Python系列之多线程多进程
Posted Mr.YG
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python系列之多线程多进程相关的知识,希望对你有一定的参考价值。
线程是操作系统直接支持的执行单元,因此,高级语言通常都内置多线程的支持,Python也不例外,并且,Python的线程是真正的Posix Thread,而不是模拟出来的线程。
Python的标准库提供了两个模块:_thread和threading,_thread是低级模块,threading是高级模块,对_thread进行了封装。绝大多数情况下,我们只需要使用threading这个高级模块。
import threading import time def f1(num): time.sleep(1) print("Thread-->%d" % num) if __name__ == \'__main__\': for i in range(10): t = threading.Thread(target=f1,args=(i,)) t.start() #####output##### Thread-->1 Thread-->0 Thread-->2 Thread-->5 Thread-->3 Thread-->6 Thread-->4 Thread-->8 Thread-->7 Thread-->9
多线程方法:
t.start() : 启动线程
t.name() : 设置获取进程名称
t.is_alive(): 检查线程是否存活
t.setDaemon() 设置为后台线程或前台线程(默认:False);通过一个布尔值设置线程是否为守护线程,必须在执行start()方法之后才可以使用。如果是后台线程,主线程执行过程中,后台线程也在进行,主线程执行完毕后,后台线程不论成功与否,均停止;如果是前台线程,主线程执行过程中,前台线程也在进行,主线程执行完毕后,等待前台线程也执行完成后,程序停止
t.isDaemon() : 判断是否为守护线程
t.ident :获取线程的标识符。线程标识符是一个非零整数,只有在调用了start()方法之后该属性才有效,否则它只返回None。
t.join() :逐个执行每个线程,执行完毕后继续往下执行,该方法使得多线程变得无意义
t.run() :线程被cpu调度后自动执行线程对象的run方法
线程的生命周期:
New创建。Runnable就绪。等待调度Running运行。Blocked阻塞。阻塞可能在WaitLockedSleepingDead消亡
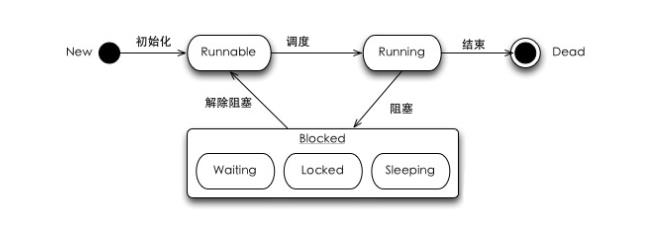
线程中执行到阻塞,可能有3种情况:
同步:线程中获取同步锁,但是资源已经被其他线程锁定时,进入Locked状态,直到该资源可获取(获取的顺序由Lock队列控制)
睡眠:线程运行sleep()或join()方法后,线程进入Sleeping状态。区别在于sleep等待固定的时间,而join是等待子线程执行完。当然join也可以指定一个“超时时间”。从语义上来说,如果两个线程a,b, 在a中调用b.join(),相当于合并(join)成一个线程。最常见的情况是在主线程中join所有的子线程。
等待:线程中执行wait()方法后,线程进入Waiting状态,等待其他线程的通知(notify)。
线程类型:
- 主线程
- 子线程
- 守护线程(后台线程)
- 后台线程
二、线程锁threading.RLock和threading.Lock
多线程和多进程最大的不同在于,多进程中,同一个变量,各自有一份拷贝存在于每个进程中,互不影响,而多线程中,所有变量都由所有线程共享,所以,任何一个变量都可以被任何一个线程修改,因此,线程之间共享数据最大的危险在于多个线程同时改一个变量,把内容给改乱了。看下面的例子:
num = 0 def f1(arg): global num num +=arg num -=arg def f2(num): for i in range(100000): f1(num) t1 = threading.Thread(target=f2, args=(5,)) t2 = threading.Thread(target=f2, args=(8,)) t1.start() t2.start() t1.join() t2.join() print(num)
定义一个全局变量num 并且初始化为0,并且启动两个线程先加后减理论上应该为0 但是,由于线程的调度是由操作系统决定的,当t1、t2交替执行时,只要循环次数足够多,num的结果就不一定是0了。引入锁的概念
import threading import time globals_num = 0 lock = threading.RLock() def Func(): lock.acquire() # 获得锁 global globals_num globals_num += 1 time.sleep(1) print(globals_num) lock.release() # 释放锁 for i in range(10): t = threading.Thread(target=Func) t.start()
threading.RLock和threading.Lock 的区别
RLock允许在同一线程中被多次acquire。而Lock却不允许这种情况。 如果使用RLock,那么acquire和release必须成对出现,即调用了n次acquire,必须调用n次的release才能真正释放所占用的琐。
import threading lock = threading.Lock() #Lock对象 lock.acquire() lock.acquire() #产生了死琐。 lock.release() lock.release()
import threading rLock = threading.RLock() #RLock对象 rLock.acquire() rLock.acquire() #在同一线程内,程序不会堵塞。 rLock.release() rLock.release()
三、Event
python线程的事件用于主线程控制其他线程的执行,事件主要提供了三个方法 set、wait、clear。
事件处理的机制:全局定义了一个“Flag”,如果“Flag”值为 False,那么当程序执行 event.wait 方法时就会阻塞,如果“Flag”值为True,那么event.wait 方法时便不再阻塞。
- clear:将“Flag”设置为False
- set:将“Flag”设置为True
import threading def do(event): print(\'start\') event.wait() print(\'execute\') event_obj = threading.Event() for i in range(5): #创建5个线程并激活 t = threading.Thread(target=do,args=(event_obj,)) t.start() event_obj.clear() #将“Flag”设置为False inp = input(\'input:\') if inp ==\'true\': event_obj.set() #将“Flag”设置为True
四、queue
queue 就是对队列,它是线程安全的。
queue提供了一下方法:
import queue q = queue.Queue(maxsize=0) # 构造一个先进显出队列,maxsize指定队列长度,为0 时,表示队列长度无限制。 q.join() # 等到队列为空的时候,在执行别的操作 q.qsize() # 返回队列的大小 (不可靠) q.empty() # 当队列为空的时候,返回True 否则返回False (不可靠) q.full() # 当队列满的时候,返回True,否则返回False (不可靠) q.put(item, block=True, timeout=None) # 将item放入Queue尾部,item必须存在,可以参数block默认为True,表示当队列满时,会等待队列给出可用位置, 为False时为非阻塞,此时如果队列已满,会引发queue.Full 异常。 可选参数timeout,表示 会阻塞设置的时间,过后, 如果队列无法给出放入item的位置,则引发 queue.Full 异常 q.get(block=True, timeout=None) # 移除并返回队列头部的一个值,可选参数block默认为True,表示获取值的时候,如果队列为空,则阻塞,为False时,不阻塞, 若此时队列为空,则引发 queue.Empty异常。 可选参数timeout,表示会阻塞设置的时候,过后,如果队列为空,则引发Empty异常。 q.put_nowait(item) # 等效于 put(item,block=False) q.get_nowait() # 等效于 get(item,block=False)
五、多进程
python中的多线程其实并不是真正的多线程,如果想要充分地使用多核CPU的资源,在python中大部分情况需要使用多进程。Python提供了非常好用的多进程包multiprocessing,只需要定义一个函数,Python会完成其他所有事情。借助这个包,可以轻松完成从单进程到并发执行的转换。multiprocessing模块提供了一个Process类来代表一个进程对象
创建进程:
from multiprocessing import Process def f(name): # time.sleep(3) print(\'hello\',name) if __name__ =="__main__": p = Process(target=f,args=(\'job\',)) p.start() p.join() #join方法就是阻塞父进程,等待子进程执行完毕
注意:由于进程之间的数据需要各自持有一份,所以创建进程需要的非常大的开销。
进程各自持有一份数据,默认无法共享数据如果想进行共享multiprocessing 提供两种方法Value和Array
六、进程之间的数据共享Value、Array
方法一、Value
from multiprocessing import Process, Value, Array def f(n, a): n.value = 3.1415927 for i in range(len(a)): a[i] = -a[i] if __name__ == \'__main__\': num = Value(\'d\', 0.0) arr = Array(\'i\', range(10)) p = Process(target=f, args=(num, arr)) p.start() p.join() print(num.value) print(arr[:])
输出:
3.1415927
[0, -1, -2, -3, -4, -5, -6, -7, -8, -9]
创建num和arr时,“d”和“i”参数由Array模块使用的typecodes创建:“d”表示一个双精度的浮点数,“i”表示一个有符号的整数,这些共享对象将被线程安全的处理。
Array(‘i’, range(10))中的‘i’参数:


‘c’: ctypes.c_char ‘u’: ctypes.c_wchar ‘b’: ctypes.c_byte ‘B’: ctypes.c_ubyte
‘h’: ctypes.c_short ‘H’: ctypes.c_ushort ‘i’: ctypes.c_int ‘I’: ctypes.c_uint
‘l’: ctypes.c_long, ‘L’: ctypes.c_ulong ‘f’: ctypes.c_float ‘d’: ctypes.c_double
方法二、Array
from multiprocessing import Process, Manager def f(d, l): d[1] = \'1\' d[\'2\'] = 2 d[0.25] = None l.reverse() if __name__ == \'__main__\': with Manager() as manager: d = manager.dict() l = manager.list(range(10)) p = Process(target=f, args=(d, l)) p.start() p.join() print(d) print(l)
输出:
{0.25: None, 1: \'1\', \'2\': 2}
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
七、Pool
程池内部维护一个进程序列,当使用时,则去进程池中获取一个进程,如果进程池序列中没有可供使用的进进程,那么程序就会等待,直到进程池中有可用进程为止。
进程池中有两个方法:
- apply 每一个任务是排队进行默认,进程.join()
- apply_async 每一个任务都并发进行;可以设置回调函数;进程.无join();进程daemon=True
#!/usr/bin/env python # -*- coding:utf-8 -*- from multiprocessing import Pool import time def Foo(i): time.sleep(0.5) return i+100 def Bar(arg): print(arg) if __name__ == \'__main__\': pool = Pool(5) for i in range(10): pool.apply_async(func=Foo, args=(i,),callback=Bar) print(\'end\') pool.close() pool.join()#进程池中进程执行完毕后再关闭,如果注释,那么程序直接关闭。
八、协程
协程存在的意义:对于多线程应用,CPU通过切片的方式来切换线程间的执行,线程切换时需要耗时(保存状态,下次继续)。协程,则只使用一个线程,在一个线程中规定某个代码块执行顺序。
协程的适用场景:当程序中存在大量不需要CPU的操作时(IO),适用于协程;
协程有两个模块分别为greenlet和gevent 其中greenlet为原始的模块而gevent为高级的,在greenlet的基础上进行了封装使用更为方便,可以通过pip3安装gevent也可以源码安装,需要注意安装gevent 的时候需要先安装greenlet。
1 、greenlet实例:
from greenlet import greenlet def test1(): print(12) gr2.switch() print (34) gr2.switch() def test2(): print (56) gr1.switch() print (78) gr1 = greenlet(test1) gr2 = greenlet(test2) gr1.switch() #######output####### 12 56 34 78
2、gevent实例:
import gevent def foo(): print(\'12\') gevent.sleep(0) print(\'34\') def bar(): print(\'56\') gevent.sleep(0) print(\'78\') gevent.joinall([ gevent.spawn(foo), gevent.spawn(bar), ])
遇到IO操作自动切换:
from gevent import monkey; monkey.patch_all() import gevent import requests def f(url): print(\'GET: %s\' % url) resp = requests.get(url) data = resp.text print(\'%s bytes received from %d.\' % (url,len(data))) gevent.joinall([ gevent.spawn(f, \'https://www.python.org/\'), gevent.spawn(f, \'https://www.yahoo.com/\'), gevent.spawn(f, \'https://github.com/\'), ])
九、管理上下文
先看下面的代码:
import queue
li = []
q = queue.Queue()
q.put("wukong")
#
li.append(1)
print(li)
q.get()
li.remove(1)
print(li)
###########output##########
[1]
[]
从上面的例子可以看出q.get()之前往列表里面添加了一个1,然后又移除,说这个例子就是为了引入上下文管理,看下面的代码:
import contextlib
@contextlib.contextmanager #用来处理上下文
def worker_state(xxx,val):
xxx.append(val)
try:
yield
finally:
xxx.remove(val)
#测试
li = []
q = queue.Queue()
q.put(\'wukong\')
with worker_state(li,1):
print(li)
q.get()
print( li)
###########output###########
[1]
[]
首先定义一个函数并且被必须@contextlib.contextmanager 装饰 ,调用的时候 直接with xxx ;worker_state函数执行流程 通过with 进入到函数先xxx添加val 然后到yield 跳出函数,执行q.get,执行完后跳回yield,然后移除val。这就是基础的上下文管理
更多参见上下文管理:https://docs.python.org/2/library/contextlib.html
九、自定义线程池
#!/usr/bin/env python # _*_ coding:utf-8 _*_ #设计理念 队列里面放任务 ,线程一个一个的处理任务 import queue import threading import contextlib import time StopEvent = object() #全局变量,用于停止线程 call 方法里面有体现 class ThreadPool(object): def __init__(self, max_num): self.q = queue.Queue() # 放任务 self.max_num = max_num # 最多创建的线程数(线程池最大容量) self.generate_list = [] # 真实创建的线程列表 self.free_list = [] #空闲线程数量 self.terminal = False def run(self,func,args,callback=None): \'\'\' :param func: 任务函数 :param args: 任务函数所需参数 :param callback: :return: \'\'\' w = (func, args, callback) #封装到一个元祖里 self.q.put(w) #将任务放到队列里 # 创建线程 if len(self.free_list) ==0 and len(self.generate_list) < self.max_num: self.generate_thread() def generate_thread(self): \'\'\' 创建线程 :return: \'\'\' t =threading.Thread(target=self.call) t.start() def call(self): \'\'\' 循环去获取任务函数并执行任务函数 :return: \'\'\' current_thread = threading.currentThread # 获取当前线程 self.generate_list.append(current_thread) #当前线程添加到列表 # 取任务并执行 event = self.q.get() while event != StopEvent: #是任务 func, arguments, callback = event try: restlt = func(*arguments) #执行函数 status = True #表示任务执行成功 except Exception as e: status = False #表示任务执行失败 restlt = e #封装多有错误的信息 if callback is not None: try: callback(status, restlt) # 回调函数 except Exception as e : pass with self.worker_state(self.free_list, current_thread): if self.terminal: #False event = StopEvent else: # 方法一 ,未用上下文管理 # self.free_list.append(current_thread) # event = self.q.get() 有任务取任务,没有任务等待 # self.free_list.remove(current_thread) # 方法二,用上下文管理 event= self.q.get() else: #不是任务,把当前任务从任务列表移除 self.generate_list.remove(current_thread) def close(self): num = len(self.generate_list) #那到线程数 while num: self.q.put(StopEvent) #往队列里放终止符 num-=1 def terminate(self): \'\'\' 调用次方法线程立即停止(清空队列) :return: \'\'\' self.terminal = True while self.generate_list: self.q.put(StopEvent) self.q.empty() # 清空队列 # def terminate(self): # \'\'\' # 调用次方法线程立即停止(不清空队列) # :return: # \'\'\' # self.terminal = True # max_num = len(self.generate_list) # while max_num: # self.q.put(StopEvent) # max_num-=1 # self.q.empty() #清空队列 @contextlib.contextmanager # 用来处理上下文 def worker_state(self,state_list, worker_thread): state_list.append(worker_thread) try: yield finally: state_list.remove(worker_thread) ###测试### def work(i): print(i) pool = ThreadPool(10) for item in range(50): pool.run(work,args=(item,)) pool.close() #执行完关闭 pool.terminate() #立即终止
以上是关于Python系列之多线程多进程的主要内容,如果未能解决你的问题,请参考以下文章