址 const path=require(‘path‘); const imgDir=path.join(__dirname,‘img‘); module.exports.url=url; module.exports.imgDir=imgDir;
三、解析DOM得到的图片地址
得到DOM结构之后,将分析DOM部分代码写入analyze.js文件中,通过cheerio得到每一张图片的地址,最后利用一个回调函数callback处理这个地址(这里的回调函数callback是发送请求):
代码:
analyze.js:
const cheerio=require(‘cheerio‘); const fs=require(‘fs‘); function findImg(dom,Callback) let $=cheerio.load(dom); $(‘img‘).each(function(i,elem) let imgSrc=$(this).attr(‘src‘); Callback(imgSrc,i); ); module.exports.findImg=findImg;
cheerio模块可以像jQuery一样操作DOM,这里得到的是请求网页中每一张图片的文件地址
四、请求图片的地址以及图片文件的保存
请求图片的的地址:
将请求的操作放在主模块index.js文件中,将config.js和analyze.js文件引入这个模块,利用request模块请求图片的地址,得到DOM结构,将DOM结构给analyze的findImg方法处理,代码:
const http=require(‘http‘); const fs=require(‘fs‘); const request=require(‘request‘); const path=require(‘path‘); const config=require(‘./config‘); const analyze=require(‘./analyze‘); function start() request(config.url,function(err,res,body) console.log(‘start‘); if(!err && res) console.log(‘start‘); analyze.findImg(body); )
图片文件的保存:
通过分析DOM结构得到图片地址后,利用request再次发送请求,将请求得到的数据写入本地即可,这里也将其封装为一个函数,追加在index.js文件中:
代码:
function downLoad(imgUrl,i) let ext=imgUrl.split(‘.‘).pop(); request(imgUrl).pipe(fs.createWriteStream(path.join(config.imgDir,i+‘.‘+ext), ‘enconding‘:‘binary‘ )) console.log(i);
注意:所获取的数据的二进制数据,所以一定要设置编码格式为binary,因为writeFile的默认编码格式为utf-8,否则保存的图片无法打开。
同时,我们需要将这个download函数作为参数传递给analyze模块的findImg方法,最后运行这个项目的主函数start(),这样项目才会运行起来
index.js
const http=require(‘http‘); const fs=require(‘fs‘); const request=require(‘request‘); const path=require(‘path‘); const config=require(‘./config‘); const analyze=require(‘./analyze‘); function start() request(config.url,function(err,res,body) console.log(‘start‘); if(!err && res) console.log(‘start‘); analyze.findImg(body,downLoad); ) function downLoad(imgUrl,i) let ext=imgUrl.split(‘.‘).pop(); request(imgUrl).pipe(fs.createWriteStream(path.join(config.imgDir,i+‘.‘+ext), ‘enconding‘:‘binary‘ )) console.log(i); start();
最终的结果显示:
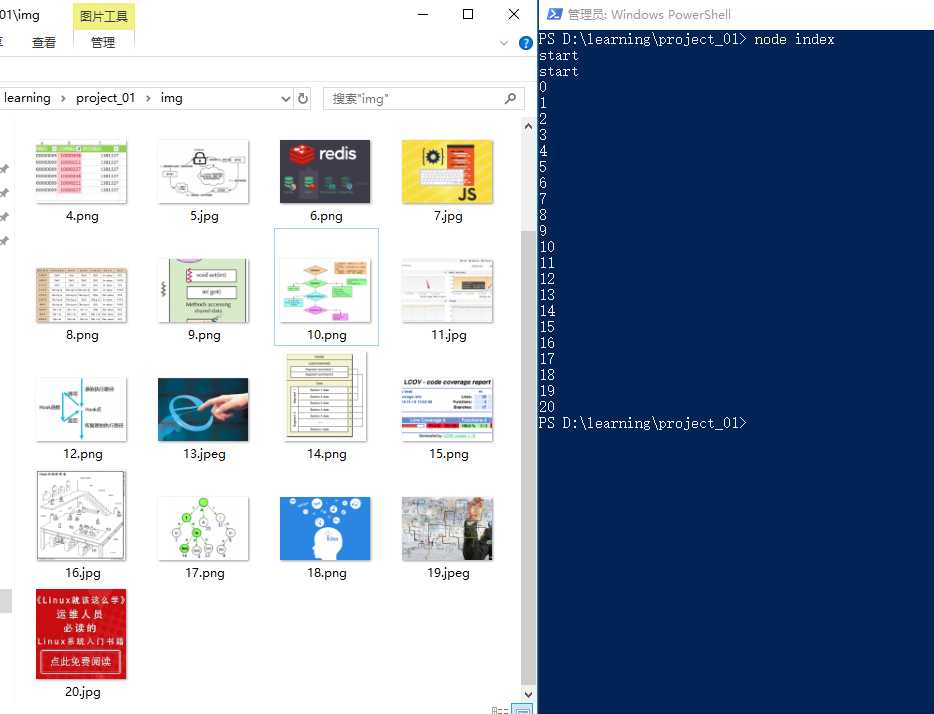
运行代码不到5秒钟,就抓取完了并命名好了,这相对于我们手动保存,速度非常快
你想抓取哪个网站的图片就抓取哪个网站的图片(当然除了那些做了防爬虫处理的)。
以上是关于Node实战-----爬取网页图片的主要内容,如果未能解决你的问题,请参考以下文章