深度学习之迁移学习
Posted ddgjye
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习之迁移学习相关的知识,希望对你有一定的参考价值。
迁移学习概述
背景
随着越来越多的机器学习应用场景的出现,而现有表现比较好的监督学习需要大量的标注数据,标注数据是一项枯燥无味且花费巨大的任务,所以迁移学习受到越来越多的关注。
传统机器学习(主要指监督学习)
- 基于同分布假设
- 需要大量标注数据
然而实际使用过程中不同数据集可能存在一些问题,比如
- 数据分布差异
- 标注数据过期
训练数据过期,也就是好不容易标定的数据要被丢弃,有些应用中数据是分布随着时间推移会有变化。如何充分利用之前标注好的数据(废物利用),同时又保证在新的任务上的模型精度?基于这样的问题,所以就有了对于迁移学习的研究。
概念
迁移学习是把一个领域(即源领域)的知识,迁移到另外一个领域(即目标领域),使得目标领域能够取得更好的学习效果。通常,源领域数据量充足,而目标领域数据量较小,迁移学习需要将在数据量充足的情况下学习到的知识,迁移到数据量小的新环境中。
为什么需要迁移学习:
-
数据的标签很难获取,当有些任务的数据标签很难获取时,就可以通过其他容易获取标签且和该任务相似的任务来迁移学习。
-
从头建立模型是复杂和耗时的,也即是需要通过迁移学习来加快学习效率。
如何进行迁移:
- 基于实例的迁移学习
- 基于特征的迁移学习
- 基于共享参数的迁移学习
- 基于模型的迁移学习
- 基于关系的迁移学习
基于实例的迁移
基于实例的迁移学习研究的是,如何从源领域中挑选出,对目标领域的训练有用的实例,比如对源领域的有标记数据实例进行有效的权重分配,让源域实例分布接近目标域的实例分布,从而在目标领域中建立一个分类精度较高的、可靠地学习模型。
因为,迁移学习中源领域与目标领域的数据分布是不一致,所以源领域中所有有标记的数据实例不一定都对目标领域有用。该方法优点是简单,实现容易,缺点在于权重的选择与相似度的度量依赖经验,且源域与目标域的数据分布往往不同。

基于特征的迁移学习
基于特征选择的迁移学习算法,关注的是如何找出源领域与目标领域之间共同的特征表示,然后利用这些特征进行知识迁移。基于特征映射的迁移学习算法,关注的是如何将源领域和目标领域的数据从原始特征空间映射到新的特征空间中去。优点对大多数方法适用,效果较好。缺点在于难以求解,容易发生过适配。
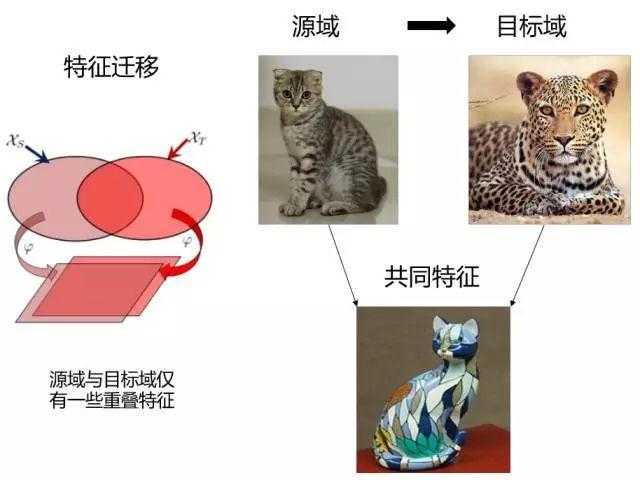
需要注意的的是基于特征的迁移学习方法和基于实例的迁移学习方法的不同是基于特征的迁移学习需要进行特征变换来使得源域和目标域数据到到同一特征空间,而基于实例的迁移学习只是从实际数据中进行选择来得到与目标域相似的部分数据,然后直接学习。
基于共享参数的迁移学习
基于共享参数的迁移研究的是如何找到源数据和目标数据的空间模型之间的共同参数或者先验分布,从而可以通过进一步处理,达到知识迁移的目的,假设前提是,学习任务中的的每个相关模型会共享一些相同的参数或者先验分布。
基于模型的迁移学习
源域和目标域共享模型参数,也就是将之前在源域中通过大量数据训练好的模型应用到目标域上进行预测。基于模型的迁移学习方法比较直接,这样的方法优点是可以充分利用模型之间存在的相似性。缺点在于模型参数不易收敛。
举个例子:比如利用上千万的图象来训练好一个图象识别的系统,当我们遇到一个新的图象领域问题的时候,就不用再去找几千万个图象来训练了,只需把原来训练好的模型迁移到新的领域,在新的领域往往只需几万张图片就够,同样可以得到很高的精度。
基于关系的迁移学习
当两个域是相似的时候,那么它们之间会共享某种相似关系,将源域中学习到的逻辑网络关系应用到目标域上来进行迁移,比方说生物病毒传播规律到计算机病毒传播规律的迁移。这部分的研究工作比较少。典型方法就是mapping的方法。
蚂蚁蜜蜂分类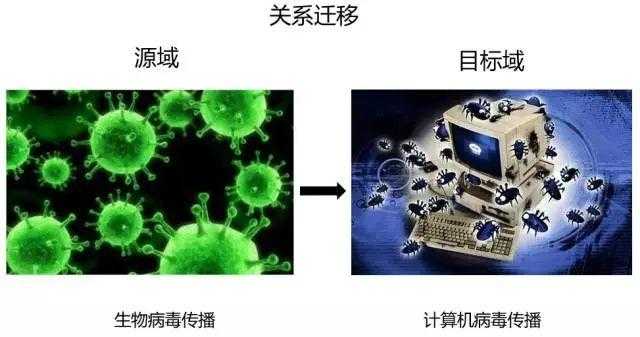
from __future__ import print_function, division import torch import torch.nn as nn import torch.optim as optim from torch.optim import lr_scheduler from torch.autograd import Variable import numpy as np import torchvision from torchvision import datasets, models, transforms import matplotlib.pyplot as plt import time import os import copy plt.ion() # interactive mode data_transforms = ‘train‘: transforms.Compose([ #随机在图像上裁剪出224*224大小的图像 transforms.RandomResizedCrop(224), #将图像随机翻转 transforms.RandomHorizontalFlip(), #将图像数据转换为网络训练所需的tensor向量 transforms.ToTensor(), #归一化处理 transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), ‘val‘: transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), data_dir = ‘hymenoptera_data‘ image_datasets = x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in [‘train‘, ‘val‘] dataloaders = x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4, shuffle=True, num_workers=4) for x in [‘train‘, ‘val‘] dataset_sizes = x: len(image_datasets[x]) for x in [‘train‘, ‘val‘] class_names = image_datasets[‘train‘].classes use_gpu = torch.cuda.is_available() #显示一些图片,以便理解数据增强 def imshow(inp, title=None): """Imshow for Tensor.""" inp = inp.numpy().transpose((1, 2, 0)) mean = np.array([0.485, 0.456, 0.406]) std = np.array([0.229, 0.224, 0.225]) inp = std * inp + mean inp = np.clip(inp, 0, 1) plt.imshow(inp) if title is not None: plt.title(title) plt.pause(0.001) # pause a bit so that plots are updated # Get a batch of training data inputs, classes = next(iter(dataloaders[‘train‘])) # Make a grid from batch out = torchvision.utils.make_grid(inputs) imshow(out, title=[class_names[x] for x in classes]) def train_model(model, criterion, optimizer, scheduler, num_epochs=25): since = time.time() #保存网络训练最好的权重 best_model_wts = copy.deepcopy(model.state_dict()) best_acc = 0.0 for epoch in range(num_epochs): print(‘Epoch /‘.format(epoch, num_epochs - 1)) print(‘-‘ * 10) # Each epoch has a training and validation phase for phase in [‘train‘, ‘val‘]: if phase == ‘train‘: #学习率更新方式 scheduler.step() model.train(True) # Set model to training mode else: model.train(False) # Set model to evaluate mode running_loss = 0.0 running_corrects = 0 # Iterate over data. for data in dataloaders[phase]: # get the inputs inputs, labels = data # wrap them in Variable if use_gpu: inputs = Variable(inputs.cuda()) labels = Variable(labels.cuda()) else: inputs, labels = Variable(inputs), Variable(labels) # zero the parameter gradients optimizer.zero_grad() # forward outputs = model(inputs) _, preds = torch.max(outputs.data, 1) loss = criterion(outputs, labels) # backward + optimize only if in training phase if phase == ‘train‘: loss.backward() optimizer.step() # 计算一个epoch的loss和准确率 running_loss += loss.item() * inputs.size(0) running_corrects += torch.sum(preds == labels.data) #计算loss和准确率的均值 epoch_loss = running_loss / dataset_sizes[phase] epoch_acc = running_corrects / dataset_sizes[phase] print(‘ Loss: :.4f Acc: :.4f‘.format( phase, epoch_loss, epoch_acc)) # 保存测试阶段,准确率最高的模型 if phase == ‘val‘ and epoch_acc > best_acc: best_acc = epoch_acc best_model_wts = copy.deepcopy(model.state_dict()) print() time_elapsed = time.time() - since print(‘Training complete in :.0fm :.0fs‘.format( time_elapsed // 60, time_elapsed % 60)) print(‘Best val Acc: :4f‘.format(best_acc)) # load best model weights model.load_state_dict(best_model_wts) return model #可视化一些模型 def visualize_model(model, num_images=6): was_training = model.training model.eval() images_so_far = 0 fig = plt.figure() for i, data in enumerate(dataloaders[‘val‘]): inputs, labels = data if use_gpu: inputs, labels = Variable(inputs.cuda()), Variable(labels.cuda()) else: inputs, labels = Variable(inputs), Variable(labels) outputs = model(inputs) _, preds = torch.max(outputs.data, 1) for j in range(inputs.size()[0]): images_so_far += 1 ax = plt.subplot(num_images//2, 2, images_so_far) ax.axis(‘off‘) ax.set_title(‘predicted: ‘.format(class_names[preds[j]])) imshow(inputs.cpu().data[j]) if images_so_far == num_images: model.train(mode=was_training) return model.train(mode=was_training) #微调convnet,加载预测模型并重写全连接层 #导入pytorch中自带的resnet18网络模型 model_ft = models.resnet18(pretrained=True) # 修改网络模型的最后一个全连接层 # 获取最后一个全连接层的输入通道数 num_ftrs = model_ft.fc.in_features # 修改最后一个全连接层的的输出数为2 model_ft.fc = nn.Linear(num_ftrs, 2) if use_gpu: model_ft = model_ft.cuda() criterion = nn.CrossEntropyLoss() # Observe that all parameters are being optimized optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9) # 定义学习率的更新方式,每7个epoch修改一次学习率 exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1) visualize_model(model_ft) model_conv = torchvision.models.resnet18(pretrained=True) for param in model_conv.parameters(): param.requires_grad = False # Parameters of newly constructed modules have requires_grad=True by default num_ftrs = model_conv.fc.in_features model_conv.fc = nn.Linear(num_ftrs, 2) if use_gpu: model_conv = model_conv.cuda() criterion = nn.CrossEntropyLoss() # Observe that only parameters of final layer are being optimized as # opoosed to before. optimizer_conv = optim.SGD(model_conv.fc.parameters(), lr=0.001, momentum=0.9) # Decay LR by a factor of 0.1 every 7 epochs exp_lr_scheduler = lr_scheduler.StepLR(optimizer_conv, step_size=7, gamma=0.1) visualize_model(model_conv)
参考博客:https://www.cnblogs.com/jiqibuxuexi/p/8403986.html
https://ptorch.com/news/138.html
以上是关于深度学习之迁移学习的主要内容,如果未能解决你的问题,请参考以下文章