LightGBM,面试会问到的都在这了(附代码)!
Posted mantch
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LightGBM,面试会问到的都在这了(附代码)!相关的知识,希望对你有一定的参考价值。
1. LightGBM是什么东东
不久前微软DMTK(分布式机器学习工具包)团队在GitHub上开源了性能超越其他boosting工具的LightGBM,在三天之内GitHub上被star了1000次,fork了200次。知乎上有近千人关注“如何看待微软开源的LightGBM?”问题,被评价为“速度惊人”,“非常有启发”,“支持分布式”,“代码清晰易懂”,“占用内存小”等。
LightGBM (Light Gradient Boosting Machine)(请点击https://github.com/Microsoft/LightGBM)是一个实现GBDT算法的框架,支持高效率的并行训练。
LightGBM在Higgs数据集上LightGBM比XGBoost快将近10倍,内存占用率大约为XGBoost的1/6,并且准确率也有提升。GBDT在每一次迭代的时候,都需要遍历整个训练数据多次。如果把整个训练数据装进内存则会限制训练数据的大小;如果不装进内存,反复地读写训练数据又会消耗非常大的时间。尤其面对工业级海量的数据,普通的GBDT算法是不能满足其需求的。
LightGBM提出的主要原因就是为了解决GBDT在海量数据遇到的问题,让GBDT可以更好更快地用于工业实践。
1.1 LightGBM在哪些地方进行了优化 (区别XGBoost)?
- 基于Histogram的决策树算法
- 带深度限制的Leaf-wise的叶子生长策略
- 直方图做差加速直接
- 支持类别特征(Categorical Feature)
- Cache命中率优化
- 基于直方图的稀疏特征优化多线程优化。

1.2 Histogram算法
直方图算法的基本思想是先把连续的浮点特征值离散化成k个整数(其实又是分桶的思想,而这些桶称为bin,比如[0,0.1)→0, [0.1,0.3)→1),同时构造一个宽度为k的直方图。
在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。
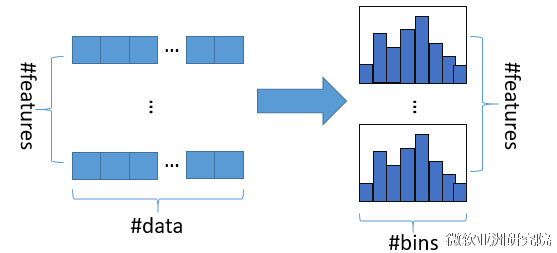
使用直方图算法有很多优点。首先,最明显就是内存消耗的降低,直方图算法不仅不需要额外存储预排序的结果,而且可以只保存特征离散化后的值,而这个值一般用8位整型存储就足够了,内存消耗可以降低为原来的1/8。然后在计算上的代价也大幅降低,预排序算法每遍历一个特征值就需要计算一次分裂的增益,而直方图算法只需要计算k次(k可以认为是常数),时间复杂度从O(#data#feature)优化到O(k#features)。
1.3 带深度限制的Leaf-wise的叶子生长策略
在XGBoost中,树是按层生长的,称为Level-wise tree growth,同一层的所有节点都做分裂,最后剪枝,如下图所示:
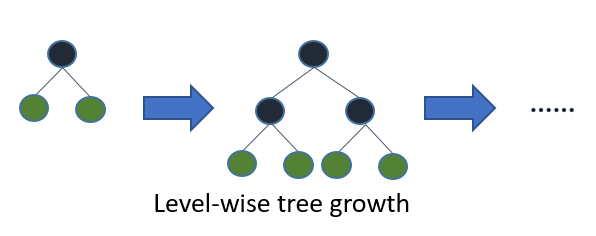
Level-wise过一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。但实际上Level-wise是一种低效的算法,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销,因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。
在Histogram算法之上,LightGBM进行进一步的优化。首先它抛弃了大多数GBDT工具使用的按层生长 (level-wise)
的决策树生长策略,而使用了带有深度限制的按叶子生长 (leaf-wise)算法。
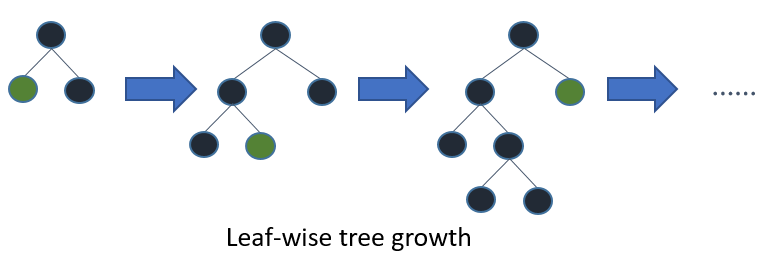
Leaf-wise则是一种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。Leaf-wise的缺点是可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。
1.4 直方图差加速
LightGBM另一个优化是Histogram(直方图)做差加速。一个容易观察到的现象:一个叶子的直方图可以由它的父亲节点的直方图与它兄弟的直方图做差得到。通常构造直方图,需要遍历该叶子上的所有数据,但直方图做差仅需遍历直方图的k个桶。
利用这个方法,LightGBM可以在构造一个叶子的直方图后,可以用非常微小的代价得到它兄弟叶子的直方图,在速度上可以提升一倍。
1.5 直接支持类别特征
实际上大多数机器学习工具都无法直接支持类别特征,一般需要把类别特征,转化到多维的0/1特征,降低了空间和时间的效率。而类别特征的使用是在实践中很常用的。基于这个考虑,LightGBM优化了对类别特征的支持,可以直接输入类别特征,不需要额外的0/1展开。并在决策树算法上增加了类别特征的决策规则。在Expo数据集上的实验,相比0/1展开的方法,训练速度可以加速8倍,并且精度一致。据我们所知,LightGBM是第一个直接支持类别特征的GBDT工具。
2. LightGBM优点
LightGBM (Light Gradient Boosting Machine)(请点击https://github.com/Microsoft/LightGBM)是一个实现GBDT算法的框架,支持高效率的并行训练,并且具有以下优点:
- 更快的训练速度
- 更低的内存消耗
- 更好的准确率
- 分布式支持,可以快速处理海量数据
3. 代码实现
为了演示LightGBM在Python中的用法,本代码以sklearn包中自带的鸢尾花数据集为例,用lightgbm算法实现鸢尾花种类的分类任务。
GitHub:点击进入
作者:@mantchs
GitHub:https://github.com/NLP-LOVE/ML-NLP
欢迎大家加入讨论!共同完善此项目!群号:【541954936】

以上是关于LightGBM,面试会问到的都在这了(附代码)!的主要内容,如果未能解决你的问题,请参考以下文章