带你了解清楚索引中的B树和B+树的结构
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了带你了解清楚索引中的B树和B+树的结构相关的知识,希望对你有一定的参考价值。
1 基本概念1 索引 :是特殊数据结构,定义在查找时作为查找条件的字段,在mysql 又称为key ,索引是通过存储引擎来实现的.
优点:索引可以降低服务所需要扫描的数量,减少IO 访问的次数 ,
? 索引可以帮助服务器避免排序和使用临时表,索引可以帮助将随机的IO 转换为顺序IO .
缺点: 占用额外的空间,影响插入的速度.
2 索引的类型
聚簇索引 非聚簇索引 在页节点中数据的存放和索引的存放在一起就是聚簇索引,如果不在一起就是非聚簇索引.myisam 非聚簇索引,innodb聚簇索引.
稠密索引 稀疏索引 是否索引了每一个数据项,如果索引指向的是一个具体数据则是稠密索引,如果索引指向的数据的一个范围就是稀疏索引.
主键索引 二级索引 : 主键本身就是一个索引,按主键顺序来存放数据的顺序,在innodb 中二级索引就是指向主机索引的索引,主键索引本身指向数据,而二级索引指向主键索引 间接的指向数据,
下面来重点 看图
B树结构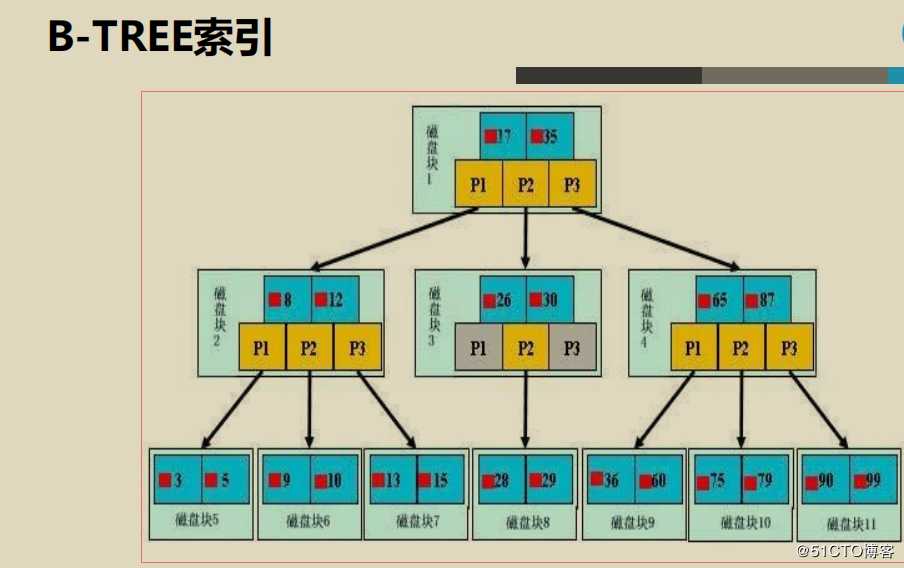
B+树结构
磁盘中存储数据的是以块为单位进行存放的,每个块的大小是固定的,按其逻辑结构可以将数据的存放形式分为三段 ,第一段为根节点 第二段为分支节点 第三段为叶子节点,在一张表中建立了索引就是将表中的某一个或多个字段按逻辑顺序进行了排序,如我们对学生表的学生编号建立了索引,索引的范围是1-30号,在根节点中系统会在范围中取几个编号来存放在根节点中,如取了 10 17编号,则 根节点的指针第一个指向 小于10编号的一个范围指针,第二个指针指向10-17这范围的指针 第三个指针指向了17-30这个范围的指针,通过根节点和分支节点的层层索引就定位到了每一个数据的物理地址上.
B树中 根节点还是分支节点中 不仅存放了稀疏索引还存放了数据,这样在数据块大小是固定的情形下,存放的索引的数量就会较少,特别是在当记录的字段比较多时,此时索引指针的数量就会更少,索引指针的数量少 ,整个树形结构就会层级很多, 每次查找的效率就不会很高,但在B+tree 中树所有的根节点和分支节点都只存放了索引并不存放真正的数据,这样存放的索引就跟多,整个树的层级就会跟少,查找的效率就会更高,
B树种每个页节点都是指向了数据块的物理地址,数据块之间是没有直接联系的,而且数控块和页节点是分离的,这一点也可以从myisam 的文件存放结构可以看出来,myisam 默认就是BTREE结构,当个表 被分别存放在三个文件中,一个文件存放表中的记录数据,一个表存放表的结构,一个表存放表的索引,三项数据都不在一个表上,而 innodb 是B+TREE的结构,他的索引和数据是存放在一张表上的, B+TREE 中在叶子节点上 数据和表是存放在一起的,
而且数据的存放和表的索引存放顺序是完全一致的,数据的存放顺序和表的存放顺便是靠链表来实现的, 这样在对一个范围进行查找时,本来是随机I/0的访问变成了顺便访问,将很大的提高磁盘的访问效率.而Btree 结构对范围查找是无能为力的只能一层层去查找.B+TREE 中根节点和分支节点是不存放数据的,也就是说对单个数据的查找,B+TREE是访问的层级是固定的,
而 BTREE 中是不固定的,本质是因为他的根节点和分支节点上都存放了部分的数据,由于单个数据块中存放的索引指针少,层级多,访问效率是比B+TREE 要低的,但是凡事要辩证的看问题,在B+TREE这种数据和索引在一个起并且数据的存放顺序和索引存放的顺序是一样的这样的结构下,当你插入一条数据的,还插入的在前面的时候时,整个数据的结构被打乱,插入数据所在位置的后面的数据都要重新建立索引和数据,这样无形中大大增加了I/O的访问,因此在设计有大量写操作时,B+TREE的劣势尽显,而BTREE来说对他的影响是比较小.因此我们要根据实际生产来选择.
B树中 根节点还是分支节点中 不仅存放了稀疏索引还存放了数据,这样在数据块大小是固定的情形下,存放的索引的数量就会较少,特别是在当记录的字段比较多时,此时索引指针的数量就会更少,索引指针的数量少 ,整个树形结构就会层级很多, 每次查找的效率就不会很高,但在B+tree 中树所有的根节点和分支节点都只存放了索引并不存放真正的数据,这样存放的索引就跟多,整个树的层级就会跟少,查找的效率就会更高,
B树种每个页节点都是指向了数据块的物理地址,数据块之间是没有直接联系的,而且数控块和页节点是分离的,这一点也可以从myisam 的文件存放结构可以看出来,myisam 默认就是BTREE结构,当个表 被分别存放在三个文件中,一个文件存放表中的记录数据,一个表存放表的结构,一个表存放表的索引,三项数据都不在一个表上,而 innodb 是B+TREE的结构,他的索引和数据是存放在一张表上的, B+TREE 中在叶子节点上 数据和表是存放在一起的,
而且数据的存放和表的索引存放顺序是完全一致的,数据的存放顺序和表的存放顺便是靠链表来实现的, 这样在对一个范围进行查找时,本来是随机I/0的访问变成了顺便访问,将很大的提高磁盘的访问效率.而Btree 结构对范围查找是无能为力的只能一层层去查找.B+TREE 中根节点和分支节点是不存放数据的,也就是说对单个数据的查找,B+TREE是访问的层级是固定的,
而 BTREE 中是不固定的,本质是因为他的根节点和分支节点上都存放了部分的数据,由于单个数据块中存放的索引指针少,层级多,访问效率是比B+TREE 要低的,但是凡事要辩证的看问题,在B+TREE这种数据和索引在一个起并且数据的存放顺序和索引存放的顺序是一样的这样的结构下,当你插入一条数据的,还插入的在前面的时候时,整个数据的结构被打乱,插入数据所在位置的后面的数据都要重新建立索引和数据,这样无形中大大增加了I/O的访问,因此在设计有大量写操作时,B+TREE的劣势尽显,而BTREE来说对他的影响是比较小.因此我们要根据实际生产来选择.
以上是关于带你了解清楚索引中的B树和B+树的结构的主要内容,如果未能解决你的问题,请参考以下文章