k-means
Posted pacino12134
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了k-means相关的知识,希望对你有一定的参考价值。
聚类算法中最简单高效的。
利用邻近的信息来标注样本的类别。
重点:初始k个质心,重复迭代直到收敛。
欧式空间的样本,使用平方误差和作为目标函数。
1、优点
快,简单,效果还可以,适合高维
2、缺点
受初始质心的影响,k的选取也很关键
3、距离度量
曼哈顿,欧氏距离
4、k的选取
手肘:k越来越接近真实的类别数时,误差会越来越小,k超过真实的类别数时,增加k得到的聚合程度的回报越来越小,误差下降趋于平缓了,这个肘部对应的k值就是真实的聚类数。
计算轮廓系数:簇内样本i到其他样本的平均距离ai,样本i到簇另一簇的样本平均距离bi。
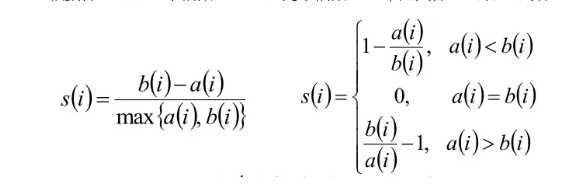
交叉验证:
重复使用数据,训练出不同的模型,选择最优的模型对应的参数
5、kmeans何时停止
迭代次数设置,判定质心移动的距离
6、空聚类
选一个距离当前任何质心最远的点,消除对平方误差影响最大的点;或者找一个替补的质心。
如果噪点或孤立点过多,换算法,密度聚类。
以上是关于k-means的主要内容,如果未能解决你的问题,请参考以下文章