人工智能08 启发式搜索
Posted cccccz
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了人工智能08 启发式搜索相关的知识,希望对你有一定的参考价值。
启发式搜索
【这一章在某些地方笔者自己也没完全弄清楚,比如在递归最优搜索处没有找到一个很好的例子来理解,比如如何选择启发式函数等等一系列的问题,希望有大神能指明讲解。所以本章重要的只是介绍A*算法流程和简单优化并介绍引出一些改进的A*
使用评估函数
除了搜索过程不是从开始节点统一向外扩展外,本章描述的搜索过程有点像广度优先搜索,不同的是,它会优先顺着有启发性和具有特定信息的节点搜索下去,这些节点可能是到达目标的最好路径。我们称这个过程为最优(best-first)或启发式搜索。下面是其基本思想。


我们常常可以为最优搜索制定好评估函数。如在8数码问题中,可以用不正确位置的数字个数作为状态描述好坏的一个度量,将这个标准应用于8数码问题中。如下图所示。
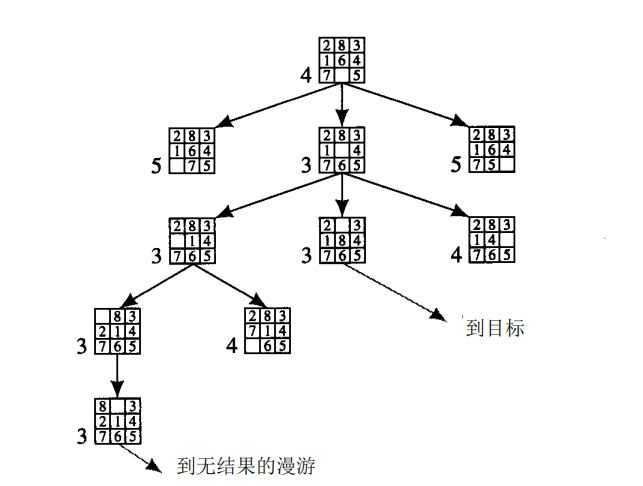



下,可以看到搜索相当直接的朝着目标进行。
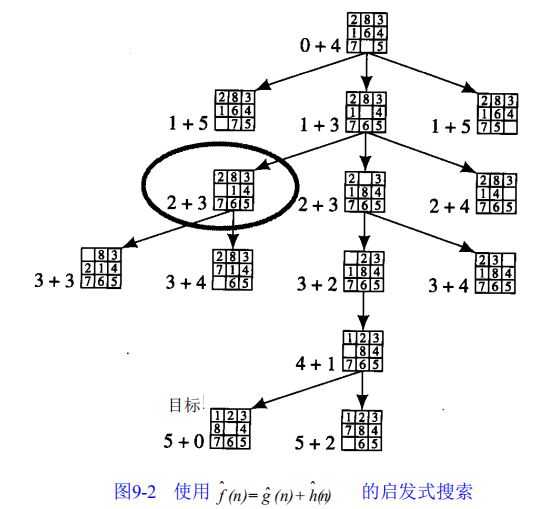

这个例子提出了两个重要的问题。
-
我们如何为最优搜索决定评估函数?
-
最优搜索的特性是什么?他能找到到达目标节点的好路径么?
一个通用的图搜索算法
为了更准确地解释本章的启发式搜索过程,这里提出一个通用的图搜索算法,它允许各种用户,进行定制。我们把这个算法叫做图搜索。下面是它的定义:


这个算法可以用开执行最优搜索、广度优先搜索或深度优先搜索。在广度优先搜索中,新节点只要放在OPEN的尾部即可(先进先出,FIFO),节点不用重排。在深度优先搜索中,新节点放在OPEN的开始(后进后处,LIFO)。在最优(启发式)搜索中,按节点的启发式方法来重排OPEN。
1. 算法A*


因为动作是可逆的,即任何节点n的每一个后继都可以使n作为它的一个后继。在建立8数码搜索树中忽略了这些循环。因此我们将算法的第六步改为:
![]()




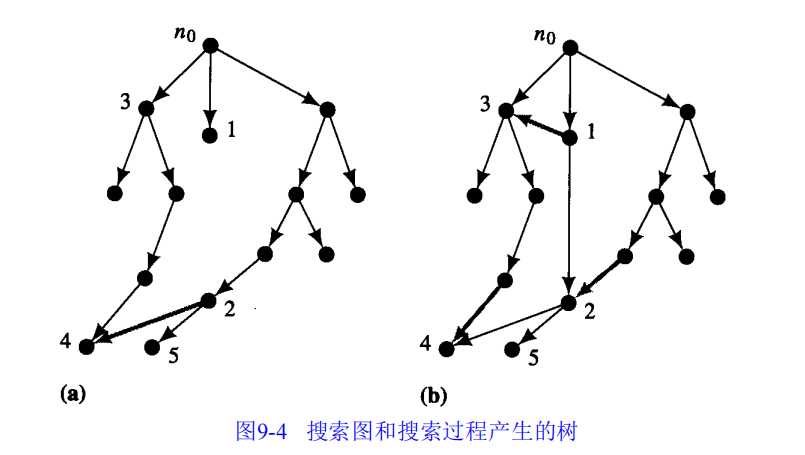
则最后完整的A*算法如下:


2. 迭代加深的A*
在上一章,讲过广度优先搜索的存储需求会随着搜索空间中目标深度的增加呈指数递增。尽管好的启发式搜索减少了分支因子,但启发式搜索还是有如一样的缺点。在上一章中介绍的迭代加深搜索,不但允许我们找到最小代价路径,而且存储需求随着深度增加呈线性增长。由此提出的迭代加深A*(IDA*)方法能获得同启发式搜索相似的好处。通过使用IDA*算法并行实现能获得更高的效率。


3. 递归最优搜索
【此处笔者也没看懂,希望大牛能给出一些实例进行讲解,这里直接将网上找到的资料原文po出来,希望有大神指点!】

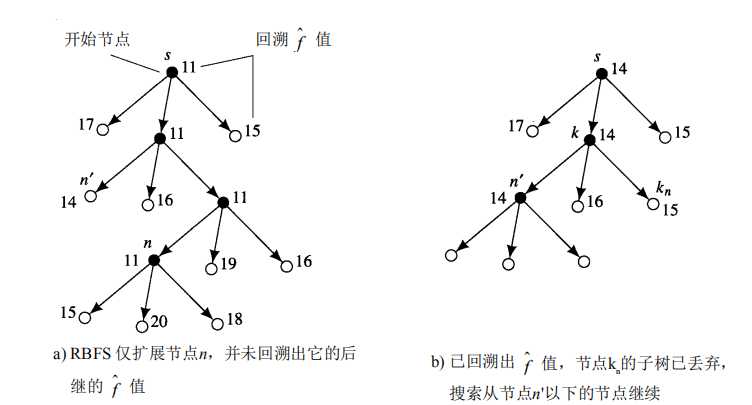


启发式函数和搜索效率
搜索效率的一个度量是有效分支因子B,他描述了一个搜索过程朝着目标前进的激烈程度。假设搜索找到了一个长为d的路径,生成了N个节点,那么B就是有以下属性的树上每个节点的后继个数。
-
数中每个非树叶节点都有B个后继
-
数中的树叶节点的深度均为d
-
数中的节点总数是N
因此,B和路径长度d以及生成的总结点数N之间有下列关系:
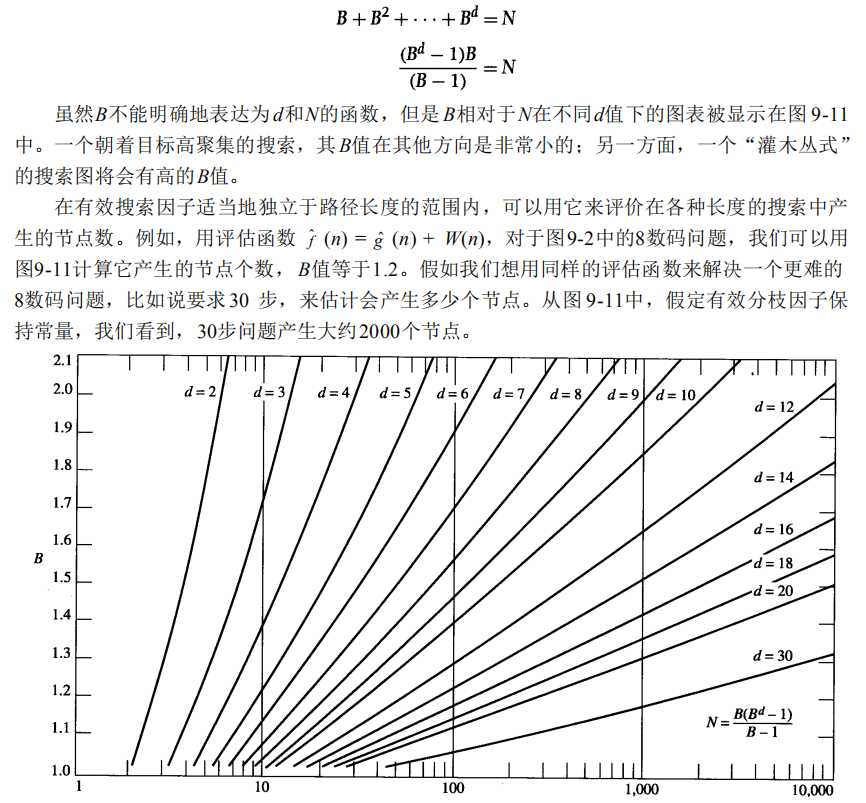

归纳一下,有三个重要因素影响算法A*的效率:
-
被发现的路径的代价(长度)
-
在发现路径中被扩展的节点数
-
计算h估计的计算量
选择适当的启发式函数可以让我们平衡这些因素以最大化搜索效率。
以上是关于人工智能08 启发式搜索的主要内容,如果未能解决你的问题,请参考以下文章