ks代码助解
Posted wqbin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ks代码助解相关的知识,希望对你有一定的参考价值。
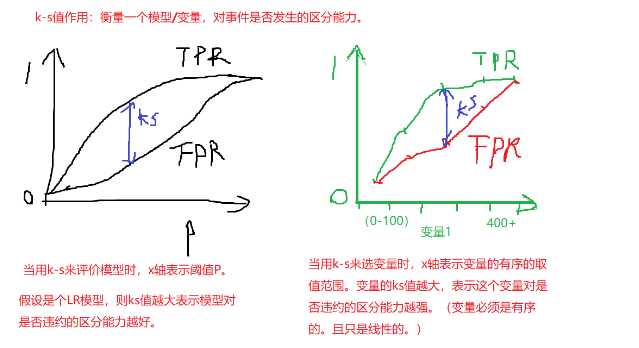
代码实现:
data_test_2 = ‘gd‘:[1,1,1,1,1,1,0,0,0,0,0,0,0],‘score‘:[1,2,0,2,2,7,4,5,4,0,4,18,np.nan] data_test_2 = pd.DataFrame(data_test_2) def ks_calc_cross(data,var_col,y_col): ‘‘‘ 功能: 计算KS值,输出对应分割点和累计分布 输入值:- 输出值: ‘ks‘: KS值,‘crossdens‘: 好坏人累积概率分布以及其差值gap ‘‘‘ ks_df1 = pd.crosstab(data[var_col],data[y_col]) print(ks_df1) print(ks_df1.cumsum(axis=0)) print(ks_df1.sum()) ks_df2 = ks_df1.cumsum(axis=0) / ks_df1.sum() print(ks_df2) ks_df2[‘gap‘] = abs(ks_df2[0] - ks_df2[1]) ks = ks_df2[‘gap‘].max() return ks ks_value = ks_calc_cross(data_test_2, ‘score‘, ‘gd‘) print(ks_value)
gd 0 1 score 0.0 1 1 1.0 0 1 2.0 0 3 4.0 3 0 5.0 1 0 7.0 0 1 18.0 1 0 gd 0 1 score 0.0 1 1 1.0 1 2 2.0 1 5 4.0 4 5 5.0 5 5 7.0 5 6 18.0 6 6 gd 0 6 1 6 dtype: int64 gd 0 1 score 0.0 0.166667 0.166667 1.0 0.166667 0.333333 2.0 0.166667 0.833333 4.0 0.666667 0.833333 5.0 0.833333 0.833333 7.0 0.833333 1.000000 18.0 1.000000 1.000000 0.666666666667
庖丁解牛:
import pandas as pd import numpy as np data_test_2 = ‘gd‘:[1,1,1,1,1,1,0,0,0,0,0,0,0],‘score‘:[1,2,0,2,2,7,4,5,4,0,4,18,np.nan] data_test_2 = pd.DataFrame(data_test_2) data_test_2
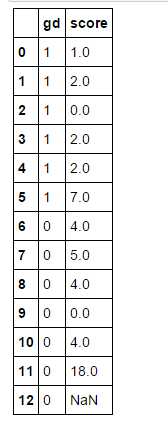
ks_df1 = pd.crosstab(data_test_2[‘score‘],data_test_2[‘gd‘]) ks_df1
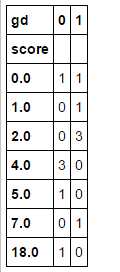
ks_df1.cumsum(axis=0)
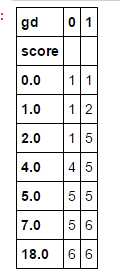
ks_df1.sum()
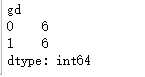
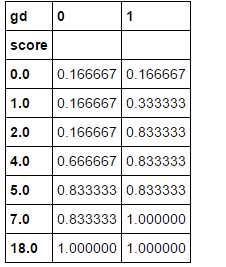
ks_df2 = ks_df1.cumsum(axis=0) / ks_df1.sum()
ks_df2
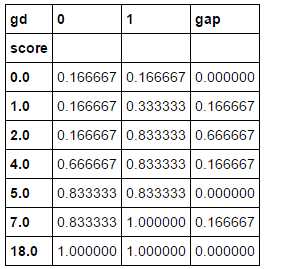
ks_df2[‘gap‘] = abs(ks_df2[0] - ks_df2[1]) ks_df2
ks_df2[‘gap‘].max()
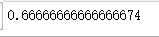
以上是关于ks代码助解的主要内容,如果未能解决你的问题,请参考以下文章