随机森林之oob的计算过程
Posted zhangzhixing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了随机森林之oob的计算过程相关的知识,希望对你有一定的参考价值。
随机森林有一个重要的优点就是,没有必要对它进行交叉验证或者用一个独立的测试集来获得误差的一个无偏估计。它可以在内部进行评估,也就是说在生成的过程中就可以对误差建立一个无偏估计。
随机森铃在生成每颗决策树时,会随机且有放回的抽取样本,每棵决策树会有大概1/3的样本未抽取到,这些样本就是每棵树的oob样本。具体计算过程如下:
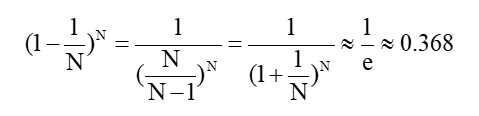
根据这种特点,我们可以对其进行oob估计,步骤如下:
1、计算决策树对其对应的oob样本的分类情况(约有1/3棵树参与oob估计)
2、以投票的方式确定该样本的分类
3、计算oob-error:分类错误的样本数占总样本数的比值
oob误分率是随机森林泛化误差的一个无偏估计,它的结果近似于需要大量计算的k折交叉验证。
以上是关于随机森林之oob的计算过程的主要内容,如果未能解决你的问题,请参考以下文章