MapReduce示例式理解
Posted jeshy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReduce示例式理解相关的知识,希望对你有一定的参考价值。
从word count这个实例理解MapReduce。
MapReduce大体上分为六个步骤:input, split, map, shuffle, reduce, output。细节描述如下:
输入(input):如给定一个文档,包含如下四行:
Hello Java
Hello C
Hello Java
Hello C++
2. 拆分(split):将上述文档中每一行的内容转换为key-value对,即:
0 - Hello Java
1 - Hello C
2 – Hello Java
3 - Hello C++
3. 映射(map):将拆分之后的内容转换成新的key-value对,即:
(Hello , 1)
(Java , 1)
(Hello , 1)
(C , 1)
(Hello , 1)
(Java , 1)
(Hello , 1)
(C++ , 1)
4. 派发(shuffle):将key相同的扔到一起去,即:
(Hello , 1)
(Hello , 1)
(Hello , 1)
(Hello , 1)
(Java , 1)
(Java , 1)
(C , 1)
(C++ , 1)
注意:这一步需要移动数据,原来的数据可能在不同的datanode上,这一步过后,相同key的数据会被移动到同一台机器上。最终,它会返回一个list包含各种k-value对,即:
Hello: 1,1,1,1
Java: 1,1
C: 1
C++: 1
5. 缩减(reduce):把同一个key的结果加在一起。如:
(Hello , 4)
(Java , 2)
(C , 1)
(C++,1)
6. 输出(output): 输出缩减之后的所有结果。
MapReduce的思想:
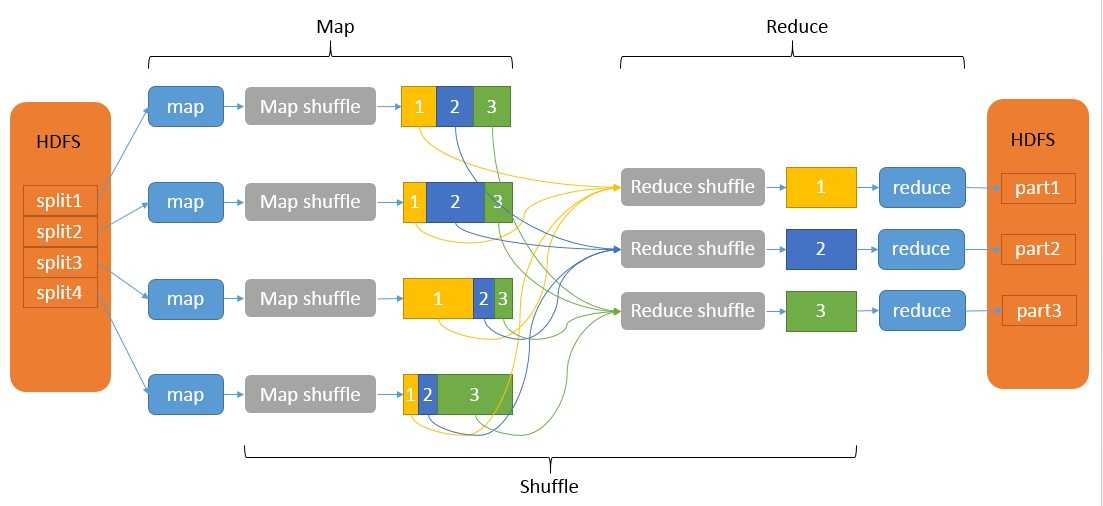
重要的是Shuffle:
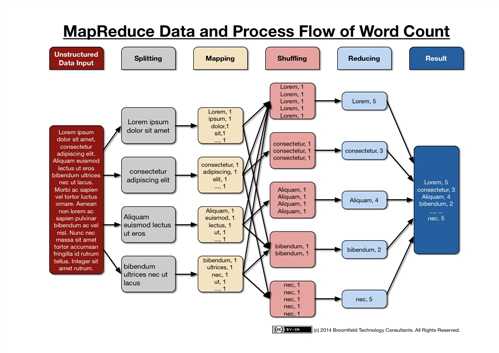
来自知乎 峰峰 https://www.zhihu.com/question/23345991/answer/223113502
以上是关于MapReduce示例式理解的主要内容,如果未能解决你的问题,请参考以下文章