降维与度量学习
Posted xmd-home
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了降维与度量学习相关的知识,希望对你有一定的参考价值。
?
降维与度量学习
K近邻学习
K近邻学习(k-Nearest Neighbor)学习是一种常用的监督学习方法,其工作机制非常简单:给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于这k个"邻居"的信息来进行预测。通常,在分类任务中可使用"投票法",即选择这k个样本中出现最多的类别标记作为预测结果;在回归任务中可使用"平均法",即将这k个样本的实值输出标记的平均值作为预测结果;还可以基于距离远近进行加权平均或加权投票,距离越近的样本权重越大。
K近邻学习属于"懒惰学习"的一种,它在训练阶段仅仅把样本保存起来,训练时间开销为零,待收到测试样本后再进行处理;相对应的,再训练阶段就对样本进行学习处理的方法,成为"急切学习"。
低维嵌入
k近邻学习基于一个重要假设:任意测试样本附近人意小的距离范围内总能找到一个训练样本,即训练样本的密度足够大,或称为"密采样"。然而,这个假设在现实任务中通常很难满足,例如,如果,仅考虑单个属性,则仅需1000个样本点平均分布在归一化后的属性取值范围,即可使得任意测试样本在其附近0.001距离范围内总能找到一个训练样本。然而,这是在维度为1 的时候,如果有更多的属性,则情况会发生显著的变化。现实应用中属性维度经常成千上万,要满足密采样条件,则需要很多的样本数,几乎是无法达到的天文数字;此外,很多学习方法涉及到距离计算,而高维空间给距离计算带来很大的麻烦,例如当维度很高的时候甚至连计算内积都不容易。
事实上,在高维情形下出现的样本稀疏、距离计算困难等问题,是所有机器学习方法共同面临的严重障碍,被称为"维数灾难"。
缓解维数灾难的一个重要途径是降维,"维数约简",即通过某种数学变换将原始高维属性空间转变为一个低维"子空间",这个字空间中样本密度大幅提高,距离计算也变得更加容易。
PCA
? mouse1
2
3
4
5
6
gene1
10
11
8
3
2
1
gene2
6
5
4
3
2.8
1
gene3
12
9
10
2.5
1.3
2
4 or more dimensions of data, and make 2 dimensional plot.
We‘ll also talk about how PCA can tell us which gene (or variable) is the most valuable for clustering the data.
1)绘制二维的数据,然后将数据中心点移到原点;
2)找出最佳的拟合直线:投影点到原点的距离和最大,或者点到投影直线间的距离最小。
3)这里的曲线的斜率可以表明,这两个基因之间的关系;对曲线进行缩放,找到其中的一个单元大小。这里的1个单元由两个部分组成,0.97的基因1和0.242的基因2。这两个值,称为"singular vector"或者是PC1的特征向量;投影点到原点的距离和称之为PC1的特征向量;开根号后称之为Singular Value for PC1;
4)PC2和PC1垂直perpendicular;-0.242的基因1和0.97的基因2;
5)convert the ss into variation around the origin(0,0) by dividing by the sample size minus 1.
PC1的variation = 15; PC2的variation=3;
总的variation = 18;
可以解释 PC1 占比83%;每个PC的variation;
?
PCA-practial tips:
主要讲以下三个方面的内容:
1)Scaling your data;
2)Centering your data;
3)How many principal components you should expect to get.
1. 数据的归一化;
2. 数据中心要过原点;
3. 多少个主成分需要被找到;
?
PCA的使用:
1.如何得到可以运用PCA的数据;
2.如何使用sklearn中的PCA进行主成分分析
3.如何决定每个主成分所占的变化比例;
4.如何使用matplotlib绘制PCA
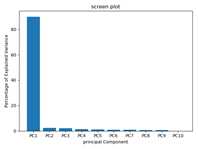
几乎所有的variation都聚集在第一个pc上,因此,使用PC1和PC2可以很好的表示数据。
在一个正交属性空间中,如何使用一个超平面(直线的高维推广)对所有样本进行恰当的表达?
容易想到,这个超平面应该具有这样的性质:
1)最近重构性:样本点到这个超平面的距离足够近;
2)最大可分性:样本点在这个超平面上的投影尽可能分开。
基于最近重构性和最大可分性可以得到两种等价推导:
1)基于最近重构性的推导:
假定数据样本进行了中心化,即;再假定投影变换后得到的新坐标系为,其中是标准正交向量,,。若丢弃新坐标系中的部分坐标,即将维度降低到,则样本点在低维坐标系中的投影是,其中是在低维坐标系下第j维的坐标。若基于来重构,则会得到.
以下内容参考:http://blog.codinglabs.org/articles/pca-tutorial.html
为什么基的模为1?
A?B=|A||B|cos(a)
如果|B|=1,则直接为A在B上的投影。
故,利用内积可以表示一个向量在某个基下的坐标表示。
一般的,如果我们有M个N维向量,想将其变换为由R个N维向量表示的新空间中,那么首先将R个基按行组成矩阵A,然后将向量按列组成矩阵B,那么两矩阵的乘积AB就是变换结果,其中AB的第m列为A中第m列变换后的结果。
其中pi是一个行向量,表示第i个基,aj是一个列向量,表示第j个原始数据记录。
特别要注意的是,这里R可以小于N,而R决定了变换后数据的维数。也就是说,我们可以将一N维数据变换到更低维度的空间中去,变换后的维度取决于基的数量。因此这种矩阵相乘的表示也可以表示降维变换。
最后,上述分析同时给矩阵相乘找到了一种物理解释:两个矩阵相乘的意义是将右边矩阵中的每一列列向量变换到左边矩阵中每一行行向量为基所表示的空间中去。更抽象的说,一个矩阵可以表示一种线性变换。很多同学在学线性代数时对矩阵相乘的方法感到奇怪,但是如果明白了矩阵相乘的物理意义,其合理性就一目了然了。
协方差矩阵和其优化目标
我们希望投影后投影值尽可能分散,而这种分散程度,可以用数学上的方差来表述。此外,一个字段的方差可以看作是每个元素与字段均值的差的平方和的均值,即
由于上步已经将每个字段的均值都化为0了,那么方差就可以直接用每个元素的平方和除以元素个数表示:
于是,上述问题被形式化表示为:寻找一个一维基,使得所有数据变换为这个基上的坐标表示后,方差值最大。
协方差:
对于上面的二维降成一维的问题来说,找到那个使得方差最大的方向就可以了。但是对于更高维,还有一个问题需要解决。
数学上采用协方差来表示其相关性,由于让每个字段均值都为0:
可以看到,在字段均值为0的情况下,两个字段的协方差简洁的表示为其内积处以元素m.
至此,我们得到了降维问题的优化目标:将一组N维向量降为K维(K大于0,小于N),其目标是选择K个单位(模为1)正交基,使得原始数据变换到这组基上后,各字段两两间协方差为0,而字段的方差则尽可能大(在正交的约束下,取最大的K个方差)。
协方差矩阵:
假设我们只有a和b两个字段,那么我们将他们按行组成矩阵X:
然后我们用X乘以X的转置,并乘上系数1/m:
这个矩阵对角线上的两个元素分别是两个字段的方差,而其他元素是a和b的协方差,两者被统一到了一个矩阵中。
根据矩阵相乘的运算法则,这个结论很容易被推广到一般情况:
设我们有m个n维数据记录,将其排列为n乘m的矩阵x,设C=,则C是一个对称矩阵,其对角线分别是各个字段的方差,而第i行和第j列元素相同,表示i和j两个字段的协方差。
协方差矩阵对角化
根据上述推导,我们发现要达到优化目前,等价于将协方差矩阵对角化:即除对角线外的其他元素化为0,并且在对角线上将元素按从小到大从上到下排列,这样我们就达到了优化的目的。
设原始数据矩阵X对应的协方差矩阵为C,而P是一组基按行组成的矩阵,设Y=PX,则Y为X对P做基变换后的数据。设Y的协方差矩阵为D,推导D和C的关系:
现在的目标变成,需要找到P,能让D为协方差矩阵对角化的P。
换言之,优化目标变成了寻找一个矩阵P,满足是一个对角矩阵,并且对角元素按从大到小依次排列,那么P的前K行就是要寻找的基,用P的前K行组成的矩阵乘以X就使得X从N维降到了K维并满足上述优化条件。
由上文可知,协方差矩阵C是一个对称矩阵,在线性代数上,实对称矩阵有一系列非常好的性质:
1)实对称矩阵不同特征值对应的特征向量必然正交;
2)设特征向量重数为r,则必然存在r个线性无关的特征向量对应于,设这n个特征向量为,将其按列组成矩阵,
则对协方差矩阵C有如下结论:
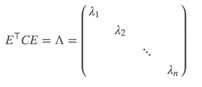
根据上面对PCA的数学原理的解释,我们可以了解到一些PCA的能力和限制。PCA本质上是将方差最大的方向作为主要特征,并且在各个正交方向上将数据"离相关",也就是让它们在不同正交方向上没有相关性。
因此,PCA也存在一些限制,例如它可以很好的解除线性相关,但是对于高阶相关性就没有办法了,对于存在高阶相关性的数据,可以考虑Kernel PCA,通过Kernel函数将非线性相关转为线性相关,关于这点就不展开讨论了。另外,PCA假设数据各主特征是分布在正交方向上,如果在非正交方向上存在几个方差较大的方向,PCA的效果就大打折扣了。
最后需要说明的是,PCA是一种无参数技术,也就是说面对同样的数据,如果不考虑清洗,谁来做结果都一样,没有主观参数的介入,所以PCA便于通用实现,但是本身无法个性化的优化。
核化线性降维
流形学习
等度量映射
局部线性嵌
?
Multiple dimensional scaling (MDS)
若要求原始空间中样本之间的距离在低维空间中得以保持,即"多维缩放",一种经典的降维方法。
假定m个样本在原始空间中的距离矩阵为,其中第i 行j列元素为样本到样本的距离。我们的目的就是获得样本在d‘维空间的表示,,且任意两个样本在维空间中的欧式距离等于原始空间中的距离,即。
令,其中B为降维后样本的内积矩阵,
对B矩阵进行特征值分解,,其中,为特征值构成的对角矩阵。V为特征向量矩阵。
假定有个非零特征值,它们构成对角矩阵,令表示相应的特征向量矩阵,则Z可表达为:
在现实应用中,为了有效降维,往往仅需降维后的距离与原始空间中的距离尽可能接近,而不必严格相等。此时,可取个最大特征值构成对角矩阵
度量学习
以上是关于降维与度量学习的主要内容,如果未能解决你的问题,请参考以下文章