kafka&zookeeper
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka&zookeeper相关的知识,希望对你有一定的参考价值。
一、搭建Zookeeper集群Zookeeper是一个分布式开源框架,提供了协调分布式应用的基本服务,它向外部应用暴露一组通用服务——分布式同步(Distributed Synchronization)、命名服务(Naming Service)、集群维护(Group Maintenance)等,简化分布式应用协调及其管理的难度,提供高性能的分布式服务。ZooKeeper本身可以以单机模式安装运行,不过它的长处在于通过分布式ZooKeeper集群(一个Leader,多个Follower),基于一定的策略来保证ZooKeeper集群的稳定性和可用性,从而实现分布式应用的可靠性。
1.在zookeeper.apache.org上下载zookeeper-3.4.8.tar.gz
2.解压 tar -xzvf zookeeper-3.4.8.tar.gz
3.修改权限 sudo chown -R cms(ubuntu用户名) zookeeper-3.4.8
4.修改配置文件 /etc/profile,增加

5.对Zookeeper的配置文件的参数进行设置
进入zookeeper-3.4.5/conf
1)cp zoo_sample.cfg zoo.cfg
2)在zookeeper下新建一个存放数据的目录
mkdir zookerperdata
3)vim zoo.cfg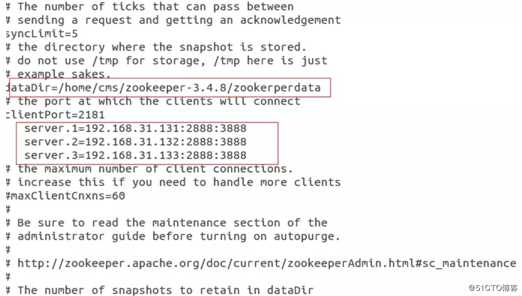
4)注意上图的配置中master,slave1分别为主机名
在上面的配置文件中"server.id=host:port:port"中的第一个port是从机器(follower)连接到主机器(leader)的端口号,第二个port是进行leadership选举的端口号。
5)创建myid
接下来在dataDir所指定的目录下(zookeeper-3.4.8/zookerperdata/)创建一个文件名为myid的文件,文件中的内容只有一行,为本主机对应的id值,也就是上图中server.id中的id。例如:在服务器1中的myid的内容应该写入1。
vim myid
6)远程复制到slave1,slave2相同的目录下
scp -r zookeeper-3.4.8 [email protected]:/home/cms/
scp -r zookeeper-3.4.8 [email protected]:/home/cms/
7)修改slave1,slave2机器上的myid的值分别为2和3
启动ZooKeeper集群
在ZooKeeper集群的每个结点上,执行启动ZooKeeper服务的脚本,如下所示:

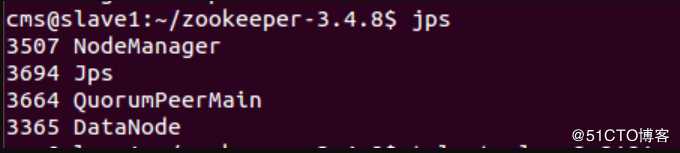

其中,QuorumPeerMain是zookeeper进程,启动正常。
如上依次启动了所有机器上的Zookeeper之后可以通过ZooKeeper的脚本来查看启动状态,包括集群中各个结点的角色(或是Leader,或是Follower),如下所示,是在ZooKeeper集群中的每个结点上查询的结果
二、搭建kafka集群
1.下载
下载官网:http://kafka.apache.org/downloads
下载版本:与自己安装的Scala版本对应的版本,个人习惯是下载最新版本的前一版
kafka_2.11-0.10.0.1.tgz
2.安装
tar -xzf kafka_2.11-0.10.0.1.tgz
cp kafka_2.11-0.10.0.1.tgz /home/cms/kafka
3.配置环境变量
即path、classpath,意义不大,可不配置
4.修改配置文件kafka/config/server.properties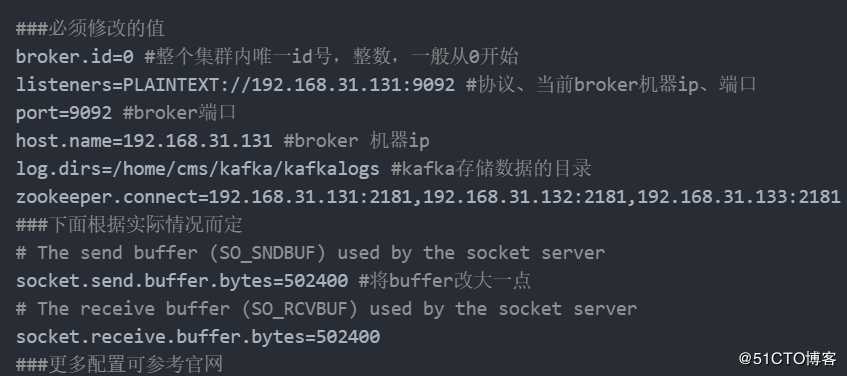
5.在kafka的目录下,建立kafka存储数据的目录
mkdir kafkalogs
6.其他节点配置
将kafka文件复制到其他节点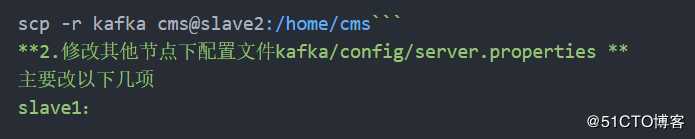
broker.id=1 #整个集群内唯一id号,整数,一般从0开始
listeners=PLAINTEXT://192.168.31.132:9092 #协议、当前broker机器ip、端口
port=9092 #broker端口
host.name=192.168.31.132 #broker 机器ip
7.每个节点下启动zookerper
8.启动kafka进程,在每个节点的kafka/bin目录下
--zookeeper : zookeeper集群列表,用英文逗号分隔。可以不用指定zookeeper整个集群内的节点列表,只指定某个或某几个zookeeper节点列表也是你可以的
replication-factor : 复制数目,提供failover机制;1代表只在一个broker上有数据记录,一般值都大于1,代表一份数据会自动同步到其他的多个broker,防止某个broker宕机后数据丢失。
partitions : 一个topic可以被切分成多个partitions,一个消费者可以消费多个partitions,但一个partitions只能被一个消费者消费,所以增加partitions可以增加消费者的吞吐量。kafka只保证一个partitions内的消息是有序的,多个一个partitions之间的数据是无序的。
9.启动生产者和消费者
生产者:kafka-console-producer.sh --broker-list 192.168.31.131:9092 --topic test5
--broker-list : 值可以为broker集群中的一个或多个节点
消费者:
kafka-console-consumer.sh --zookeeper 192.168.31.131:2181,192.168.31.132:2181,192.168.31.133:2181 --topic test5 --from-beginning
--zookeeper : 值可以为zookeeper集群中的一个或多个节点
--from-beginning 表示从开始第一个消息开始接收
10.查看topic
kafka-topics.sh --list --zookeeper 192.168.31.131:2181,192.168.31.132:2181,192.168.31.133:2181
11.查看topic详情
kafka-topics.sh --describe --zookeeper 192.168.31.131:2181,192.168.31.132:2181,192.168.31.133:2181 --topic test5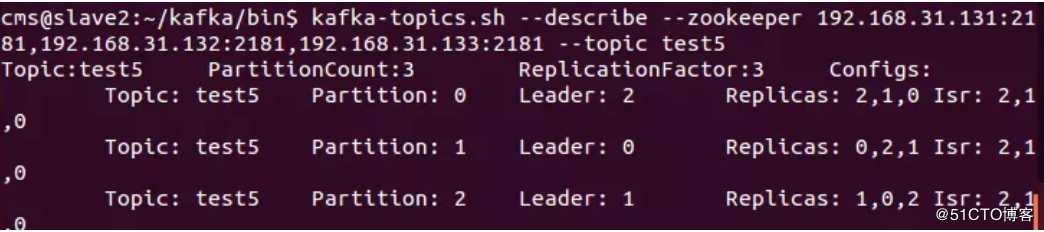
状态说明:test有三个分区分别为1、2、3,分区0的leader是3(broker.id),分区0有三个副本,并且状态都为lsr(ln-sync,表示可以参加选举成为leader)。
12.删除topic
在config/server.properties中加入delete.topic.enable=true并重启服务,在执行如下命令
kafka-topics.sh --delete --zookeeper 192.168.31.131:2181,192.168.31.132:2181,192.168.31.133:2181 --topic test5
以上是关于kafka&zookeeper的主要内容,如果未能解决你的问题,请参考以下文章
三.Kafka入门到精通-SpringBoot整合Kafka(同步&异步消息&事务消息&手动确认)