虎书_褚论
Posted binarysystemloophole
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了虎书_褚论相关的知识,希望对你有一定的参考价值。
褚论
- 对于任何大型软件系统,如果设计者注意到该系统的基本抽象和接口,那么对这个系统的实现和理解就要容易的多。
- 下图,展示了一个典型的编译器的各个阶段,每个阶段由一至多个软件模块来实现。将编译器分解成这样多个阶段是为了能够重用他的各种构件。例如,要改变此编译器所生成的机器语言的目标机时,只要改变栈帧布局模块和指令选择模块。当要改变被编译的源语言的时候,只需要改变翻译模块之前的模块就可以了,该编译器也可以在抽象语法接口处与面向语言的语法编辑器相连。
- 抽象语法、IR树、汇编之类的接口是数据结构的形式,例如语法分析动作阶段建立抽象语法数据结构,并将它传递给语义分析阶段。另一些接口是抽象数据类型:翻译接口是一组可由语义分析阶段调用的函数;单词符号接口是函数形式,分析器通过调用它而得到输入程序中下一个单词符号。
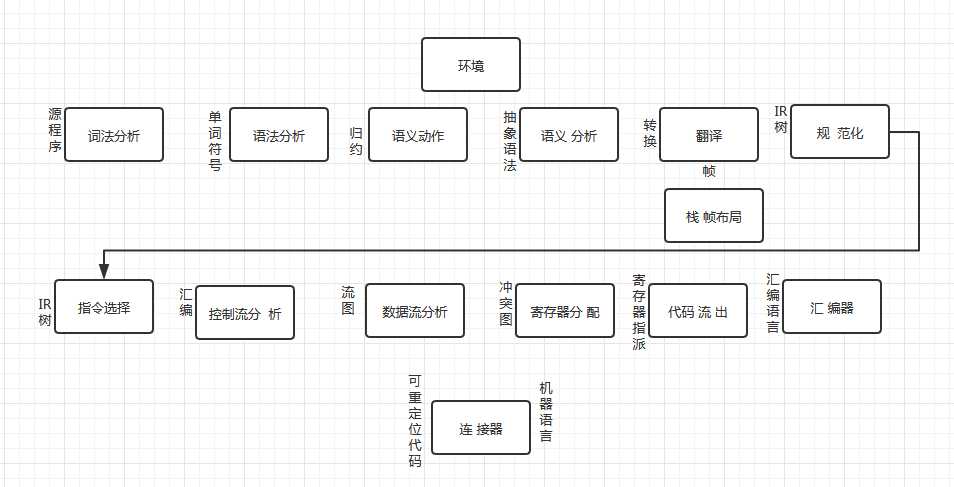
各个阶段的描述
| 阶段 | 描述 |
|---|---|
| 词法分析 | 将原文件分解成一个个独立的单词符号 |
| 语法分析 | 分析程序的短语结构 |
| 语义动作 | 建立每个短语对应的抽象语法树 |
| 语义分析 | 确定每个短语的含义,建立变量和其声明的关联。检查每个表达式的类型,翻译每个短语 |
| 栈帧布局 | 按机器要求的方式将变量、函数参数等分配于活跃记录 |
| 翻译 | 生成中间表示树(IR树)这是一种与任意特定程序设计语言和目标机体系结构无关的表示 |
| 规范化 | 提取表达式中的副作用,整理条件分支,方便下一阶段的处理 |
| 指令选择 | 将IR树节点组合成,与目标机指令动作相对应的块 |
| 控制流分析 | 分析指令顺序,并建立控制流图,此图表示程序执行时可能流经的所有控制流 |
| 数据流分析 | 收集程序变量和数据流信息,例如活跃分析,计算每一个变量仍需使用其值的地点(即他的活跃点) |
| 寄存器分配 | 为程序的每一个变量和临时数据选择一个寄存器,不在同一时间活跃的两个变量可以共享一个寄存器 |
| 代码流出 | 用机器寄存器代替每一条机器指令中出现的临时变量名 |
工具和软件
现代编译器使用两种最有用的抽象是上下文无关文法和正则表达式。上下文无关文法用于语法分析,正则表达式用于词法分析。为了更好的利用这两种抽象较好的做法是借助一些专门的工具,例如YACC,他将文法转换成语法分析器和LEX他将一个说明性质的规范转换成一个词法分析器。
树语言的数据结构
- 编译器中使用许多重要的数据结构都是被编译程序的中间表示。这些表示,常常采用树的形式,树的节点有若干种类型,每一种类型都有一些不同的属性。
树可以用文法来描述,就向程序设计语言一样。这里给出一种简单的程序设计语言,该程序设计语言有语句和表达式,但是没有循环或if语句,这种语言称为直线式程语言

- 这个语言的非形式语义如下。每一个Stm是一个语句,每一个Exp是一个表达式。s1;s2表示先执行s1,在执行语句s2。i:=e表示先计算表达式e的值,然后把计算结果复制给变量i。
- print(e1,e2,...,en)表示从左到右输出所有表达式的值,这些值之间用空分开,并以换行符结束。
- 表示符表达式,例如i,表示变量i当前内容。数按命名他的整数计值。操作符表达式e1 op e2,表示先计算e1在计算e2,然后按给定的二元操作符计算表达式结果。表达式序列(s,e)的行为类似c语言的逗号操作符,在计算表达式e(并返回其结果)之前先计算语句的s副作用。
- 例如,执行下面的这段程序
a:=5+3;b:=(print(a,a-1).10*a);print(b);打印出8、7、80
程序在编译器内部的表现
一种是源码形式,是程序员所编写的字符,但是这种表示不易处理。较为方便的表示是树数据结构,每一个语句(Stm)和每一个表达式(Exp)都有一个树节点,如下图给出了树表示,其中每个节点产生式的标识加以标记,并且每个子节点的数量与相应的文法产生式右边的符号个数相同。
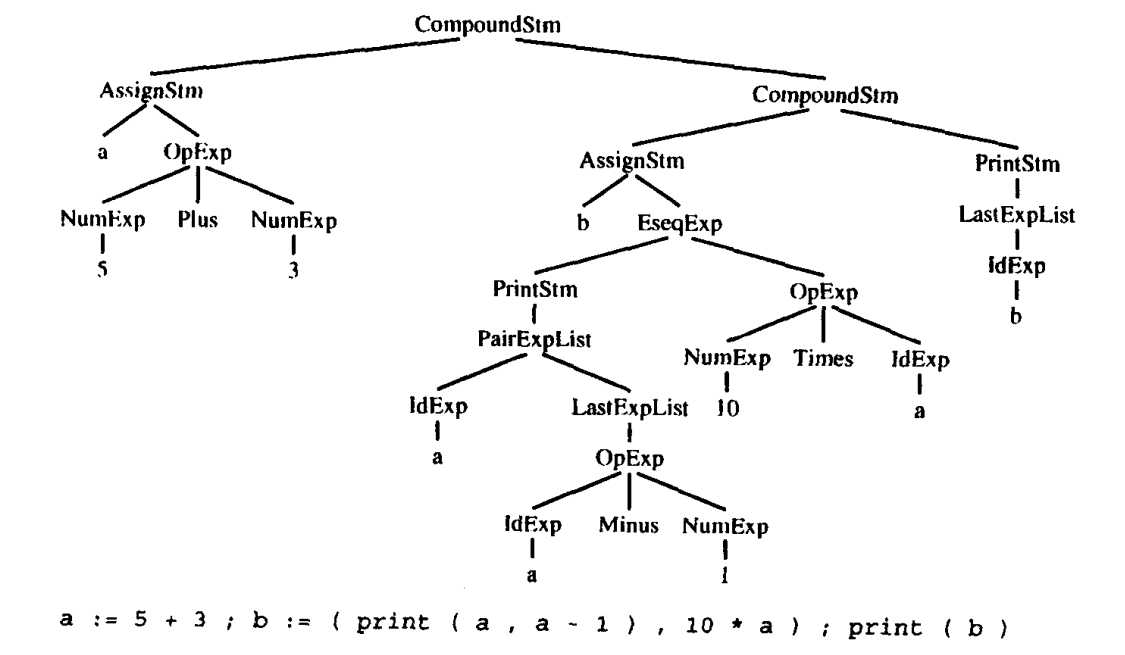
我们可以将这个文法直接翻译成数据结构定义,每个文法符号对应这些结构中的一个typedef


- 每一项文法规则都有一个构造器,隶属于规则左部符号的联合。
- 每一项文法规则有若干右部成分,这些成分必须用数据结构来表示。例如,CompoundStm的右部有两个Stm;AssignStm有一个标识符和一个表达式。表示每一个文法符号的结构都含有一个联合和kind域,前者用于存放可选的成分值,后者执行用联合的哪一个成员。
- 对于每一个选择,我们创建一个构造函数,他用malloc为此数据结构分配空间并进行初始化,上图只给了这些函数的原型,A_CompoundStm可以这样定义
A_stm A_CompoundStm(A_stm stm1,A_stm stm2)
A_stm s=checked_malloc(sizeof(*s));
s->kind=A_CompoundStm;
s->u.compound.stm1=stm1;s->u.compound.stm2=stm2;
return s;
二元操作符的情景要简单些(Binop),尽管也可以为Binop创建一个结构(成员分别表示Plus、Minus、Times、Div),但这样是多余的,因为这些成员并不存放数据,我们为他定义一个枚举类型A_binop
程序设计风格
- 在用c表示树数据结构时,遵循以下一些约定。
- 树都用文法来描述
- 一棵树使用一至多个typedef来描述,每个Typedef对应文法中的一个符号
- 每个typedef定义一个指向相应struct的指针,这个struct的名字以下划线结束,他除了在typedef的声明和该结构体的定义中出现,绝不会在其他地方使用。
- 每个struct有一个kind域和一个u域,kind指明不同选择的枚举量,每个枚举值对应一个可选的文法规则,u是一个联合。
- 如果一个规则的右部有多个非凡的符号(即带有值的),则他的union有一个本身也是结构的成员给出的组成他的这些值。
- 如果一个规则的右部只有一个非凡的符号,则他的union有一个就是其值的成员
- 每个类有一个对所有成员进行初始化的构造函数,除了在构造函数,其他地方不会直接调用malloc函数
- 每一个模块(头文件)有一个唯一标识该模块的前缀
类型定义名(位于前缀之后的)应用小写字母开头,构造函数名,用大写字母开头,联合的成员用小写字母开头
c程序模块化规则
- 编译器是一个很大的程序,自己的设计模块和接口能避免混乱,在用c编写一个编译器时,我们将使用以下规则
- 编译器每个 模块或模块都应归入各自的“.c”文件,且该文件有对应的“.h”文件。
- 每个模块有该模块唯一的前缀。由此模块导出的全局名字都应以此前缀打头
- 所有的函数都应该有函数原型,如果使用了没有原型的函数,编译器将给出警告。
- string类型表示分配在堆中的字符串,这种字符串在初次创建之后便不会在改变。函数string从c风格字符串指针创建一个分配在堆中的字符串string
- malloc函数在无内存空间的时候会返回null,Tiger编译器没有复杂的内存管理,来处理。他不调用malloc而调用checked_malloc这个函数保证不会返回null
也不调用free
程序设计:直线式程序解释器
- 为直线程序设计语言实现一个简单的程序分析器和解释器,对环境(符号表,他将变量名映射到这些变量相关的信息)、抽象语法(表示程序的短语结构的数据结构)、树数据结构的递归性(他对于编译器中很对部分都是很有用的)以及无赋值语句的函数式风格程序设计。
编写没有副作用(即更新变量及数据结构的赋值语句)的解释器是理解指语义和属性文法的好方法,后两者都是描述程序设计语言做什么方法。
以上是关于虎书_褚论的主要内容,如果未能解决你的问题,请参考以下文章