python爬取网页文本图片
Posted -citywall123
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬取网页文本图片相关的知识,希望对你有一定的参考价值。
从网页爬取文本信息:
eg:从http://computer.swu.edu.cn/s/computer/kxyj2xsky/中爬取讲座信息(讲座时间和讲座名称)
注:如果要爬取的内容是多页的话,网址一定要从第二页开始,因为有的首页和其他页的网址有些区别
代码
import pymysql import requests #需要导入模块 db = pymysql.connect(‘localhost‘, ‘root‘, ‘2272594305‘, ‘mysql‘)#第三个是数据库密码,第四个是数据库名称 print("数据库连接成功!") print("---------------------------------------------------") r = requests.get("https://python123.io/ws/demo.html")#获取网页源代码 import re def get_text(url):#函数 r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text def parse_html(url, list): demo = get_text(url) # 将正则表达式编译成正则表达式对象,方便复用该正则表达式 # ".*?" :匹配任意字符串 # [\\u4e00-\\u9fa5] :匹配中文 # (\\d4-\\d2-\\d2) : 匹配日期 #计信院前沿学术报告(2019.7.1)</a></li>\\[(\\d4-\\d2-\\d2)\\] patern = re.compile(‘<li><span\\sclass="fr">\\[(\\d4-\\d2-\\d2)\\]</span>.*? (.*?)</a></li>‘, re.S) results = re.findall(patern, demo) for result in results: list.append(result)#向列表添加对象 return list url = ‘http://computer.swu.edu.cn/s/computer/kxyj2xsky/index.html‘ list = [] for i in range(2,5): url = ‘http://computer.swu.edu.cn/s/computer/kxyj2xsky/index_‘+str(i) + ‘.html‘ list = parse_html(url, list) count = 0 for i in list: count = count + 1 print(i) print("一共有"+str(count)+"条数据!")
输出


数据库连接成功! --------------------------------------------------- (‘2018-11-20‘, ‘计信院前沿学术报告(2018.11-23)‘) (‘2018-11-19‘, ‘计信院前沿学术报告(2018.11-20)‘) (‘2018-11-15‘, ‘计信院前沿学术报告(2018.11-22)‘) (‘2018-11-12‘, ‘计信院前沿学术报告(2018.11-14)‘) (‘2018-11-02‘, ‘第三届全国形式化方法与应用会议暨形式化专委年会(FMAC 2018)即将开幕‘) (‘2018-11-01‘, ‘计信院前沿学术报告(2018.11-06)‘) (‘2018-10-25‘, ‘计信院前沿学术报告(2018.10-31)‘) (‘2018-10-17‘, ‘计信院前沿学术报告(2018.10-19)‘) (‘2018-10-10‘, ‘计信院前沿学术报告(2018.10-17)‘) (‘2018-09-26‘, ‘计信院前沿学术报告(2018.09-29)‘) (‘2018-09-12‘, ‘计信院前沿学术报告(2018.09-18)‘) (‘2018-09-03‘, ‘计信院前沿学术报告(2018.09-04)‘) (‘2018-07-05‘, ‘计信院前沿学术报告(2018.07-05)‘) (‘2018-06-28‘, ‘计信院前沿学术报告(2018.07-02)‘) (‘2018-06-20‘, ‘第7届华人学者知识表示与推理学术研讨会‘) (‘2018-06-19‘, ‘计信院前沿学术报告(2018-06-20)‘) (‘2018-05-15‘, ‘计信院前沿学术报告(2018-05-16)‘) (‘2018-05-07‘, ‘计信院前沿学术报告(2018-05-10)‘) (‘2018-05-02‘, ‘西南大学第三届青年学者含弘科技论坛 计算机与信息科学学院分论坛 学术报告‘) (‘2018-04-16‘, ‘计信院前沿学术报告(2018-04-23)‘) (‘2018-04-09‘, ‘计信院前沿学术报告(2018-04-16)‘) (‘2018-04-04‘, ‘第四届可信软件系统工程(国际)春季学校Spring School on Engineering Trustworthy Software Systems‘) (‘2018-04-02‘, ‘计信院前沿学术报告(2018-04-08)‘) (‘2018-04-02‘, ‘计信院前沿学术报告(2018-04-02)‘) (‘2018-03-27‘, ‘计信院前沿学术报告(2018-03-30)‘) (‘2018-01-09‘, ‘理论计算机科学2018寒假讲习班‘) (‘2018-01-09‘, ‘计信院前沿学术报告(2018-01-11)‘) (‘2018-01-03‘, ‘计信院前沿学术报告(2018-01-05)‘) (‘2017-12-27‘, ‘出国访学(留学)经验交流‘) (‘2017-12-27‘, ‘计信院前沿学术报告(2017-12-28)‘) (‘2017-12-25‘, ‘计信院前沿学术报告(2017-12-28)‘) (‘2017-12-18‘, ‘出国访学(留学)经验交流‘) (‘2017-12-18‘, ‘西南大学第二届青年学者含弘科技论坛 计算机与信息科学学院分论坛 学术报告(二)‘) (‘2017-12-18‘, ‘西南大学第二届青年学者含弘科技论坛 计算机与信息科学学院分论坛 学术报告(一)‘) (‘2017-12-15‘, ‘计信院前沿学术报告(2017-12-28)‘) (‘2017-12-15‘, ‘出国访学(留学)经验交流‘) (‘2017-12-11‘, ‘计信院前沿学术报告(2017-12-13)‘) (‘2017-11-28‘, ‘计信院前沿学术报告(2017-11-28)‘) (‘2017-11-22‘, ‘Third Joint Research Workshop‘) (‘2017-11-06‘, ‘计信院前沿学术报告(2017-11-11)‘) (‘2017-11-06‘, ‘计信院前沿学术报告(2017-11-10)‘) (‘2017-11-06‘, ‘计信院前沿学术报告(2017-11-09)‘) (‘2017-10-29‘, ‘计信院前沿学术报告(2017-10-30)‘) (‘2017-10-25‘, ‘计信院前沿学术报告(2017-10-31)‘) (‘2017-10-19‘, ‘计信院前沿学术报告(2017-10-23)‘) (‘2017-10-17‘, ‘卑尔根-重庆网络化系统暑期学校‘) (‘2017-10-12‘, ‘首届“西南大学重要学术成果”候选成果系列报告‘) (‘2017-09-18‘, ‘出国访学(留学)经验交流‘) (‘2017-09-14‘, ‘计信院前沿学术报告2017-09-15‘) (‘2017-09-06‘, ‘出国访学(留学)经验交流‘) (‘2017-07-05‘, ‘出国访学(留学)经验交流‘) (‘2017-06-21‘, ‘计信院前沿学术报告(2017-06-27)‘) (‘2017-06-21‘, ‘计信院前沿学术报告(2017-06-26)‘) (‘2017-06-12‘, ‘计信院出国访学(留学)经验交流‘) (‘2017-05-27‘, ‘计信院前沿学术报告(2017-06-02)‘) (‘2017-05-24‘, ‘计信院学术研讨会(2017-05-28)‘) (‘2017-05-24‘, ‘计信院前沿学术报告(2017-05-26)‘) (‘2017-05-03‘, ‘西南大学青年学者含弘科技论坛‘) (‘2017-04-13‘, ‘可信软件系统工程(国际)春季学校‘) (‘2017-04-10‘, ‘西南大学计信院前沿学术报告‘) (‘2017-03-31‘, ‘西南大学计信院前沿学术报告‘) (‘2017-03-31‘, ‘西南大学教师参加国际学术会议专题报告会‘) (‘2017-03-29‘, ‘西南大学计信院前沿学术报告‘) (‘2017-03-29‘, ‘西南大学计信院前沿学术报告‘) (‘2017-03-29‘, ‘西南大学计信院前沿学术报告‘) (‘2017-03-28‘, ‘出国访学(留学)经验交流‘) (‘2017-03-16‘, ‘出国访学(留学)经验交流‘) (‘2017-03-15‘, ‘出国访学(留学)经验交流‘) (‘2017-01-10‘, ‘西南大学计信院前沿学术报告‘) (‘2017-01-05‘, ‘学术讲座‘) (‘2017-01-04‘, ‘西南大学计信院前沿学术报告‘) (‘2016-12-20‘, ‘理论计算机科学与形式化方法研讨会‘) (‘2016-12-20‘, ‘西南大学计信院前沿学术报告‘) (‘2016-12-14‘, ‘西南大学计信院前沿学术报告‘) (‘2016-12-12‘, ‘西南大学计信院前沿学术报告‘) 一共有75条数据! Process finished with exit code 0
从网页中爬取图片
eg:从https://maoyan.com/board/4?offset=10中爬取图片,存到位置C:\\Users\\22725\\Desktop\\temp
format 格式控制函数 foramt函数更常见的用法其实是str.format()
示例:
>>>" ".format("hello", "world") # 不设置指定位置,按默认顺序 ‘hello world‘ >>> "0 1".format("hello", "world") # 设置指定位置 ‘hello world‘ >>> "1 0 1".format("hello", "world") # 设置指定位置 ‘world hello world‘
代码:
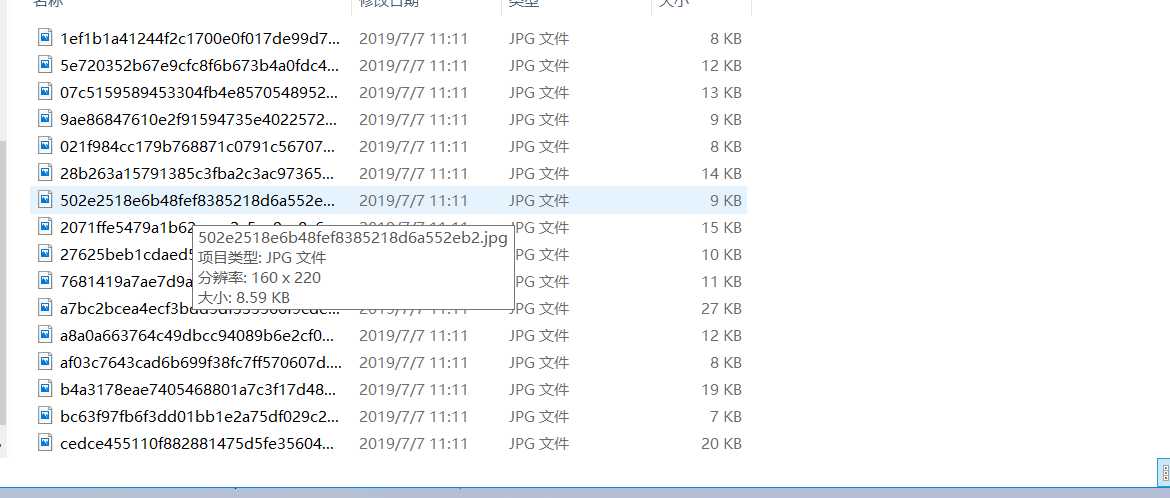
import pymysql import requests from hashlib import md5 import re import os def get_text(url): r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text def parse_html(url, list): demo = get_text(url) # 将正则表达式编译成正则表达式对象,方便复用该正则表达式 # ".*?" :匹配任意字符串 # [\\u4e00-\\u9fa5] :匹配中文 # (\\d4-\\d2-\\d2) : 匹配日期 patern = re.compile(‘img\\sdata-src="(.*?)"\\salt‘, re.S) results = re.findall(patern, demo) for result in results: list.append(result) return list list = [] for i in range(0,2):#左闭右开区间[0,2) url = ‘https://maoyan.com/board/4?offset=‘+str(10*i) list = parse_html(url, list) count = 0 for i in list: count = count + 1 print(i)#输出图片链接 print("一共有"+str(count)+"条数据!") def download_image(url):#保存图片链接 r = requests.get(url) r.raise_for_status() save_image(r.content) def save_image(content):#下载图片 file_path = ‘0/1.2‘.format(‘C:/Users/22725/Desktop/temp‘, md5(content).hexdigest(), ‘jpg‘)#注意斜杠是/ #format(‘文件储存地址‘,哈希算法随机生成子文件名称,‘文件格式‘) if not os.path.exists(file_path):#os.path.exists(file_path)判断文件是否存在,存在返回1,不存在返回0 with open(file_path, ‘wb‘) as f: f.write(content) f.close() for i in list: download_image(i) print("下载成功")
输出:
C:\\Users\\22725\\PycharmProjects\\A\\venv\\Scripts\\python.exe C:/Users/22725/.PyCharmCE2019.1/config/scratches/scratch.py https://p1.meituan.net/movie/[email protected]_220h_1e_1c https://p0.meituan.net/movie/[email protected]_220h_1e_1c https://p0.meituan.net/movie/[email protected]_220h_1e_1c https://p1.meituan.net/movie/[email protected]_220h_1e_1c https://p1.meituan.net/movie/[email protected]_220h_1e_1c https://p0.meituan.net/movie/[email protected]_220h_1e_1c https://p0.meituan.net/movie/[email protected]_220h_1e_1c https://p0.meituan.net/movie/[email protected]_220h_1e_1c https://p1.meituan.net/movie/[email protected]_220h_1e_1c https://p0.meituan.net/movie/[email protected]_220h_1e_1c https://p1.meituan.net/movie/[email protected]_220h_1e_1c https://p1.meituan.net/movie/[email protected]_220h_1e_1c https://p1.meituan.net/movie/[email protected]_220h_1e_1c https://p0.meituan.net/movie/[email protected]_220h_1e_1c https://p1.meituan.net/movie/[email protected]_220h_1e_1c https://p0.meituan.net/movie/[email protected]_220h_1e_1c https://p0.meituan.net/movie/[email protected]_220h_1e_1c https://p1.meituan.net/movie/[email protected]_220h_1e_1c https://p0.meituan.net/movie/[email protected]_220h_1e_1c https://p1.meituan.net/movie/[email protected]_220h_1e_1c 一共有20条数据! 下载成功 Process finished with exit code 0
以上是关于python爬取网页文本图片的主要内容,如果未能解决你的问题,请参考以下文章