salesforce 零基础学习(三十二)通过Streams和DOM方式读写XML
Posted zero.zhang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了salesforce 零基础学习(三十二)通过Streams和DOM方式读写XML相关的知识,希望对你有一定的参考价值。
有的时候我们需要对XML进行读写操作,常用的XML操作主要有Streams和DOM方式。
一.Streams方式
Streams常用到的类主要有两个XmlStreamReader 以及XmlStreamWriter。
XmlStreamReader:此种读取方式的读的特点为从上而下读,下图是根据reader的EventType自上而下的运行步骤。

我们将此xml读取后封装到一个Goods的List中,Goods包括item,name以及type属性,代码如下:
/* * 假定目前XML数据样式为: *<?xml version="1.0"?> *<goodsList> * <goods item="1"> * <name>华为手机</name> * <type>华为</type> * </goods> * <goods item="2"> * <name>小米手机</name> * <type>小米</type> * </goods> *</goodsList> * 需要将xml解析成Goods的一个List */ public class XmlReaderController { public class Goods { public String item{get;set;} public String name{get;set;} public String type{get;set;} } public List<Goods> getGoodsListByXmlFile(String goodsXml) { XmlStreamReader reader = new XmlStreamReader(goodsXml); Boolean flagXmlEnd = true; List<Goods> goodsList = new List<Goods>(); while(flagXmlEnd) { Goods tempGoods; if(reader.getEventType() == XmlTag.START_ELEMENT) { if(reader.getLocalName().equalsIgnoreCase(\'goods\')) { tempGoods = getGoods(reader); } } if(reader.hasNext()) { reader.next(); } else { flagXmlEnd = false; break; } if(tempGoods != null) { goodsList.add(tempGoods); } } return goodsList; } Goods getGoods(XmlStreamReader reader) { Goods tempGoods = new Goods(); tempGoods.item = reader.getAttributeValue(null,\'item\'); Boolean flagIsLoop = true; while(flagIsLoop) { if(reader.hasNext()) { reader.next(); if(reader.getEventType() == XmlTag.START_ELEMENT) { if(reader.getLocalName().equalsIgnoreCase(\'name\')) { reader.next(); tempGoods.name = reader.getText(); } else if(reader.getLocalName().equalsIgnoreCase(\'type\')) { reader.next(); tempGoods.type = reader.getText(); } } if(reader.getEventType() == XmlTag.END_ELEMENT && reader.getLocalName().equalsIgnoreCase(\'goods\')) { flagIsLoop = false; break; } } else { flagIsLoop = false; break; } } return tempGoods; } }
在匿名块测试方法:
String goodsXml = \'<?xml version="1.0"?>\' +
\'<goodsList>\' +
\'<goods item="1">\' +
\'<name>华为手机</name>\' +
\'<type>华为</type>\' +
\'</goods>\' +
\'<goods item="2">\' +
\'<name>小米手机</name>\' +
\'<type>小米</type>\' +
\'</goods>\' +
\'</goodsList>\';
List<XmlReaderController.Goods> goodsList = new XmlReaderController().getGoodsListByXmlFile(goodsXml);
System.debug(JSON.serialize(goodsList));
显示结果:
[
{
"type":"华为",
"name":"华为手机",
"item":"1"
},
{
"type":"小米",
"name":"小米手机",
"item":"2"
}
XmlStreamWriter:处理过程同XmlStreamReader,需要从上到下进行写入,例如如果写出上述的xml文件,需要先startDocument,然后再startElement.....要注意每个start需要对应相应的end方法。
public class XmlWriterController { public static void writeXml() { XmlStreamWriter writer = new XmlStreamWriter(); writer.writeStartDocument(\'utf-8\',\'1.0\'); writer.writeComment(\'goodsList start here\'); writer.writeStartElement(\'\',\'goodsList\',\'http://www.goods.com\'); writer.writeNamespace(\'\', \'http://www.goods.com\'); writer.writeStartElement(null,\'goods\',null); writer.writeAttribute(null,null,\'item\',\'1\'); writer.writeStartElement(null,\'name\',null); writer.writeCharacters(\'华为手机\'); writer.writeEndElement(); writer.writeStartElement(null,\'type\',null); writer.writeCharacters(\'华为\'); writer.writeEndElement(); writer.writeEndElement(); writer.writeStartElement(null,\'goods\',null); writer.writeAttribute(null,null,\'item\',\'2\'); writer.writeStartElement(null,\'name\',null); writer.writeCharacters(\'小米手机\'); writer.writeEndElement(); writer.writeStartElement(null,\'type\',null); writer.writeCharacters(\'小米\'); writer.writeEndElement(); writer.writeEndElement(); writer.writeEndElement(); writer.writeEndDocument(); system.debug(writer.getXmlString()); } }
二.Dom解析
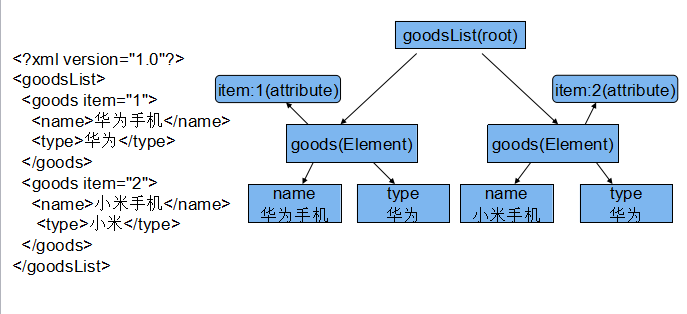
dom解析原理同java对于dom解析相同,这里,goodsList作为根节点,goodsList的子节点有goods1,goods.他们分别有属性item1和item2,goods1以及goods2又分别有相应的子节点。
通过dom方式将上述xml解析成Goods的List。
public class DomXmlController { public class Goods { String item{get;set;} String name{get;set;} String type{get;set;} } public List<Goods> getGoodsViaXmlDom(String xmlString) { Dom.Document document = new Dom.Document(); document.load(xmlString); Dom.XmlNode rootElement = document.getRootElement(); List<Goods> goodsList = new List<Goods>(); for(Dom.XmlNode node : rootElement.getChildElements()) { if(node.getName().equalsIgnoreCase(\'goods\')) { Goods tempGoods = new Goods(); tempGoods = getGoodsNameAndType(node); tempGoods.item = node.getAttribute(\'item\',null); goodsList.add(tempGoods); } } return goodsList; } Goods getGoodsNameAndType(Dom.XmlNode parentNode) { transient Goods tempGoods = new Goods(); for(Dom.XmlNode node : parentNode.getChildElements()) { if(node.getName().equalsIgnoreCase(\'name\')) { tempGoods.name = node.getText(); } else if(node.getName().equalsIgnoreCase(\'type\')) { tempGoods.type = node.getText(); } } return tempGoods; } }
匿名块测试内容如下:
String goodsXml = \'<?xml version="1.0"?>\' +
\'<goodsList>\' +
\'<goods item="1">\' +
\'<name>华为手机</name>\' +
\'<type>华为</type>\' +
\'</goods>\' +
\'<goods item="2">\' +
\'<name>小米手机</name>\' +
\'<type>小米</type>\' +
\'</goods>\' +
\'</goodsList>\';
System.debug(JSON.serialize(new DomXmlController().getGoodsViaXmlDom(goodsXml)));
显示结果:

总结:apex对于xml操作和java很类似,或者说大部分都是从java过来的,如果java解析xml很娴熟情况下,使用apex解析xml只需要看看方法就OK了。本篇只是描述最简单的xml操作,篇中好多方法没有使用到,有兴趣的或者想深入的可以自己看一下相关的api。
以上是关于salesforce 零基础学习(三十二)通过Streams和DOM方式读写XML的主要内容,如果未能解决你的问题,请参考以下文章
salesforce 零基础学习(五十二)Trigger使用篇
salesforce 零基础学习(三十四)动态的Custom Label
salesforce 零基础学习(三十六)通过Process Builder以及Apex代码实现锁定记录( Lock Record)
salesforce 零基础学习(三十一)关于LookUp字段点击Save时的Validation