HashMap的扩容机制
Posted mochenghui
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HashMap的扩容机制相关的知识,希望对你有一定的参考价值。
复习散列数据结构之余重新研究了一下Java中的HashMap;本文主要针对:1、HashMap的初始化;2、HashMap的插入;3:HashMap的扩容这三个方面进行总结
1、HashMap的初始化
首先我们来看看代码:
1 public HashMap(int initialCapacity, float loadFactor) 2 if (initialCapacity < 0) 3 throw new IllegalArgumentException("Illegal initial capacity: " + 4 initialCapacity); 5 if (initialCapacity > MAXIMUM_CAPACITY) 6 initialCapacity = MAXIMUM_CAPACITY; 7 if (loadFactor <= 0 || Float.isNaN(loadFactor)) 8 throw new IllegalArgumentException("Illegal load factor: " + 9 loadFactor); 10 this.loadFactor = loadFactor; 11 this.threshold = tableSizeFor(initialCapacity); 12 13 14 /** 15 * 返回一个等于指定容量的2的N次方的容量 16 * Returns a power of two size for the given target capacity. 17 */ 18 static final int tableSizeFor(int cap) 19 int n = cap - 1; 20 n |= n >>> 1; 21 n |= n >>> 2; 22 n |= n >>> 4; 23 n |= n >>> 8; 24 n |= n >>> 16; 25 return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; 26
由此我们可知hashmap的容量总是2的N次方,而且这个值大于且最接近指定值大小的2次幂,比如就算我们指定new hashmap(1000),实际上构造出来的也是:hashmap(1024);
那问题来了:为什么JDK要这样做呢?
要解决这个问题我们需要看看hashmap的是如何找到元素的存放位置的:
1 方法一: 2 static final int hash(Object key) //jdk1.8 & jdk1.7 3 int h; 4 // h = key.hashCode() 为第一步 取hashCode值 5 // h ^ (h >>> 16) 为第二步 高位参与运算 6 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); 7 8 方法二: 9 static int indexFor(int h, int length) 10 //jdk1.7的源码,jdk1.8没有这个方法,取而代之的是在1.8中的putVal()方法中的第3行中: 11 //if ((p = tab[i = (n - 1) & hash]) == null)) 12 //原理都是一样的,作用也是一样的,都是定位元素位置 13 return h & (length-1); //第三步 取模运算 14 ,
看到这里我们自然会问:为什么hash()函数中要用对象的hashcode与自身的高16位进行异或运算(hashcode ^ (hashcode >>> 16))?
这是一个很精妙的设计:
a:其实我们大可以直接用对象的hashcode直接作为下标来存储对象,这个值对于不同的对象必须保证唯一(JAVA规范),这也是大家常说的,重写equals必须重写hashcode的重要原因。但是对象的hashcode返回的是一个32位的int,那这个数组就有40亿左右,大部分情况下我们不需要这么长的数组,我们只需要低位就行,比如只根据低16位创建数组,那数组长度大概就只需要6万多,但是直接创建6万多长度的数组肯定也不合理,而且只取低16位的随机性肯定没有取32位的随机性大,冲突概率也更高,那JDK如何解决的呢?
b:JDK的处理非常巧妙,hashcode ^ (hashcode >>> 16) 该运算是用对象的hashcode与自己的高十六位进行异或运算,这样计算出来的hash值同时具有高位和低位的特性,这样算出来的hash值可以说就是一个增大了低十六位随机性的hashcoede。这样我们试想一下:只要对象的32位hashcode有一位发生了变化,那返回的hash值就会发生变化,更厉害的是不管这发生变化的那一位是高16位还是低16位,最后低十六位都会被影响到,这样也使得后面取模运算下标时所截取的低位的随机性增加,所计算出来的下标更加随机和均匀;
为什么JDK中要用h & (length-1)来计算元素存储位置下标?
计算元素的存放位置,我们首先想到的是根据对象的hash值对数组长度取模,这样元素的分布也还算均匀,但是取模运算效率不算高,所以JDK采用了h & (table.length -1)来得到该对象的保存位,数组长度是2的整次幂时,(数组长度-1)正好相当于一个“低位掩码”,“与”操作的结果就是散列值的高位全部归零,只保留低位值,用来做数组下标访问。以初始长度16为例,16-1=15。2进制表示是00000000 00000000 00001111。“与”操作的结果就是截取了最低的四位值。也就相当于取模操作,而且经过前面的hash()函数的的处理,低位的随机性增加了,所以可知最后运算得到的存储下标也会更加随机更加均匀。
综上:当length = 2^n时,不同的hash值发生碰撞的概率比较小,这样就会使得数据在table数组中分布较均匀,查询速度也较快。
2、HashMap的插入:
1 public V put(K key, V value) 2 return putVal(hash(key), key, value, false, true); 3 4 5 final V putVal(int hash, K key, V value, boolean onlyIfAbsent, 6 boolean evict) 7 Node<K, V>[] tab; 8 Node<K, V> p; 9 int n, i; 10 // 如果表为空则创建,这也体现了hashmap是懒加载的,构造完hashmap之后,如果没有put操作,table是不会初始化的 11 if ((tab = table) == null || (n = tab.length) == 0) 12 n = (tab = resize()).length; 13 // 这一步是根据hash值对数组长度取模,找到元素应该存放的位置, 14 //JDk1.7中把该步骤写成另一个方法,1.8中直接写在此处 15 //如果为空则创建一个节点 16 if ((p = tab[i = (n - 1) & hash]) == null) 17 tab[i] = newNode(hash, key, value, null); 18 //不为空的情况 19 else 20 Node<K, V> e; 21 K k; 22 // 节点已经存在,并且key一样,直接覆盖 23 if (p.hash == hash && 24 ((k = p.key) == key || (key != null && key.equals(k)))) 25 e = p; 26 //判断是否是红黑树 27 else if (p instanceof TreeNode) 28 e = ((TreeNode<K, V>) p).putTreeVal(this, tab, hash, key, value); 29 //执行到这里说明该位置存放的是链表 30 else 31 for (int binCount = 0; ; ++binCount) 32 if ((e = p.next) == null) 33 p.next = newNode(hash, key, value, null); 34 //链表长度大于8转换为红黑树进行处理 TREEIFY_THRESHOLD = 8 35 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st 36 treeifyBin(tab, hash); 37 break; 38 39 // key已经存在直接覆盖value 40 if (e.hash == hash && 41 ((k = e.key) == key || (key != null && key.equals(k)))) 42 break; 43 p = e; 44 45 46 if (e != null) // existing mapping for key 47 V oldValue = e.value; 48 if (!onlyIfAbsent || oldValue == null) 49 e.value = value; 50 afterNodeAccess(e); 51 return oldValue; 52 53 54 ++modCount; 55 // 超过最大容量threshold 就扩容 56 if (++size > threshold) 57 resize(); 58 afterNodeInsertion(evict); 59 return null; 60
3、HashMap的扩容:
有了前面的铺垫,下面理解HashMap的扩容应该不会有太大的困难了:
我们先来看看JDK对扩容函数的注释:
1 /** 2 * Initializes or doubles table size. If null, allocates in 3 * accord with initial capacity target held in field threshold. 4 * Otherwise, because we are using power-of-two expansion, the 5 * elements from each bin must either stay at same index, or move 6 * with a power of two offset in the new table. 7 * 8 * @return the table 9 */ 10 final Node<K,V>[] resize() ...
这段话后面描述到:因为我们使用2的N次幂的扩容机制,所以元素在扩容后的数组中要么是留在原来的下标处,要么是在原位置基础上再移动2的N次幂
这有点费解,我们看一下下面的寻址过程:
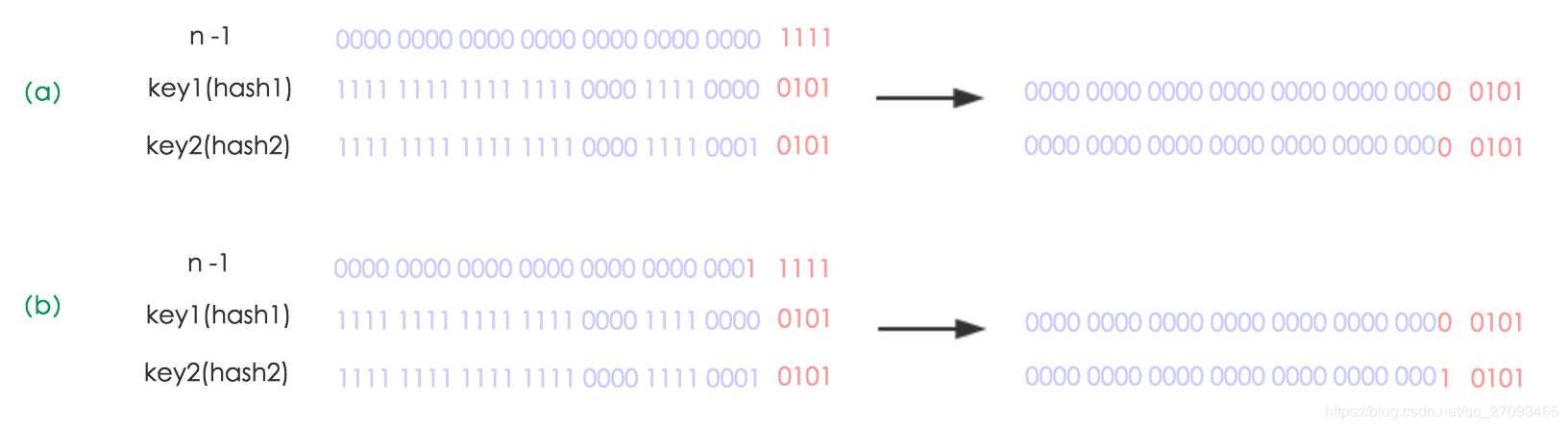
上图的(a)(b)分别对应扩容前和扩容后的hash&(n-1)也就是寻找元素存放位置的过程,可以看到扩容后的n-1相比扩容前的n-1多了一高位1,则再进行&运算时,key1和key2也多了一高位参与运算:
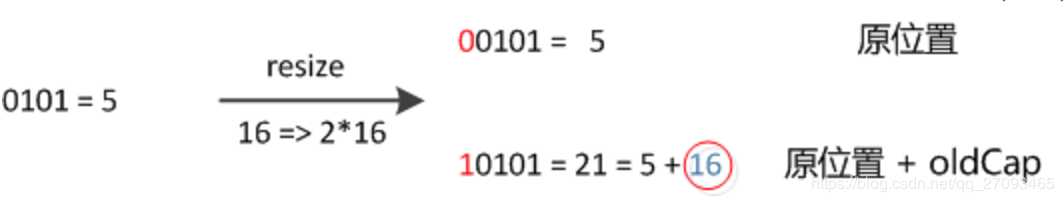
所以,原hash值新增参与运算的的那一bit如果是0,则在新数组中的下标不变,如果原hash值新增参与运算的那一bit是1,则在新数组中的下标为:原索引+原数组容量。
因此现在JDK只需要判断每个元素的hash值新增参与运算的那一bit是1还是0就可以给每个元素确定新数组中的位置,这样做可以巧妙的把原来处于同一个下标索引处的多个元素在新的数组中分散开来,如上面的(a)(b)过程,(a)过程中key1和key2虽然hash值不同,但是运算出了同一个索引值,所以存在同一个位置,但是在(b)过程中由于扩容的影响多了1bit参与运算,所以key1和key2就被分配到了不同的索引处!
下面看看JDK如何实现扩容,真是太巧妙了!
1 final Node<K,V>[] resize() 2 Node<K,V>[] oldTab = table; 3 int oldCap = (oldTab == null) ? 0 : oldTab.length; 4 int oldThr = threshold; 5 int newCap, newThr = 0; 6 if (oldCap > 0) 7 if (oldCap >= MAXIMUM_CAPACITY) 8 threshold = Integer.MAX_VALUE; 9 return oldTab; 10 11 else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && 12 oldCap >= DEFAULT_INITIAL_CAPACITY) 13 newThr = oldThr << 1; // double threshold 14 15 else if (oldThr > 0) // initial capacity was placed in threshold 16 newCap = oldThr; 17 else // zero initial threshold signifies using defaults 18 newCap = DEFAULT_INITIAL_CAPACITY; 19 newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); 20 21 if (newThr == 0) 22 float ft = (float)newCap * loadFactor; 23 newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? 24 (int)ft : Integer.MAX_VALUE); 25 26 threshold = newThr; 27 @SuppressWarnings("rawtypes","unchecked") 28 Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; 29 table = newTab; 30 //移动数据 31 if (oldTab != null) 32 for (int j = 0; j < oldCap; ++j) 33 Node<K,V> e; 34 if ((e = oldTab[j]) != null) 35 oldTab[j] = null; 36 if (e.next == null) 37 newTab[e.hash & (newCap - 1)] = e; 38 else if (e instanceof TreeNode) 39 ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); 40 else // preserve order 41 Node<K,V> loHead = null, loTail = null; 42 Node<K,V> hiHead = null, hiTail = null; 43 Node<K,V> next; 44 do 45 next = e.next; 46 //把元素的hash值与旧的容量做&运算,便可得出元素的hash值 47 //新增的参与运算的那一bit是1还是0 48 //hash&(n-1) 与 hash & n 的区别: 49 //加入n为16,则n-1为:1111 ,n为:10000 50 //n比n-1高了一bit,且因为n为2的n次幂, 51 //所以,hash&n 可以得出扩容后元素hash值多参与运算的那一bit是0还是1 52 //新增参与运算的bit是0,则位置不变 53 if ((e.hash & oldCap) == 0) 54 if (loTail == null) 55 loHead = e; 56 else 57 loTail.next = e; 58 loTail = e; 59 60 //新增参与运算的bit是1,位置变为: 原索引+原数组容量 61 else 62 if (hiTail == null) 63 hiHead = e; 64 else 65 hiTail.next = e; 66 hiTail = e; 67 68 while ((e = next) != null); 69 if (loTail != null) 70 loTail.next = null; 71 //位置不变 72 newTab[j] = loHead; 73 74 if (hiTail != null) 75 hiTail.next = null; 76 //位置变为: 原索引+原数组容量 77 newTab[j + oldCap] = hiHead; 78 79 80 81 82 83 return newTab; 84
第一次写博客,有很多表述可能不是很清楚,望谅解。
以上是关于HashMap的扩容机制的主要内容,如果未能解决你的问题,请参考以下文章