知识点小结~9
Posted fightmg
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了知识点小结~9相关的知识,希望对你有一定的参考价值。
文本三件客之~AWK
awk的语言风格更像c语言。
awk:内部有多条语句时,需用;隔开。
内置变量:
FS:filed separate 输入awk字段间分隔符
OFS:output filed separate 输出字段分隔符
RS:record separate 输入awk记录分隔符
ORS:output record separate 输入awk记录分隔符
NF:number field 字段数量
NR:number record 记录号
FNR:各文件分别记数
FILENAME: 当前文件名
ARGC:命令行参数个数 awk是第一个参数
ARGV:数组,保存的是命令行所给定的各参数,ARGV[0]是awk
BEGIN:执行在操作文本之前,一般用于打印表头
以下三种写法输出相同结果
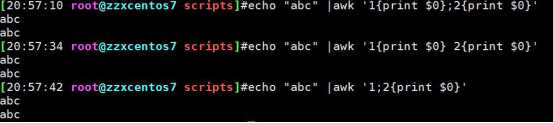
awk中应用数组:

通过文本的行数控制打印次数:
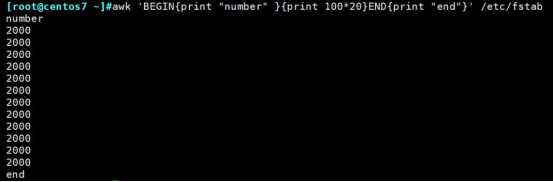
END:操作文本完毕后执行,一般用于汇总。
字符串打印需要加“”,否则认为是变量,数字可不加双引号

执行一次(BEGIN语句在操作文本前执行)

-F参数:指定分隔符,print打印使用 “”内部被当做普通字符处理

$1为第一列,$3为第二列

指定默认分隔符:-v 定义变量
awk -v FS=":" ‘print $1FS$3‘ 分隔符可以指定分隔变量 作用同 awk -F ":" ‘print $1":"$3‘


使用指定分隔符可使用正则表达式

OFS 输出界定符
RS 默认记录分隔符为\\n,(逐行处理)
ORS 默认输出记录分隔符为\\n,可指定。

awk中的变量无需加$符,位置变量$1 $2...$NF除外。单独使用NF时代表该条记录的字段数。(BEGIN END必须大写)
print 直接输出变量 ,自动输出换行; printf 格式化输出,需加\\n才换行。

无论是print还是printf在打印普通变量时无需加$符号,符合c语言风格。
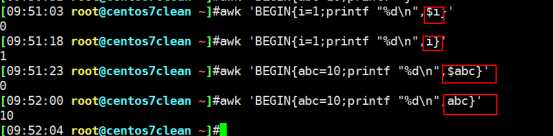
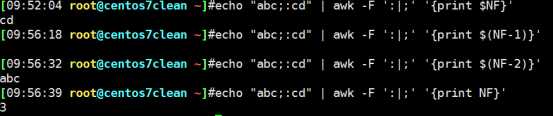
倒数第二个变量$(NF-1),
当-F指定了两个字段分隔符时,若两个分隔符相邻出现时可认为两个分隔符中间有一个空列
无论是printf还是print当使用位置变量时需加$,内置参数NF为一个该行列数,为一个固定的数。

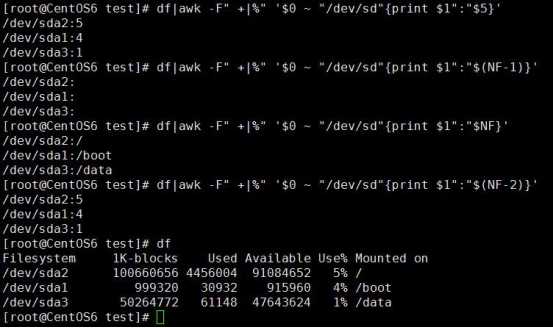
区间匹配,若没有匹配到以M开头的行则显示到文件最后,条件后面不跟执行语句,默认执行print $0
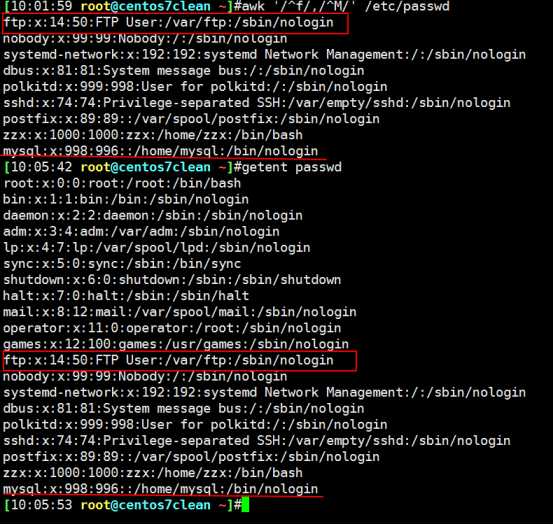
FNR:分文件打印记录号(行号);FILENAME:当前文件名称
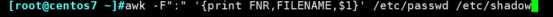
变量定义的三种方法
1、awk -v name=""
2、awk name=""
3、在shell中定义变量,在awk中调用 username=user;awk -v name=$username

只有在执行脚本时例外,可理解为向脚本内部传参数
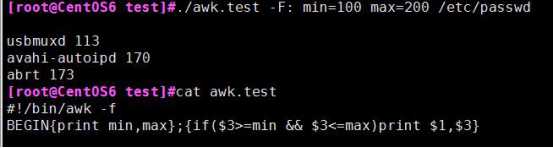
内部定义变量覆盖外部定义变量

若变量先打印再定义则第一行打印为空,从第二行开始变量生效

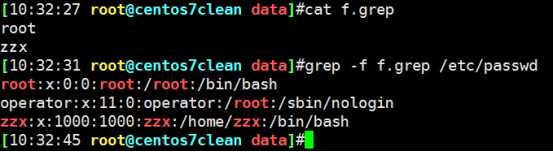
-f 参数读入文件为命令,(其中条件为或的关系)
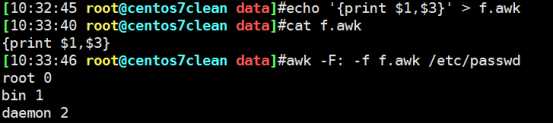
文件中
printf输出是若定义字符宽度小输出的参数,则定义参数无效。
printf命令格式:printf "format",item1,item2...
必须规定format;不会自动换行,需‘\\n’
format中需要分别为后面每个item制定格式
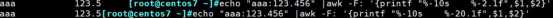
$0代表一行 NR(nmuber record):记录号为0的是:BEGIN输出的行号,第0行,表头

模式匹配符:~:左边是否与右边匹配;!~:是否不匹配,支持正则表达式。


~:左边是否和右边匹配;包含的字符串可用/str/或“str”

运算符优先级:!(取反) 优先级大于 >(大于号)

等价


逻辑运算,非0非空则为真,0与空则为假。与函数返回值$?相区别。
真:结果为非0值,非空字符串都是真;
假:结果为空字符串或0值都是假。
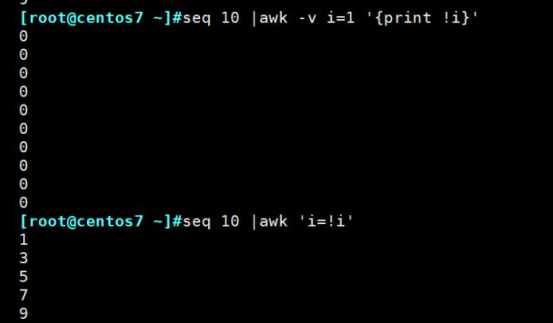
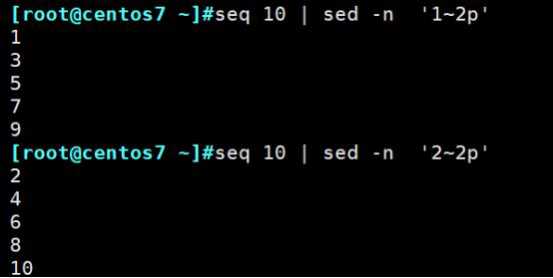
sed中打印奇数行和偶数行:
length($i):内置函数,计算字符串长度。
rand():返回0-1之间的随机数,srand()生成随机数种子 srand(); int(rand()*MAX)
sub(r,s,[t]):对t字符串搜索;r表示模式匹配的内容,并将第一个匹配内容替换为s
sub(被替换的字符,替换成的字符,所要操作的字段)
echo "2008:08:08 08:08:08" | awk ‘sub(/:/,"-",$1)‘
echo "2008:08:08 08:08:08" | awk ‘sub(/:/,"-",$1);print $0‘
•gsub(r,s,[t]):对t字符串进行搜索;r表示的模式匹配的内容,并全部替换为s所表示的内容
echo "2008:08:08 08:08:08" | awk ‘gsub(/:/,"-",$0)‘
echo "2008:08:08 08:08:08" | awk ‘gsub(/:/,"-",$0);print $0‘
•split(s,array,[r]):以r为分隔符,切割字符串s,并将切割后的结果保存至array所表示的数组中,第一个索引值为1,第二个索引值为2,…,第n个索引值为n
split(被操作的字段,切割后的字段所要存放的数组名,切割字符)
netstat -tn | awk ‘/^tcp\\>/split($5,ip,":");count[ip[1]]++
ENDfor (i in count) print i,count[i]’
利用关联数组进行区别统计:

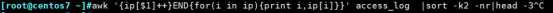
awk中if判断语句

next 参数, 结束本行处理,进行下一行的编辑处理
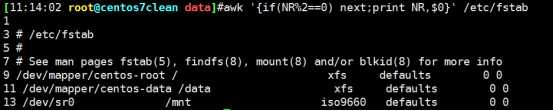
awk中去重打印:
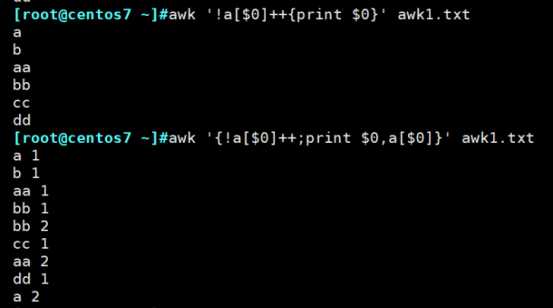
awk内for循环体内只有一条语句时,可以不加

这样写语法错误:

这样写正确:
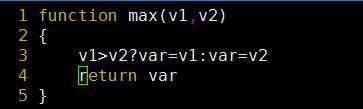
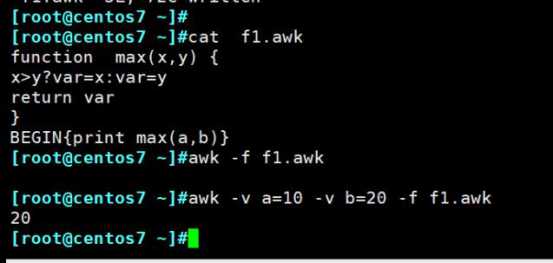
使用awk利用关联数组进行分组统计:

awk 中通过system调用shell语言命令

注意即便是通过system调用shell语言命令,其中的变量(位置变量除外)仍不需要加$符

使用脚本执行awk语句,在脚本外定义的变量若想在BEGIN中使用需使用-v参数。
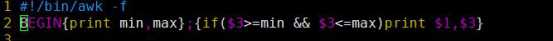
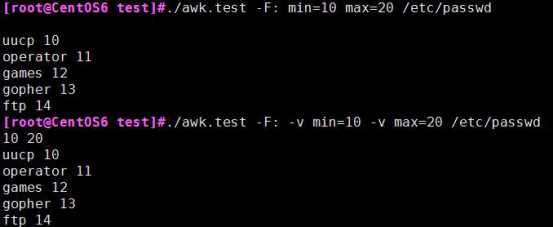
下图:第一条语句未使用-v定义变量,BEGIN输出为空;
以上是关于知识点小结~9的主要内容,如果未能解决你的问题,请参考以下文章