ElasticSearch中的JVM性能调优
Posted hapjin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch中的JVM性能调优相关的知识,希望对你有一定的参考价值。
ElasticSearch中的JVM性能调优
前一段时间被人问了个问题:在使用ES的过程中有没有做过什么JVM调优措施?
在我搭建ES集群过程中,参照important-settings官方文档来的,并没有对JVM参数做过多的调整。其实谈JVM配置参数,少不了操作系统层面上的一些配置参数,比如 page cache。同时ES进程需要打开大量文件,文件描述符的个数(/etc/security/limits.conf)也要配置得大一些。这里简要介绍一下关于ES JVM参数的配置:
将 xms 和 xmx 设置成一样大 避免JVM堆的动态调整给应用进程带来"不稳定"
预留足够的内存空间给page cache。后面会重点讨论为什么要这么做?
禁用内存交换,后面解释为什么要禁用内存交换?
配置JVM参数:-XX:+AlwaysPreTouch 减少新生代晋升到老年代时停顿。
启动时就把参数里说好了的内存全部舔一遍,可能令得启动时慢上一点,但后面访问时会更流畅,比如页面会连续分配,比如不会在晋升新生代到老生代时才去访问页面使得GC停顿时间加长
-XX:CMSInitiatingOccupancyFraction 设置成75%。主要是因为CMS是并发收集,垃圾回收线程和用户线程同时运行,老年代使用到75%就回收减少OOM异常。
-XX:MaxTenuringThreshold 设置成6。默认Survivor区对象经历15次Young GC后进入老年代,设置成6就只需6次YGC就晋升到老年代了。因为ES新生代采用 -XX:+UseParNewGC,关于这个参数的调优说明,可参考:关键业务系统的JVM参数推荐(2018仲夏版)
Young GC是最大的应用停顿来源,而新生代里GC后存活对象的多少又直接影响停顿的时间,所以如果清楚Young GC的执行频率和应用里大部分临时对象的最长生命周期,可以把它设的更短一点,让其实不是临时对象的新生代对象赶紧晋升到年老代
?
-Xss 配置为1M。线程占用栈内存,默认每条线程为1M。从这个参数可看出一个进程下可创建的线程数量是有限制的,可视为创建线程的开销。
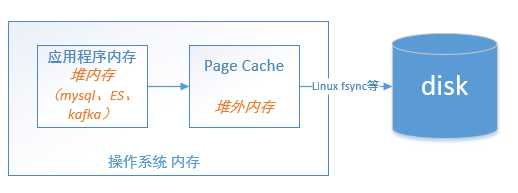
page cache 与 应用程序内存
Linux内存可分成2种类型:Page cache和应用程序内存。应用程序内存会被Linux的swap机制交换出去,而page cache则是由Linux后台的异步flush策略刷盘。当OS内存满了时,就需要把一部分内存数据写入磁盘,因此就需要决定是swap应用程序内存呢?还是清理page cache?OS有个系统参数/proc/sys/vm/swappiness默认值60,一般将之设置成0,表示优先刷新page cache而不是将应用程序的内存交换出去。
那Linux的page cache的清除策略是什么呢?--优化了的LRU算法。LRU存在缺点:那些新读取的但却只使用一次的数据占满了LRU列表,反而把热点数据给evict 到磁盘上去了,因此还需要考虑数据的访问次数(频率)
很多存储系统针对LRU做了一些优化,比如Redis的键过期策略是基于LRU算法的思想,用若干个位记录每个key的idle time(空闲时间),将空闲时间较大的key存入pool,从pool中选择key evict出去,具体可参考:Redis的LRU算法。 再比如mysql innodb 缓冲池管理page也是基于LRU,当新读入一页数据时不是立即放到LRU链表头,而是设置mid point(默认37%),即放到链表37%位置处 。关于如何理解page cache 与应用程序内存之间的区别,可参考这篇文章:从Apache Kafka 重温文件高效读写
Linux总会把系统中还没被应用使用的内存挪来给Page Cache,在命令行输入free,或者cat /proc/meminfo,"Cached"的部分就是Page Cache。
当Linux系统内存不足时,要么就回收page cache,要么就内存交换(swap),而内存交换就有可能把应用程序的数据换出到磁盘上去了,这就有可能造成应用的长时间停顿了。参考:在你的代码之外,服务时延过长的三个追查方向(上)
Linux有个很怪的癖好,当内存不足时,有很大机率不是把用作IO缓存的Page Cache收回,而是把冷的应用内存page out到磁盘上。当这段内存重新要被访问时,再把它重新page in回内存(所谓的主缺页错误),这个过程进程是停顿的。增长缓慢的老生代,池化的堆外内存,都可能被认为是冷内存,用 cat /proc/[pid]/status 看看 VmSwap的大小, 再dstat里看看监控page in发生的时间。
一个JVM长时间停顿的示例
随着系统的运行,JVM堆内存会被使用,引用不可达对象就是垃圾对象,而操作系统有可能会把这些垃圾对象交换到磁盘上去。当JVM堆使用到一定程度时,触发FullGC,FullGC过程中发现这些未引用的对象都被交换到磁盘上去了,于是JVM垃圾回收进程得把它们重新读回来到内存中,然而戏剧性的是:这些未引用的对象本身就是垃圾,读到内存中的目的是回收被丢弃它们!而这种来回读取磁盘的操作导致了FullGC 消耗了大量时间,(有可能)发生长时间的stop the world。因此,需要禁用内存交换以避免这种现象,这也是为什么在部署Kafka和ES的机器上都应该要禁用内存交换的原因吧。具体可参考这篇文章:Just say no to swapping!
总结
本文以ES使用的JVM配置参数为示例,记录了一些关于JVM调优的参数理解,以及涉及到的一些关于page cache、应用程序内存区别,LRU算法思想等,它们在Mysql、Kafka、ElasticSearch都有所应用。文中给出的参考链接都非常好,对深入理解系统底层运行原理有帮助。
原文:https://www.cnblogs.com/hapjin/p/11135187.html
以上是关于ElasticSearch中的JVM性能调优的主要内容,如果未能解决你的问题,请参考以下文章