Linux进程基本原理
Posted wang618
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux进程基本原理相关的知识,希望对你有一定的参考价值。
主题进程介绍
一进程相关概念
内核的功用:进程管理、文件系统、网络功能、内存管理、驱动程序、安全功能等
在操作系统上会运行多个应用程序,应用程序分配多大的内存都由内核实现
程序文件
程序和进程的关系
程序是静态文件,进程是动态的
程序如果没有运行那么只是磁盘上的一个文件,只有双击的时候才会在系统上运行,并且操作系统会分配内存空间
在内存里面运行,也就是进程。
而进程会占用CPU和内存空间,运行中的程序的一个副本,因为程序可以开启多个进程。
有些程序是可以运行多个副本的
为了对进程区分,每个进程都有编号的,进程存在生命周期
进程有相关的属性,比如进程是那个用户发起的,也就是UID,还有对应的属主。
注意在国内基本不使用selinux,直接关闭就可以了,而且很多软件的运行和selinx是冲突的,所以在工作中是禁用selinux的
进程和进程会组合成列表
task struct:Linux内核存储进程信息的数据结构格式
task list:多个任务的的task struct组成的链表
每个进程都有自己的表,记录了进程的相关属性
task struct:Linux内核存储进程信息的数据结构格式
链表:
和开发有关的数据结构
进程内存:
Page Frame: 在Linux里面,给进程分配内存空间涉及到了页框,用存储页面数据,存储Page 4k,也就是内存单位。
和磁盘的存储类似,磁盘是块,逻辑卷是PE
给进程分配内存空间的算法:
LRU:Least Recently Used 近期最少使用算法,释放内存
下图是内存空间,由很多的小块组成
假设有数据来了,就会把数据放到第1个小块里面
如果第2块数据来了,那么就会把第1块数据往下压
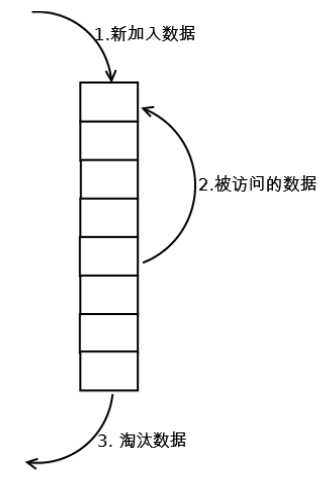
如果第2块数据来了,那么就会把第1块数据往下压
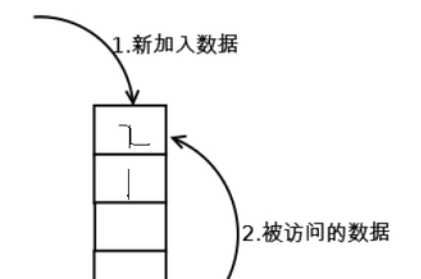
如果第3块数据来了,那么就会把第2块数据往下压
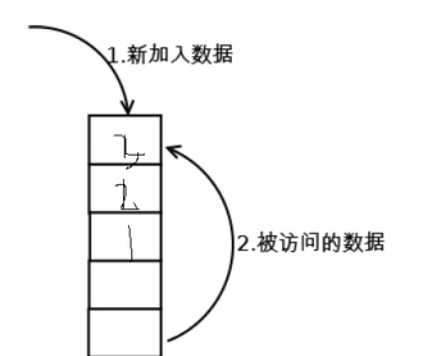
一共可以存放8块数据,如果第9块数据来了
那么就要淘汰第1块数据了
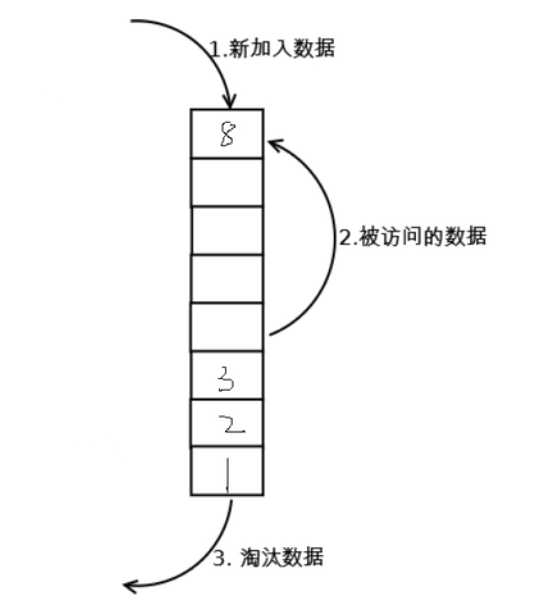
变成了这样的情况:
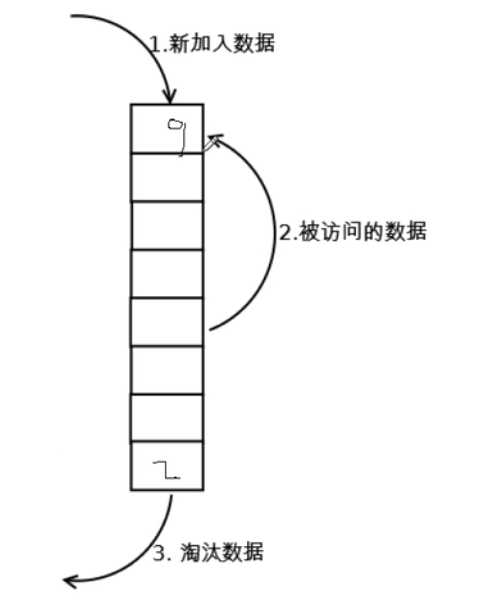
内存空间相当于磁盘来说是小的
假设情况是这样的,用户又要访问第1块数据
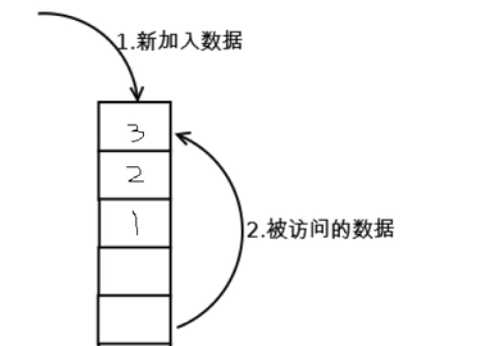
那么就会把第1块数据放到最上面,把其他的数据挤下去
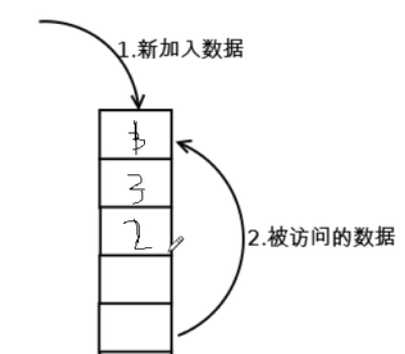
假设访问数据的序列为 4 3 4 2 3 1 4 2
物理块有3个,则
第1轮 4调入内存 4
第2轮 3调入内存 3 4
第3轮 4调入内存 4 3
第4轮 2调入内存 2 4 3
第5轮 3调入内存 3 2 4
第6轮 1调入内存 1 3 2
第7轮 4调入内存 4 1 3
第8轮 2调入内存 2 4 1
上面的访问1次数据就激活的情况,还有一种变种,就是访问两次或者多次的时候才会激活,把下面的数据放到最上面
知道即可。
实际上这种淘汰机制,LRU算法也是缓存的工作机制。
当数据被访问的时候就要放到内存的缓存里面,如果数据被频繁的访问就会一直在缓存里面放着。
这样比去磁盘上访问效率高多了。
如果数据很久都没有被访问,那么就会被淘汰了。
[[email protected] ~]# free total used free shared buff/cache available Mem: 997956 94228 766436 7796 137292 743192 Swap: 2097148 0 2097148
内存给进程分配空间
假设是32位系统,理论上存放的内存空间是2^32,也就是4G内存
应用程序被调到内存里面,他以为拥有4G的所有空间
因为他不知道其他的进程,事实上是操作系统分配了一小块空间。
4G的空间,1G是操作系统用的,3G是内存给应用程序用的
给应用程序分配的空间会对应物理内存空间
对于应用程序来说,他认为自己获得的内存空间的地址是从0开始往后编,实际上对应物理内存的某块空间。
假设内存空间是0——100,其对应物理内存的100——200,就是存在一种映射关系。
上面提到的空间就是物理地址空间和线性地址空间(应用程序眼里的内存空间)
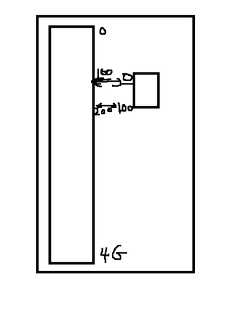
MMU:Memory Management Unit内存管理单元,负责转换线性和物理地址,CPU的硬件设备。
实际上是表格。
TLB:Translation Lookaside Buffer 翻译后备缓冲器,用于保存虚拟地址和物理地址映射关系的缓存
IPC: Inter Process Communication进程间通信
进程认为其拥有整个系统内存,也就是认为只有他一个进程。
实际上有很多进程,那么就涉及到了进程之间的通信。
通信机制:
进程在同一台主机:
1signal:信号,比如发送kill
2shm: shared memory共享内存
在内存空间里面,两个进程独自运行,彼此之间是不知道对方的存在,更不能直接访问对方的数据。
所以要共享进程的数据,就要创建共享内存。
相互之间通信了就把数据写到共享内存里面,从共享内存里面返回数据就可以实现数据的共享了。
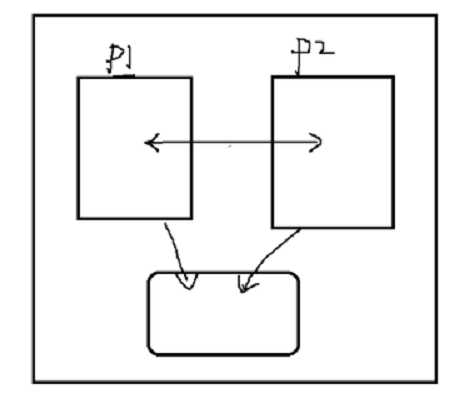
3semaphore:信号量,一种计数器
表示对资源的占用。比如我们买火车票,上面显示有几张票就说明还有票,如果不能点击就说明没有票了。
进程对资源的占用,那么计数器就会显示为0,其他进程就不能访问了。
计数器恢复到1其他进程才可以访问资源。
数据库有此概念。
当一个用户在读取此数据库的表,另外一个用户在修改此表,那么就要进行加锁了。
不同主机:
1socket: IP和端口号
两个应用程序在不同的机器上,那么就要通过socket来标识应用程序的位置。
socket就是IP地址+TCP/UDP端口号
通过IP找到此机器,通过TCP/UDP端口号找到此机器上唯一的程序。因为每个程序使用唯一的端口号。
2RPC: remote procedure call
假设有两台机器,当一台机器在运行过程中急需要通过另外一台机器的进程来继续运行,
那么就会把控制权交给另外一台机器的进程,在另外一台机器运行
那么就调用了另外一台机器的函数,过程等功能。
涉及到开发
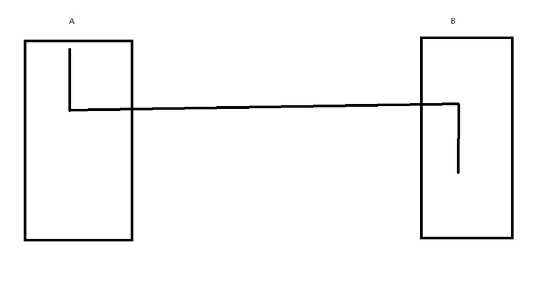
3MQ:消息队列,Kafka,ActiveMQ
两个进程要完成一些业务,互相进行通信,就要把自己的信息发送到消息队列里面
并且就像排队一样,顺序完成
就像我们要去银行办事,会先在机器上打印编号,然后坐着等前面的办好了才可以办事。
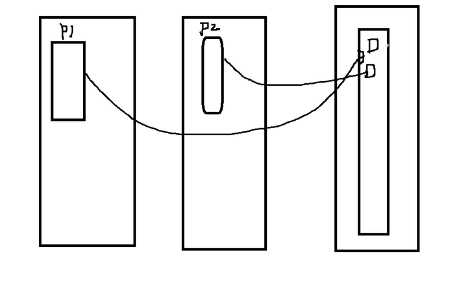
二进程创建
init:第一个进程,和其他进程是父子关系
进程:都由其父进程创建,CoW
fork(), clone()
[[email protected] ~]# pstree init─┬─abrt-dump-oops ├─abrtd ├─acpid ├─atd ├─auditd───auditd ├─automount───4*[automount] ├─crond ├─dbus-daemon───dbus-daemon ├─dnsmasq ├─hald─┬─hald-runner─┬─hald-addon-acpi │ │ └─hald-addon-inpu │ └─hald ├─ksmtuned───sleep ├─libvirtd───10*[libvirtd] ├─master─┬─pickup │ └─qmgr ├─6*[mingetty] ├─rpc.idmapd ├─rpc.mountd ├─rpc.rquotad ├─rpc.statd ├─rpcbind ├─rsyslogd───3*[rsyslogd] ├─sshd───sshd───bash───pstree ├─udevd───2*[udevd] └─xinetd
[[email protected] ~]# pstree systemd─┬─NetworkManager───2*[NetworkManager] ├─VGAuthService ├─agetty ├─auditd───auditd ├─crond ├─dbus-daemon───dbus-daemon ├─master─┬─pickup │ └─qmgr ├─polkitd───5*[polkitd] ├─rsyslogd───2*[rsyslogd] ├─sshd───sshd───bash───pstree ├─systemd-journal ├─systemd-logind ├─systemd-udevd ├─tuned───4*[tuned] └─vmtoolsd───vmtoolsd
cow写时复制:
父进程开启之后,会有对应的PID,假设是1000
父进程开启了一个子进程,假设是2000
如果没有涉及到数据的更改,还是指向到父进程的内存空间
数据更改了才会开辟独立的内存空间,让子进程的进程编号指向新的内存空间
生成子进程会使用到函数fork(), clone()
三进程的基本状态和转换
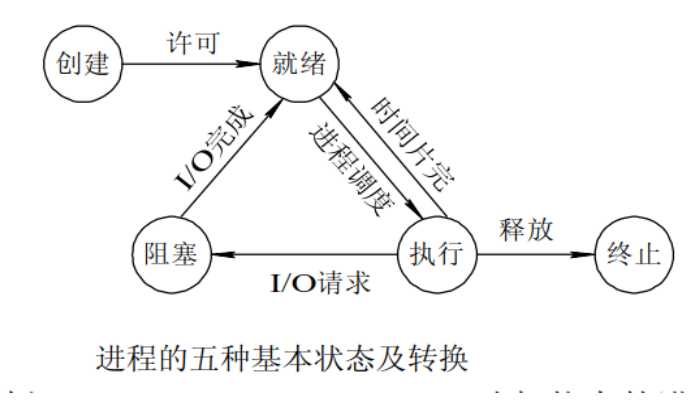
创建状态:进程在创建时需要申请一个空白PCB(processcontrol block进程控制块),
相当于内存空间,向其中填写控制和管理进程的信息,完成资源分配。
如果创建工作无法完成,比如资源无法满足,就无法被调度运行,把此时进程所处状态称为创建状态。
就绪状态:进程已经准备好,已分配到所需资源,只要分配到CPU就能够立即运行。
根据CPU的调度运行,其他进程的资源可以释放,那么CPU就可以让处于就绪的进程运行。
如果进程什么都没有做,占用CPU没有什么意义的。
所以时间片到了之后就会释放。
时间片就是把CPU的运行时间切割成很多小片。
如果时间片到了,但是进程没有执行完,那么就会把当前的状态保留下来。
然后把CPU释放,这样就可以运行其他进程了。达到了时间片有会运行之前还没有运行完的进程。
时间片是几毫秒的,所以我们感觉不到进程在切换,好像很多进程同时运行。
如果遇到了急需要运行的进程,那么即使时间片没到,也会释放其他进程的CPU
CPU就要人一样,同一时间只能做一件事,但是因为切换太快了,所以感觉在做好几件事。
如果CPU是多内核的,那么就像多个人同时做事,比如4核就是4个内核同时做事,这样效率就很高了。
执行状态:进程处于就绪状态被调度后,进程进入执行状态。
阻塞状态:正在执行的进程由于某些事件(I/O请求,申请缓存区失败)而暂时无法运行,进程受到阻塞。
在满足请求时进入就绪状态等待系统调用。
在执行的时候要读取磁盘上的数据,那么就会发送指令给CPU,说要读取磁盘
但是磁盘的运行速度是很慢的,那么CPU的进程就处于就阻塞了,CPU不会阻塞,可以为其他程序服务
I/O结束之后就再次进入到了就绪状态,那么CPU就会再次分配时间片给此进程了。
终止状态:进程结束,或出现错误,或被系统终止,进入终止状态。无法再执行
四进程优先级
如果遇到了急需要运行的进程,那么即使时间片没到,也会释放其他进程的CPU,涉及到了优先级。
进程优先级:
1系统优先级:数字越小,优先级越高
0-139(CentOS4,5)各有140个运行队列和过期队列
0-98,99(CentOS6)
2实时优先级: 99-0 值最大优先级最高
3nice值:-20到19,对应系统优先级100-139或99
假设有2000个进程要运行,并且优先级就不同,理论上要运行优先级最高的进程。
而且要排序才知道那个进程的优先级高。
如果优先级都一样,那么有两种策略,一是先来的先运行,二是轮流执行
有140个优先级就排成140个队列
假设100优先级有好几个进程在运行,比如A,B,C;假设101优先级有好几个进程在运行,比如D,E,F
数字越小,优先级越高,那么就先运行100优先级里面的A进程。
假设A进程要1个小时才可以执行完成,那么A进程运行5毫秒之后,就必须要释放CPU

那么A进程会被迁移到100优先级的队列,但是是过期队列。而之前的100优先级队列是运行队列。
此时运行队列就没有A进程了。
A运行5毫秒之后就轮到B进程运行了,运行了5毫秒之后,B没有执行完就和A进程,被放到过期队列里面了。

以此类推,C进程和A,B一样

现在100优先级的过期队列和运行队列对调
也就是过期队列变成了运行队列,运行队列变成了过期队列。
此时A进程又开始运行了,如果运行5毫秒没有完成,那么就和之前一样,被加入到了过期队列。
100优先级的其他进程也是这样,直到100优先级的所有进程都执行完成了,那么就可以运行101优先级的进程。
和100优先级一样,101也有两个队列,运行队列和过期队列
进程再多也只有140个队列。所以优先级结合队列比较优先级效率更高。
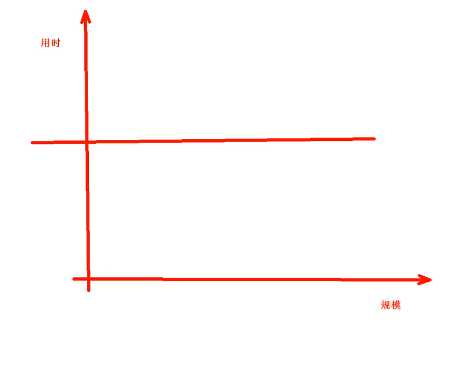
Big O:时间复杂度,用时和规模的关系,一共有下面5种情况:
O(1), O(logn), O(n)线性, O(n^2)抛物线, O(2^n)
比如有1000个进程,就是规模。
不管规模多大花的时间都一样是最好的。对应的是O(1)
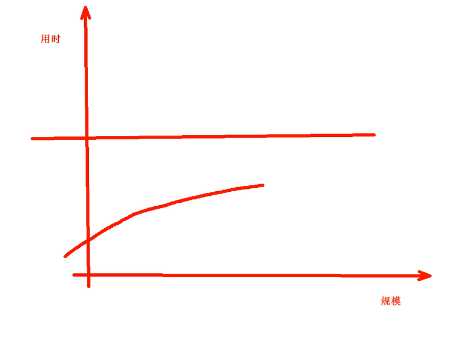
O(logn),增长不是很快,但是会超过恒定值的
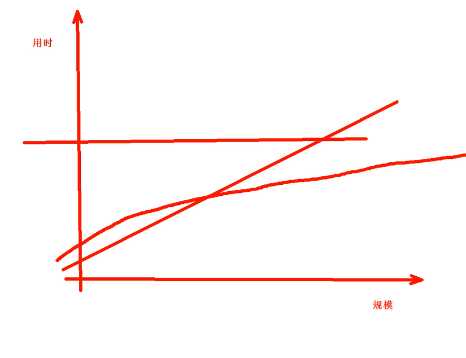
O(n)线性
随着规模越大,花的时间越多
O(n^2)抛物线,比线性上涨的还快
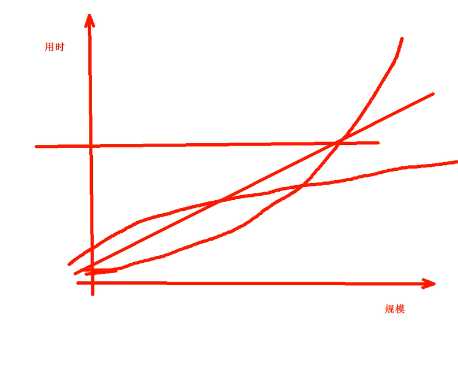
O(2^n)指数型增长
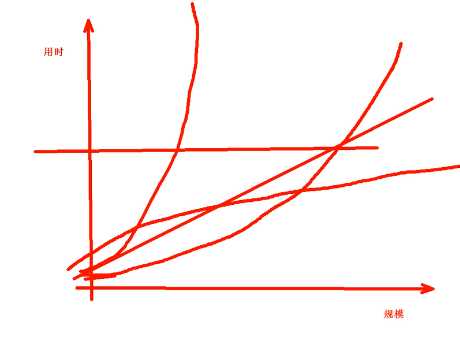
做开发涉及到了很多的算法
优先级
下图显示了4种优先级,分别是系统优先级,实时优先级,nice优先级,top命令的优先级
图片的位置是对应的,比如系统优先级和实时优先级相反,0对应99
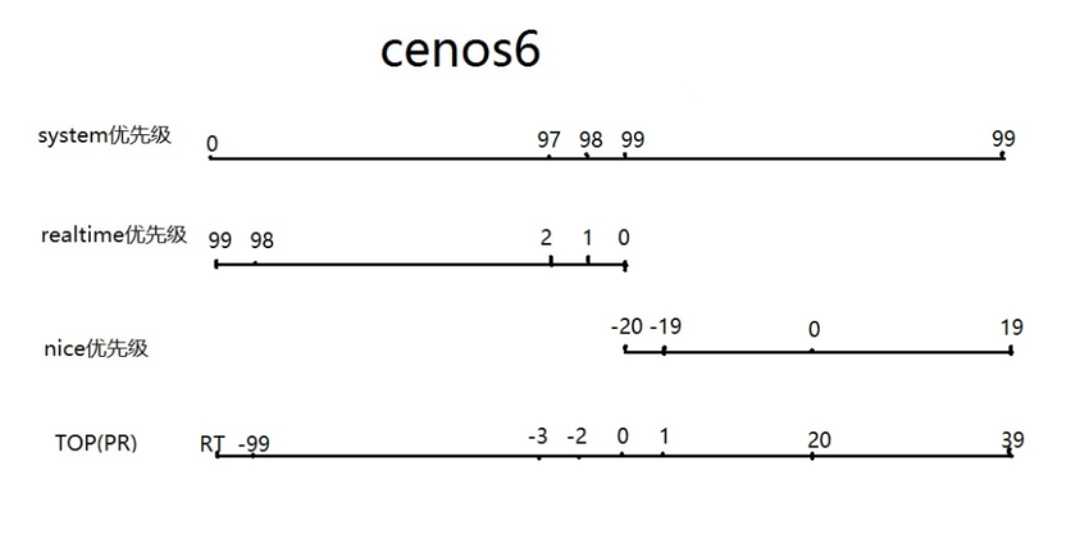
系统优先级:数字越小,优先级越高
0-139(CentOS4,5)
各有140个运行队列和过期队列
0-98,99(CentOS6)
实时优先级: 99-0 值最大优先级最高
nice值:-20到19,对应系统优先级100-139或99
五进程状态
Linux内核:抢占式多任务,也就是计算机是根据时间片分配CPU资源的
进程类型:
守护进程: daemon,在系统引导过程中启动的进程,和终端无关进程
前台进程:跟终端相关,通过终端启动的进程
注意:两者可相互转化
进程状态:
运行态:running
就绪态:ready
睡眠态:
可中断:interruptable
不可中断:uninterruptable
停止态:stopped,暂停于内存,但不会被调度,除非手动启动
僵死态:zombie,结束进程,父进程结束前,子进程不关闭
以上是关于Linux进程基本原理的主要内容,如果未能解决你的问题,请参考以下文章